Ka1zen — chat with open LLMs 100% offline on your Mac.
🧠 Qwen, Gemma, DeepSeek, Mistral, Llama…
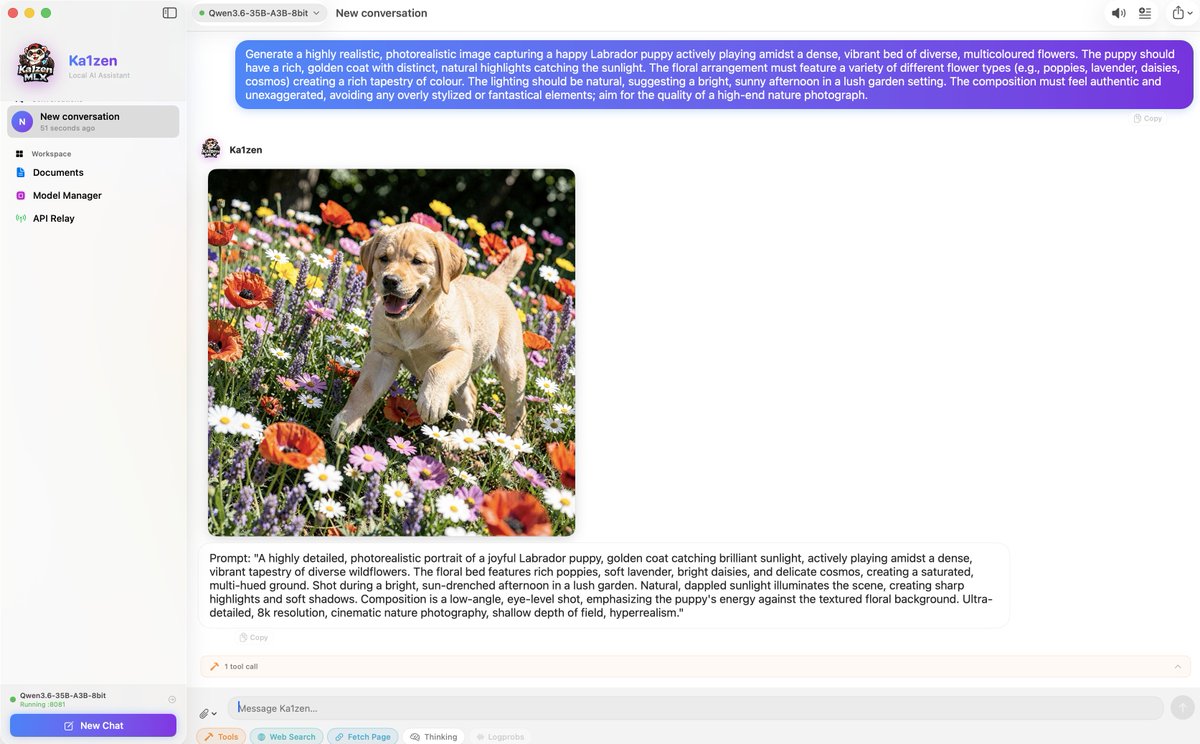
🖼 Vision · 🎙 Audio · 🌐 Web search
🎨 FLUX image generation · 📚 RAG
🔒 Zero cloud, zero telemetry
Powered by Apple MLX.
https://t.co/7lOijJotiB
Excellent, big valid update, now I'm switching to full MTP support associated with real use cases, not marketing benchmarks (Websearch, tools, offline prompt, image generation, code)...
@bridgemindai You can't compare a single machine (even a powerful one) to a high-performance server farm.
In my view, local models are designed to serve individuals, not businesses; otherwise, you'd need servers or more machines.
Ka1zen v0.3.43 — both your asks landed :
– Help → Check now opens the banner (no more popup duplication)
– Auto-installer cleans up the DMG after relaunch
Plus : Favourites section in the model picker + colorised Update prerequisites log with collapsed pip noise
When mlx-lm is updated by @ml_explorer , I will test the implementation, in Ka1zen, of the following models:
- Ling-2.6-flash-mlx-4bit-DWQ
- DeepSeek-V4-Flash-2bit-DQ
I'm working on implementing Qwen-Image-Edit!
This will allow Ka1zen to offer two complete image generation and editing solutions.
- Flux2.Klein
- Qwen Family - Qwen Image and Qwen Image Edit
@jun_song My testing protocol with Ka1zen is simple: never trust benchmarks. Always test under real-world conditions, on real-world use cases. If it works correctly, then I implement it; otherwise, I forget about it.