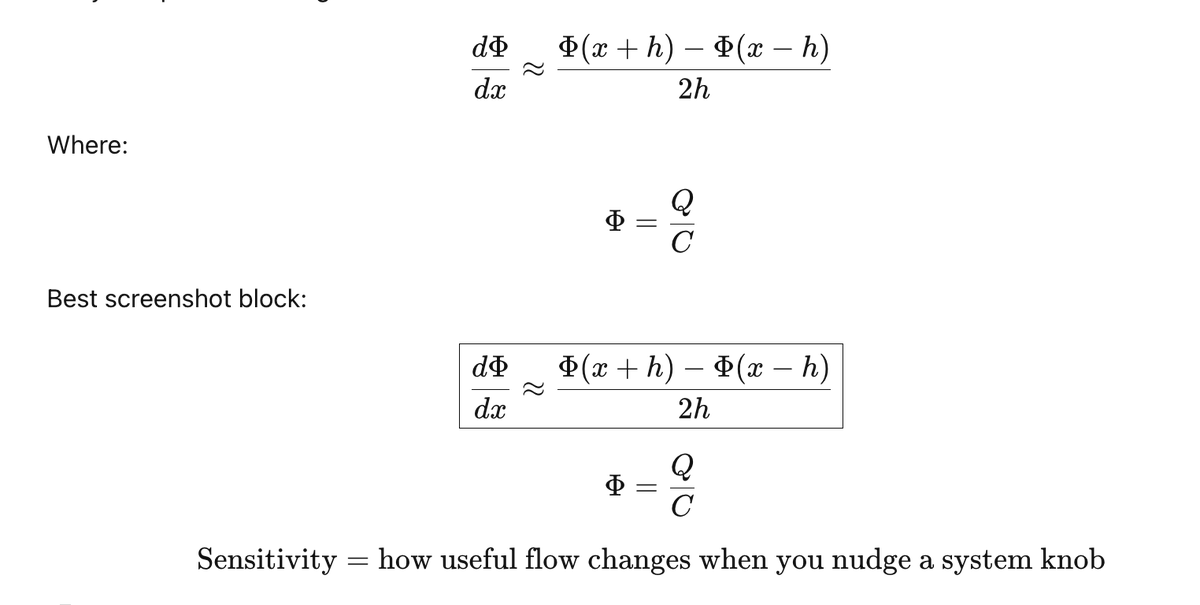i may have improved rocket landing. by accident.
was optimizing ai model systems (max value per cost) and it turned out to be the same convex program g-fold uses to land rockets. thrust→config, fuel→cost, pad→optimum.
same skeleton, relabeled 👇
https://t.co/ZmL8TYDNYB
giving up isn't really a failure, it's the model knowing when to stop. the real fail is shipping a confident wrong fix, and that barely changed. so it just got more careful, not worse.
also the budget's probably unfair, the distilled one thinks longer so it gets cut off before it finishes. give it more room and i bet it catches up.
Btw context here https://t.co/sKic98Udm5
Some of us have been solving a problem which made no sense, but with llm's it looks like we were a whole generation ahead
This is the part people miss.
A good LLM shouldn’t just answer the question.
It should understand why the question was asked, use that to improve the output space, and move the user closer to the level required to solve the next problem.
That’s the real moat:
not giving answers,
equalizing intelligence while the system itself keeps going up.
A lot of AI/software work right now is just changing parts and hoping the metric moves.
Prompt changed.
Model changed.
Context changed.
Tool changed.
Retry policy changed.
Sensitivity analysis asks the better question:
what is the system actually sensitive to?
That’s where the leverage is.
Which knob moves useful output per cost?
dropping some stuff soon
Went on a small SciML side quest.
Saw something interesting around physics + neural nets and wanted to see what my composable-model-graph library could do with the simpler version.
Tiny inverse problem:
recover a hidden physical parameter from noisy measurements.
No neural net, no autodiff.
Not replacing PINNs either. Different shape of problem.
But when a forward model exists, it’s pretty cool how far you can get with an inspectable graph + finite-difference sensitivity.
Example link in comment.
Setting up personal one-person research infra.
Already spent around $2k of my own money on research this week, but the outcomes are interesting enough that I’m doubling down.
Plan is to own as much of the stack as possible:
personal git server, local AI, self-hosted research machines, model weighhts, private experiment infra.
This private repo is part of it: Tower.
These graphs look like this because they have to.
I can’t afford the cognitive cost of keeping systems of this size in my head, and code hides too much.
So I visualize the system and work from there. Let anthropic know they cant stop me (jk)
The annoying thing about export controls is that they are not completely fake.
Forget the generic “China” discourse for a second.
If you give Mossad access to Fable 5, they finna cook something diabolical.
That is just reality, and it has to be handled.
But that is a CIA / NSA / MI6 / national-security problem. It should be handled properly with targeted collaboration between governments and AI labs.
It should not become a blanket policy that impacts literally everyone else on the planet.
You do not need to nerf the entire model for everyone.
That hurts the training data, hurts useful research, and makes the product worse for normal users trying to build normal things.
The intelligence agencies can absolutely spin up new departments to track bad actors abusing LLMs.
They have actual geniuses at DARPA, the CIA, NSA, MI6, etc.
They do not need model companies to sandbag the product for everyone on Earth just to deal with bad actors.
They can handle targeted national-security problems with targeted national-security systems.
Everyone can win here.
The only problem is that LLM companies also seem to want to reign supreme.