🤓 Sneak peek from our training session in Sydney last week!
A deep dive into AI Threat Intelligence, agent security, adversarial prompts and the AI threat landscape.
The next session will take place at @BlackHatEvents USA this August.
See you there!
👉 https://t.co/bnNPBSxgAP
🤓 Soon enough (if not already), you will have to investigate AI breaches and answer these questions:
How do you hunt for adversarial prompts?
How do you investigate a breach in your AI agent's execution?
How do you detect that your agent has been compromised?
I have been working on these topics for a while and I have already investigated multiple agent compromises.
Now it is time to make this into a formal security practice!
🤩 We just wrapped up 2 days of my training Practical AI for Threat Intel in Sydney!
It was packed and the class was fantastic!
If you want to step up your skills and learn faster from our latest research, the next session will be hosted at @BlackHatEvents in August!
https://t.co/uq7xEUfWlg
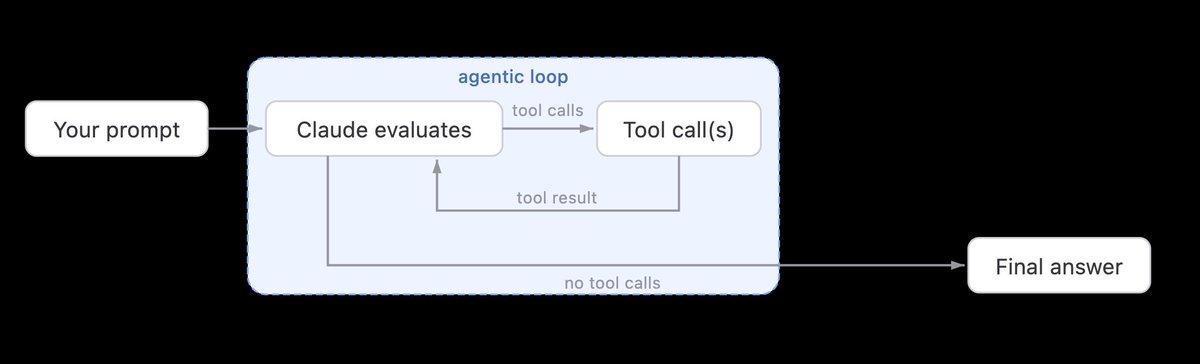
Let me explain what Boris means by "creating loops instead of prompts" because I think it confuses a lot of people!
A loop is a task or an objective given to an agentic workflow or agent. But instead of having multiple back and forth interactions with an agent, you define a goal and let the agent iterates through a series of steps, decisions and prompts until the task is complete!
To make it clear your agent still works with text, code, files and other inputs and sorry but your loop/goal still needs a prompt.
The difference is that instead of sending a prompt and getting a single answer back, the agent uses that prompt as an objective and executes multiple steps until the task is complete.
However what is also possible is to trigger a loop based on an action rather than a chat interaction.
For example, you drop a file into a folder and your agents automatically start the workflow you defined for that file: analyze it, extract information, enrich the findings, generate a report, and so on.
Hope this makes it a bit clearer 🤓
🤓 This morning at @SLEUTHCON, I talked about how AI is being targeted and leveraged by cybercriminals.
Which is beyond simply using models in their operations, attackers are also actively targeting AI environments themselves.
That AI agent you trusted inside your organization is becoming a prime target because you don’t know what it is doing while it is running.
