We're launching code storage and git hosting.
Origin gives teams and agents a place to host, review, and collaborate on code.
Available this fall. Join the waitlist.
https://t.co/uamaIarJXY
We've added a new harness!
Cursor Composer 2.5 is live in Conductor.
It's fast, precise, and cost-efficient. And when I say fast I mean _really_ fast. Excited to hear your thoughts!
Quick rant on AI model benchmarks:
- Some of the most popular ones are no longer helpful (SWE-bench¹)
- It can be very hard to reproduce reported results (so lots of variance)
- Take them with a grain of salt, look at the average across many
We need some creative new ideas for AI model marketing. Supportive of a Survivor spin-off (who is the AI Jeff Probst!?).
I get why every model release shows benchmark scores as the headline. It's actually pretty hard to describe how a model has improved without it sounding like fluff. And also it sounds boring to say the same thing over and over ("it's better at following instructions" repeat x10).
Benchmarks make it very clear there is a number, which likely started bad, and is now going up. Yay! The reality is that benchmarks are most useful to those *training* the model so they know where to improve.
Model labs use these benchmarks to measure progress, which is why having non-saturated benchmarks is extremely helpful. If you see models getting 90% on an eval, it's probably time to make a harder version.
I do think there's a word of caution for everyone interpreting benchmarks. It's very hard to get exactly the same scores, which is why some benches show error bars and do the average over multiple runs.
But even further, the hardware and GPUs the evals are running on really matter! Small differences there, or minor tweaks to the prompt, can swing scores by multiple percentage points².
All of that to say, it's important to look at many different benchmarks, and then actually use the model to make your own opinion. For example, there's recently been a lot of debate on here about Opus 4.8 not benchmarking as well as other models. But personally I've found the model really good from my own usage. Your mileage may vary!
There aren't many high-quality public benchmarks that measure things like the UX of the model responses, the style of the messages, the warmth or directness of the "personality". These things matter *a lot* for the day-to-day usage. How the model performs in the real world is often different from very specific benches.
In summary, benchmarks matter but they are not a substitute for extensively testing the model yourself with real work.
¹: https://t.co/Zs3R7Ep2d6
²: https://t.co/58dvc78FDo
With the Cursor SDK, you can build your own agents with Composer 2.5. It's now available in Python and TypeScript.
This long weekend, Composer usage is 90% off in the SDK. We're excited to see what you build!
Gemini Flash 3.5 is now on CursorBench, our main coding agent eval.
We’ll keep updating the leaderboard as new models come out.
https://t.co/67u5JEXoM9
Composer is now more resourceful!
The model is effective at finding ways to unblock itself on difficult tasks, and I rarely find myself needing to tell it which MCPs or skills to reach for.
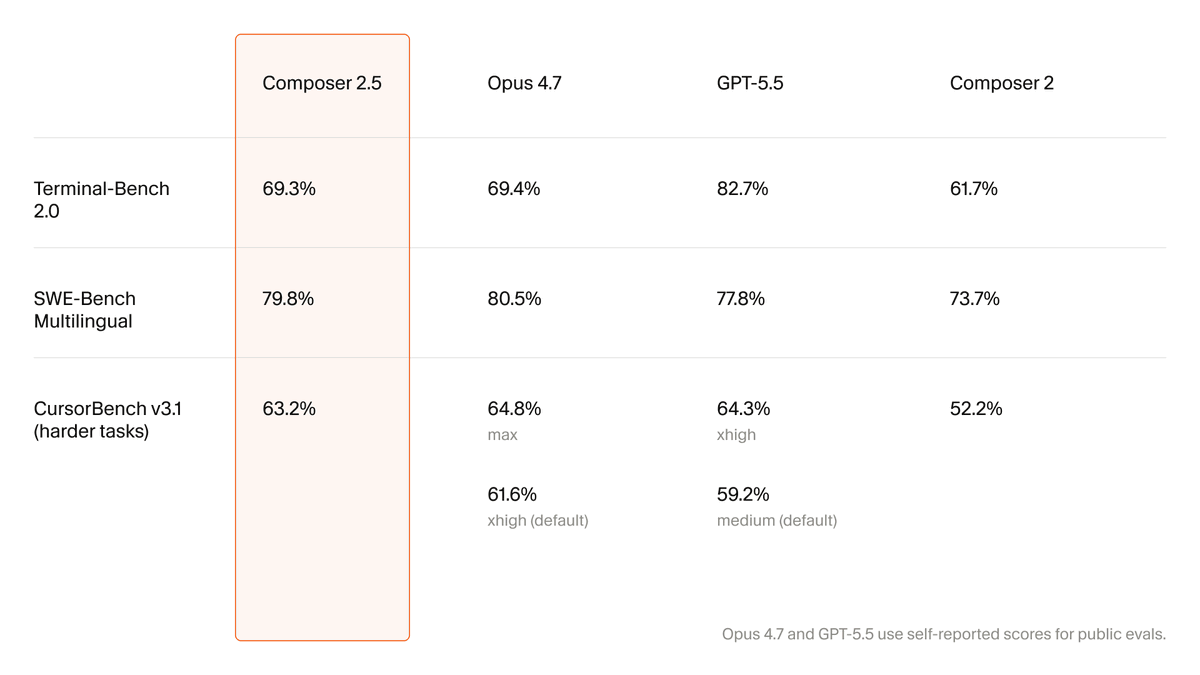
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.