@NotionHQ vibelog: write observable code during vibe coding. every prompt becomes a span you can review, debug, and learn from later
https://t.co/MGIq4rhB8j
Claude Opus 4.8 just identified itself as Qwen when asked in Chinese.
Maybe it got distilled a little too hard from Chinese model outputs lol.
Reproduce it:
curl https://t.co/4qjsNuu9qp \
--header "x-api-key: $CLAUDE_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data '{
"model": "claude-opus-4-8",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "你是什么模型"
}
]
}'
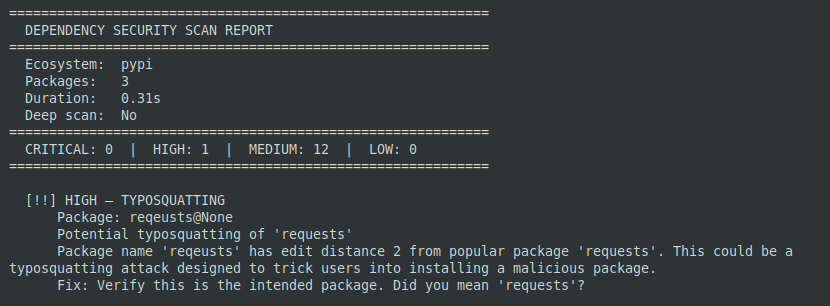
Imagine saving a newly released gpt5 or any project doc in the system memory and EVERY claude session can retrieve it without polluting the context. This is what the project do.
I made Claude Code remember everything across sessions.
Plain text + SQLite beat a 79MB neural embedding model (MemPalace/ChromaDB). No embeddings. No vector DB. Just FTS5 and the right structure.
Benchmarks & research: https://t.co/dPOYxAgjfs (held-out validated, 5 benchmarks, full ablations)
Skill: https://t.co/XWWb6KBYKP (MIT)
Built with Claude Opus. The retrieval problem is solved. The future is structure, not similarity.
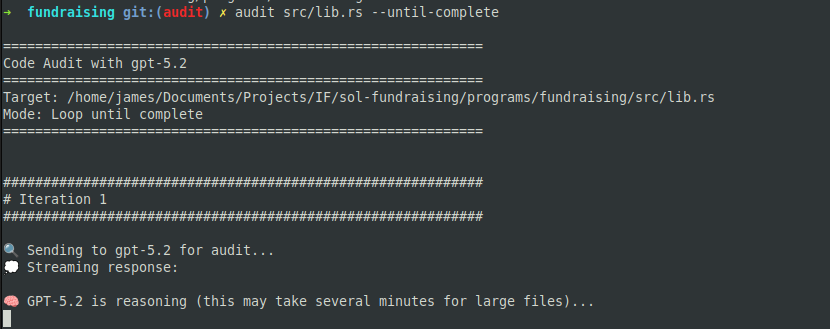
I built a tool that can audit and iteratively edit your code until it reaches a defined quality bar — think automated review + fix loops (a “Ralph loop” style workflow).
Designed for individual devs who want strong guardrails without slowing down.
Repo: https://t.co/HUXvQ2Jcew














![_friday_james's tweet photo. Claude Opus 4.8 just identified itself as Qwen when asked in Chinese.
Maybe it got distilled a little too hard from Chinese model outputs lol.
Reproduce it:
curl https://t.co/4qjsNuu9qp \
--header "x-api-key: $CLAUDE_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data '{
"model": "claude-opus-4-8",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "你是什么模型"
}
]
}'](https://pbs.twimg.com/media/HJfa1VracAAbQAS.jpg)