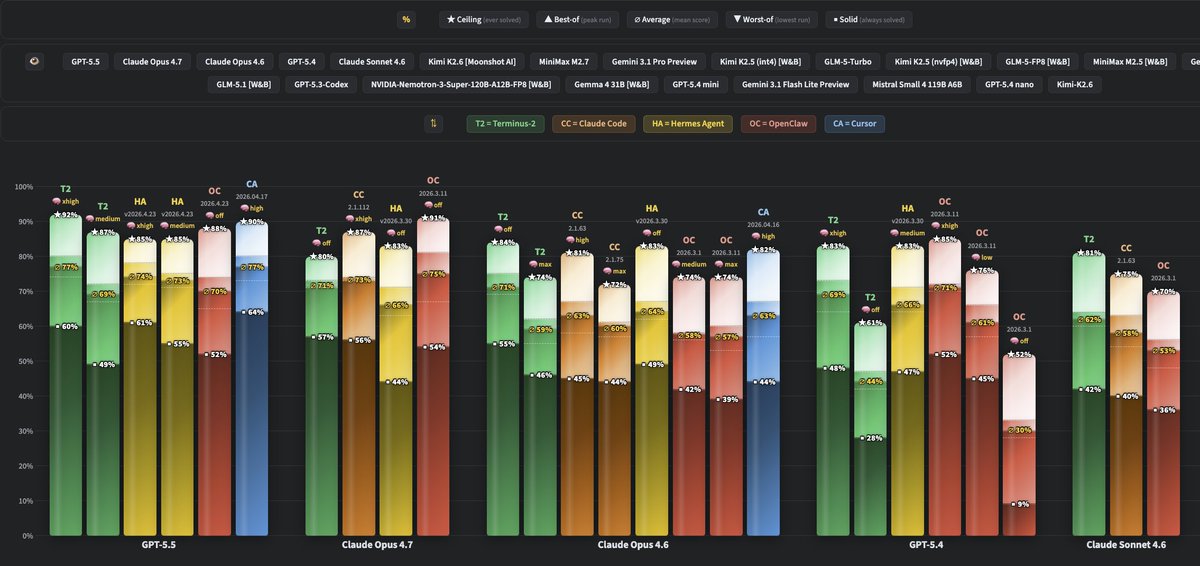
GPT-5.5 takes over WolfBench! It’s now the #1 model, ahead of Claude Opus 4.7 and 4.6, GPT-5.4, Sonnet 4.6, Kimi K2.6, Gemini 3.1 Pro, and more.
Notable findings after 30 runs (40h runtime, >1.7B tokens, ~$3K cost):
- @OpenAI's GPT-5.5 is the best model we ever tested.
- @cursor_ai's Agent CLI (CA) is the best agent we ever tested.
- @NousResearch's Hermes Agent (HA) outperformed OpenClaw (OC).
- With Hermes, going from medium to xhigh reasoning only improved consistency, not capability.
Note: This is WolfBench, where we look at more than just the average score, because one metric is not enough. The golden ∅ score is the actual 5-run average, which most other benchmarks report as their only score. ★ shows the ceiling (what percentage of the full benchmark this model+agent combination solved at least once across all runs). ■ shows the solid base (what percentage of the full benchmark it solved consistently in every run).
For benchmarks, I keep agent versions stable so results stay comparable. But new models can expose agent-side bugs. Here, updating @openclaw from 2026.3.11 to 2026.4.23 lifted Kimi K2.6 from 4% to 60% on @WolfBenchAI due to crucial fixes in how the agent handles its tool calling.
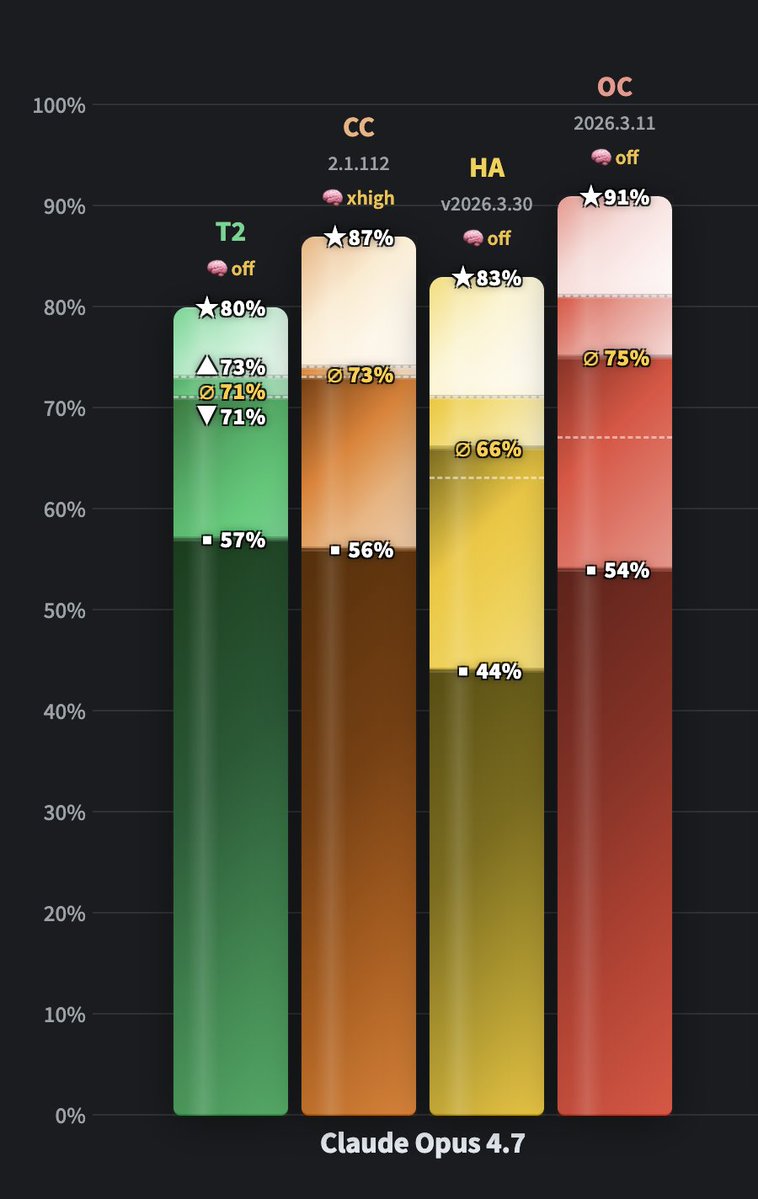
Let's compare the WolfBench top model, GPT-5.5, with our #2, Claude Opus 4.7:
- @openclaw is still better on Opus 4.7 than on GPT-5.5: 75% vs. 70%, with a slightly higher ceiling and base. This is also the third-highest score across all models and agents - only @cursor_ai and Terminus-2 (the official @terminalbench 2.0 test harness) rank higher, both at 77%.
- When no reasoning level is set, the OpenAI API defaults GPT-5.5 to medium, while the Anthropic API defaults Opus 4.7 to no thinking. That's why Terminus-2 and Hermes Agent have different effort levels.
- Note that higher effort levels don't necessarily improve scores in agentic benchmarks - thinking harder can actually make the model dumber: https://t.co/lrLy5fjTp8
- Still have to evaluate Cursor with Opus 4.7; with 4.6, it got 63%.
GPT-5.5 takes over WolfBench! It’s now the #1 model, ahead of Claude Opus 4.7 and 4.6, GPT-5.4, Sonnet 4.6, Kimi K2.6, Gemini 3.1 Pro, and more.
