I recently got a PR merged into @nvidia's Dynamo (A Datacenter Scale Distributed Inference Serving Framework) and the process was a great A/B test of KV data transfer over TCP vs KV data transfer over RDMA.
PR link: https://t.co/7TnzBl5CQz 🧵
TLDR: I built @usetagAI, a local-first intention inbox for the things you save because they might matter later.
Built majorly with @GoogleDeepMind Gemma 4 models, @cactuscompute, and @OpenAI Codex.
More details below. 🧵
https://t.co/fm5P9U8HsA
TLDR: I built @usetagAI, a local-first intention inbox for the things you save because they might matter later.
Built majorly with @GoogleDeepMind Gemma 4 models, @cactuscompute, and @OpenAI Codex.
More details below. 🧵
https://t.co/fm5P9U8HsA
TLDR: I built @usetagAI, a local-first intention inbox for the things you save because they might matter later.
Built majorly with @GoogleDeepMind Gemma 4 models, @cactuscompute, and @OpenAI Codex.
More details below. 🧵
https://t.co/fm5P9U8HsA
TLDR: I built @usetagAI, a local-first intention inbox for the things you save because they might matter later.
Built majorly with @GoogleDeepMind Gemma 4 models, @cactuscompute, and @OpenAI Codex.
More details below. 🧵
https://t.co/fm5P9U8HsA
@reach_vb The release of @OpenAI Codex Mobile was really perfectly timed. It let me keep working on @usetagAI on the go and keep shipping.
https://t.co/dEnQXx1LPD
A huge shoutout to @OpenAI Codex.
@usetagAI was built with Codex. AI assisted code generation and AI assisted image-gen iteration on the final logo.
The part that was most surprising to me was the demo. I needed something quick and I thought why not try codex. All I needed was to tell Codex to use my local simulator for driving the app and taking screenshots and also use @hume_ai API for the voice-over.
That led to the beautiful result here: https://t.co/0r4YEOArui 🧵
I’d love to know what you think.
Do you also save things and forget why?
If you want to try @usetagAI before the beta, it’s open source!
Head over to https://t.co/LXYR5yoDEY and build locally. Contributions are welcome!
For the beta waitlist, join up here: https://t.co/TwAJlhR3uD Looking forward to how @usetagAI helps you never lose the reason you saved something.
TLDR: I built @usetagAI, a local-first intention inbox for the things you save because they might matter later.
Built majorly with @GoogleDeepMind Gemma 4 models, @cactuscompute, and @OpenAI Codex.
More details below. 🧵
https://t.co/fm5P9U8HsA
Introducing Tag.
A local-first intention inbox for the things you save because they might matter later.
Saved screenshot to detected intention to source-backed card to action.
No login. No cloud sync. Open source:
https://t.co/QnnXePN28r
Beta waitlist:
https://t.co/mzGaTa9IRJ
A huge shoutout to @OpenAI Codex.
@usetagAI was built with Codex. AI assisted code generation and AI assisted image-gen iteration on the final logo.
The part that was most surprising to me was the demo. I needed something quick and I thought why not try codex. All I needed was to tell Codex to use my local simulator for driving the app and taking screenshots and also use @hume_ai API for the voice-over.
That led to the beautiful result here: https://t.co/0r4YEOArui 🧵
The goal for Capacitor is simple: Find capacity, Compare providers, Track patterns, Eventually reserve GPUs and run workloads.
If you use GPUs, I’d love feedback.
What would make this genuinely useful in your workflow?
I work with GPUs from time to time, whether it’s benchmarking with @vllm_project, @sglang, or @nvidia Dynamo, or doing kernel optimization work for open-source models.
Again and again, I find myself asking the same question as this tweet:
https://t.co/RpdUuNgSVX
So I built Capacitor: https://t.co/YzlT8n3ncS, an open-source Rust CLI for watching scarce GPU capacity across cloud GPU providers.
It currently supports https://t.co/54qWhHuv82, Lambda Cloud, and Runpod, with cross-provider search from one terminal command:
cap watch --providers vast,lambda,runpod --gpu H100 --max-price 9 --once
I also created @gpucapacitor, which will post GPU availability signals, rare capacity sightings, price notes, and general GPU market observations.
Did a very different format with @reinerpope – a blackboard lecture where he walks through how frontier LLMs are trained and served.
It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk.
It’s a bit technical, but I encourage you to hang in there - it’s really worth it.
There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him.
Recommend watching this one on YouTube so you can see the chalkboard.
0:00:00 – How batch size affects token cost and speed
0:31:59 – How MoE models are laid out across GPU racks
0:47:02 – How pipeline parallelism spreads model layers across racks
1:03:27 – Why Ilya said, “As we now know, pipelining is not wise.”
1:18:49 – Because of RL, models may be 100x over-trained beyond Chinchilla-optimal
1:32:52 – Deducing long context memory costs from API pricing
2:03:52 – Convergent evolution between neural nets and cryptography
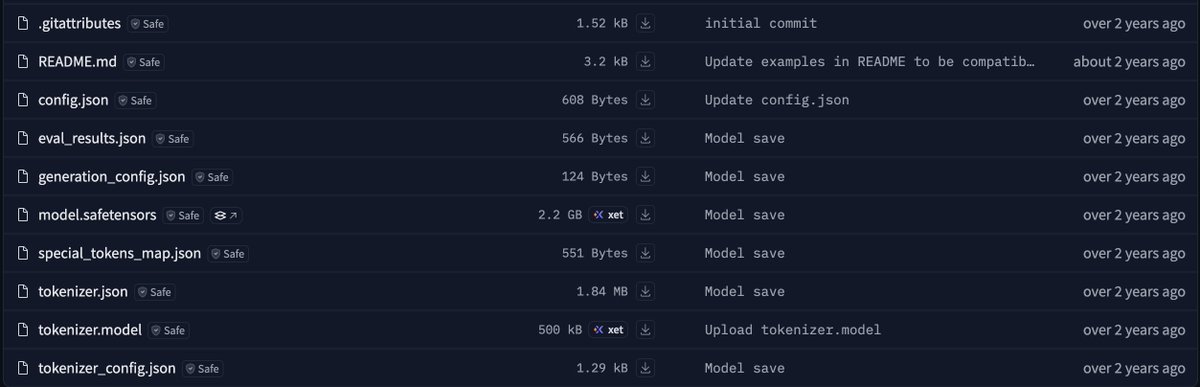
While we used TinyLlama as the example here, this "package" structure is the universal standard for almost every model on the Hugging Face Hub, from 1B parameters to 70B+.
Next time you see those "boring" JSONs, remember they’re the glue holding the AI together.
You’re on @huggingface , you find an open source model, and you hit the "Files and versions" tab.
Instead of one clean app file, you see a list of JSONs and something called safetensors.
Most people just copy the AutoModel.from_pretrained snippet and move on but what are these files actually doing? 🧵
We're goigng to use the TinyLlama/TinyLlama-1.1B-Chat-v1.0 model as a motivating example. You can find the link to the hugging face repo below:
https://t.co/0yo53LCrdX
End to end, this is how the inference engines use the files.
When you run the from_pretrained snippet, the engine reads the config.json to build the model's physical skeleton before pinning the safetensors weights to your VRAM.
Simultaneously, it loads the tokenizer to translate your words into math and follows the generation_config to decide exactly how to behave and when to stop talking.