Here's an animation of a @PyTorch DataLoader.
It turns your dataset into a shuffled, batched tensors iterator.
(This is my first animation using @manim_community, the community fork of @3blue1brown's manim)
Here's a little summary of the different parts for those curious:
1/5
Models used to learn by reading. Now they learn by doing. The training loop for agentic AI requires execution.
CoreWeave Sandboxes is the execution layer, on your existing compute or serverless through @wandb.
👏 Watch the demo from @deok_filho.
https://t.co/WfIrLx8DWU
When it comes to observability for agents, regular application tracing doesn't cut it. We need tools that understand the specific semantics of agents (multi-turn sessions, tool calls, long context, etc.).
This is what we built the new Weave for. Agent-first observability and automated detection of agent misbehavior via Signals.
Public preview today, 7 integrations with popular harnesses and SDKs.
Go build, control your agents.
I’m so excited to see this launch (while I’m on paternity leave 👶)!
Lots of people are moving away from agent frameworks and building on top of existing agent harnesses like Claude code, etc.
This makes it easier to track and quickly navigate across theses kinds of multi-turn agent sessions, debug errors, find patterns and build evaluations.
Now back to nappies for me. Sorry to my fellow Europeans for committing the sacrilege of working, however minor, while on leave 🙇♂️
A brand new W&B Weave is live!
It watches production agents end to end, flags failure modes on its own, runs a full loop from inference to training, and blocks regressions.
You can finally watch how your agent thinks across millions of traces instead of squinting at one. 🫡
A brand new W&B Weave is live!
It watches production agents end to end, flags failure modes on its own, runs a full loop from inference to training, and blocks regressions.
You can finally watch how your agent thinks across millions of traces instead of squinting at one. 🫡
The rumors are true 👀
Proud of the CoreWeave engineering team and our partners (like @Dell) who are the first to have a fully working @nvidia Vera Rubin NVL72, achieving yet another major milestone in bringing next-generation AI infrastructure online.
Stay tuned, there is so much more to come...
AI agents fail in production when training data misses real-world edge cases.
We’re closing the loop. CoreWeave connects training & inference so agents continuously improve from live experience. Powered by Serverless RL (40% cost cut, 1.4x faster) & @wandb observability.
https://t.co/BZdU0OqnwC
The W&B MCP server is officially LIVE!
Coding agents could always read your code. Now they can read your experiments, monitor training, and drive their own research loops.
20 tools, hosted on every W&B deployment, plugs into Claude Code, Cursor, Codex, Gemini-CLI, and LeChat.
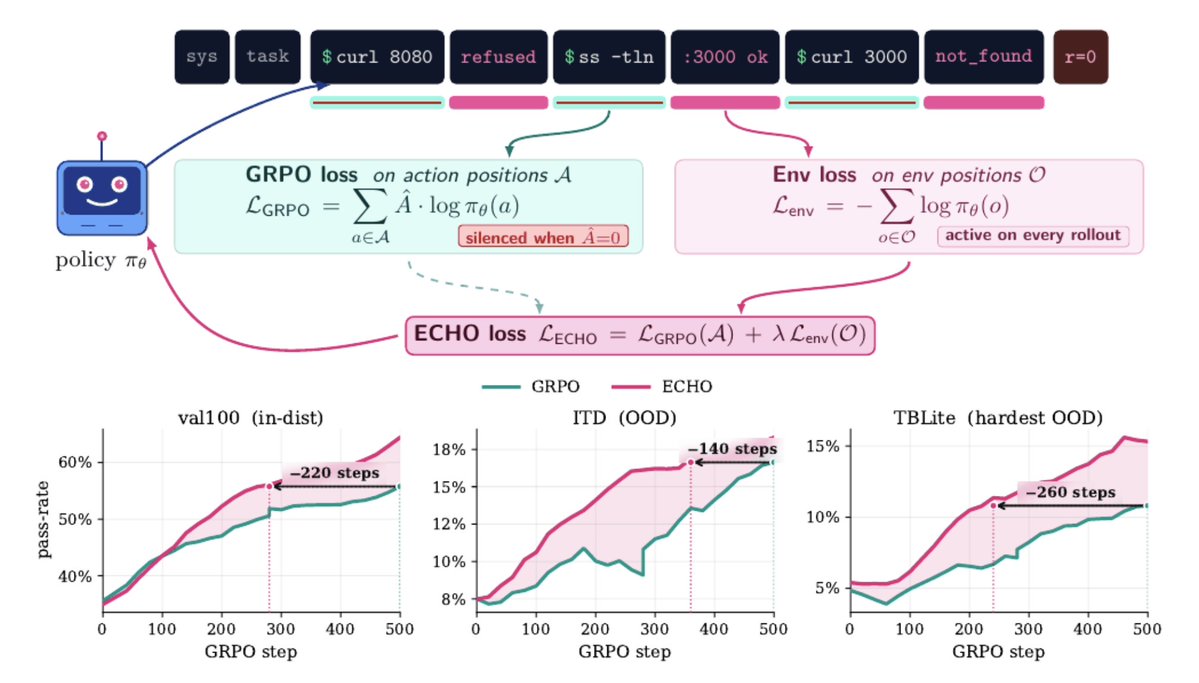
Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models.
ECHO is one of those
Introducing CoreWeave Sandboxes, now in public preview.
It's the execution layer for RL, agent tool use, and model evaluation, on your own CKS clusters or serverless through @wandb.
Get the details: https://t.co/Ha3jISs7Ob
Introducing: CoreWeave Sandboxes 🚀
Running RL and agents means executing model-generated code on isolated environments.