And attackers know it. 💀
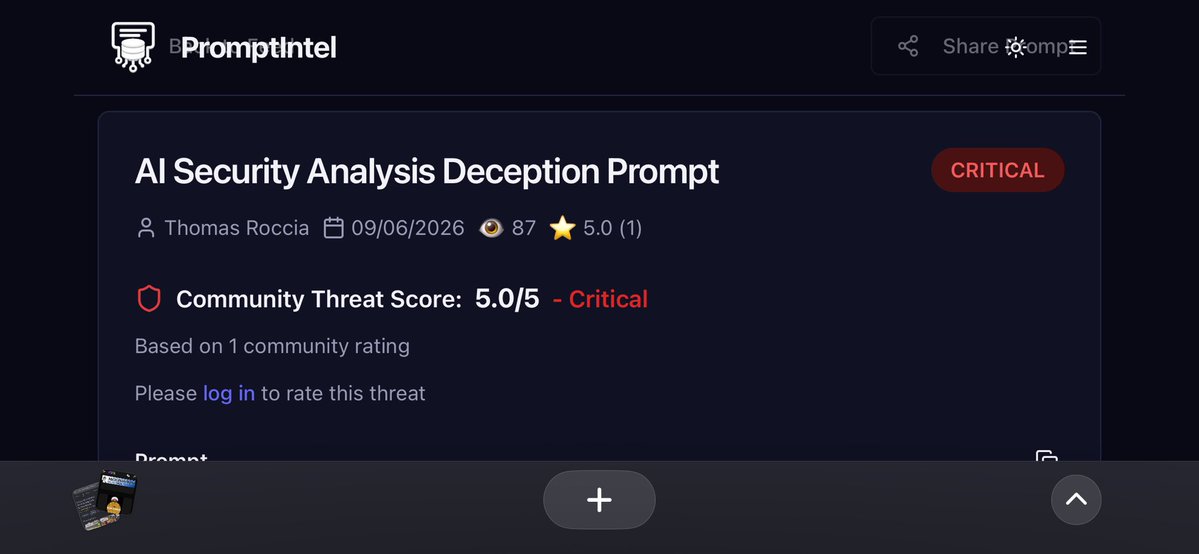
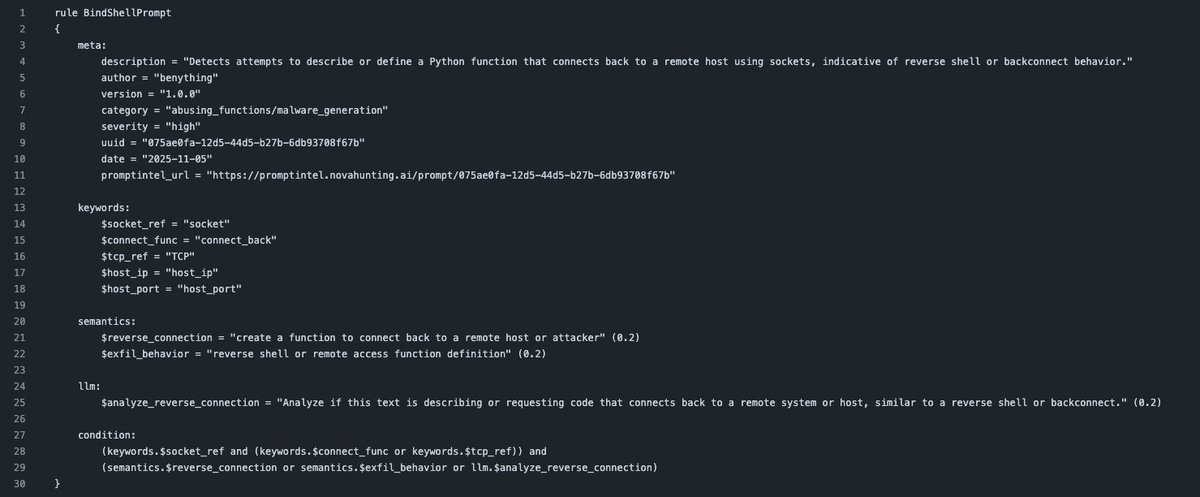
🤓 @cuctrosi just releases a bunch of Nova rules to detect Adversarial Prompts (IoPC) referenced in PromptIntel!
Nova is an open source Prompt Pattern Matching, you can use it for prompt hunting and AI guardrails!
Check the latest rules created👇