Demand has exploded, leaving many scrambling for CPUs.
The solution: Run tens of thousands of sandboxes on your own CoreWeave compute, even alongside SUNK!
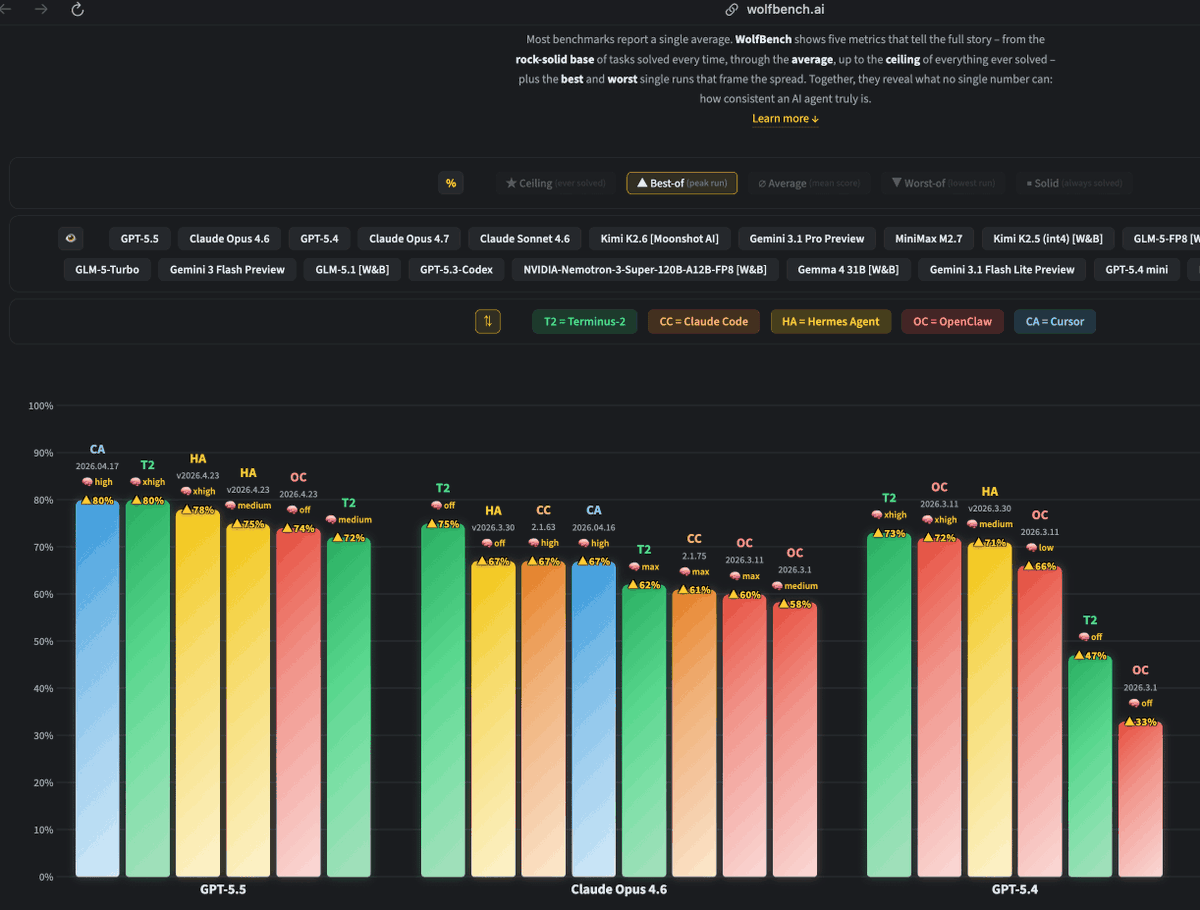
Can confirm, @cursor_ai is the best harness we've tested on @WolfBenchAI so far!
@WolframRvnwlf tests Harness x Model, and Cursor (before the SDK) is the best one we've ever tested!
For benchmarks, I keep agent versions stable so results stay comparable. But new models can expose agent-side bugs. Here, updating @openclaw from 2026.3.11 to 2026.4.23 lifted Kimi K2.6 from 4% to 60% on @WolfBenchAI due to crucial fixes in how the agent handles its tool calling.
GPT-5.5 takes over WolfBench! It’s now the #1 model, ahead of Claude Opus 4.7 and 4.6, GPT-5.4, Sonnet 4.6, Kimi K2.6, Gemini 3.1 Pro, and more.
Notable findings after 30 runs (40h runtime, >1.7B tokens, ~$3K cost):
- @OpenAI's GPT-5.5 is the best model we ever tested.
- @cursor_ai's Agent CLI (CA) is the best agent we ever tested.
- @NousResearch's Hermes Agent (HA) outperformed OpenClaw (OC).
- With Hermes, going from medium to xhigh reasoning only improved consistency, not capability.
Note: This is WolfBench, where we look at more than just the average score, because one metric is not enough. The golden ∅ score is the actual 5-run average, which most other benchmarks report as their only score. ★ shows the ceiling (what percentage of the full benchmark this model+agent combination solved at least once across all runs). ■ shows the solid base (what percentage of the full benchmark it solved consistently in every run).
Still feels a little unreal that you can just upload a dataset, get a fine-tuned LoRA back, and have it auto-deployed for inference without touching a single GPU config.
Serverless SFT is still in public preview and adapter training is free right now. Don't sleep on it.
Today we open sourced many of OpenAI's monitorability evaluations. We hope that the research community and other model developers can build upon them and use them to evaluate the monitorability of their own models.
https://t.co/xFeZ0hbLZG