Notable findings after 30 runs (40h runtime, >1.7B tokens, ~$3K cost):
- @OpenAI's GPT-5.5 is the best model we ever tested.
- @cursor_ai's Agent CLI (CA) is the best agent we ever tested.
- @NousResearch's Hermes Agent (HA) outperformed OpenClaw (OC).
- With Hermes, going from medium to xhigh reasoning only improved consistency, not capability.
Note: This is WolfBench, where we look at more than just the average score, because one metric is not enough. The golden ∅ score is the actual 5-run average, which most other benchmarks report as their only score. ★ shows the ceiling (what percentage of the full benchmark this model+agent combination solved at least once across all runs). ■ shows the solid base (what percentage of the full benchmark it solved consistently in every run).
@OpenAI Visit https://t.co/OU3EF9NGyi for the full lineup of models and agents. The site is fully interactive: filter and sort by models, agents, metrics, and scores, or click any bar to jump straight to the corresponding @weave_wb evals and traces. Full transparency for all 300+ runs!
the super interesting thing that I find not enough people talking about is OpenClaw topping the T2 leaderboard for Opus 4.7 with thinking off (@WolfBenchAI eval harness) l - OC also a generic harness unlike the other harnesses in the below lb which are likely benchmaxxed for coding
@Aiolias_@WolfBenchAI That's fair.
But this one is a bit different and tells a realistic story (my custom testing pipeline share more than half of what it uses) .
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
며칠전부터 자꾸 Hermes 에이전트에 신경이 쓰인다.
사실 OpenClaw가 좀 더 오래 시장을 장악할 줄 알았는데, 아직 검증은 안됐지만 강력한 경쟁자가 들어온 것 같다.
미국에 NousResearch라는 팀이 있다. Nous Research는 오픈소스 AI 분야에서 가장 앞서가는 스타트업/연구 팀 중 하나이고. 사용자가 직접 제어할 수 있는 “user-aligned(사용자 정렬)” 모델로 큰 주목을 받고 있다.
그들이 만든 Hermes Agent가 89개 실제 작업 테스트에서 Claude Code와 OpenClaw를 앞질렀다. 점수만 높은 게 아니라 "바닥"이 높았다. 매번 더 많은 작업을 안정적으로 완료했다는 뜻이다.
그럼 왜 그런 결과가 나왔을까? 핵심은 하네스다.
하네스는 AI 모델을 감싸는 틀이다. 같은 Opus 4.6이라도 어떤 하네스에 넣느냐에 따라 결과가 달라진다. Hermes의 주장은 "우리 모델이 더 좋다"가 아니다. "같은 모델을 더 잘 쓰는 구조를 만들었다"는 거에 의미가 있다.
그 구조의 핵심은 학습 루프라는 핵심 기술이다.
Claude Code는 매번 새로 시작한다. OpenClaw는 MEMORY.md로 기억을 수동 관리한다. 기억을 유지하게 셋팅을 하는 것은 여전히 인간 몫이다.
Hermes는 시스템이 조금 다르다. 복잡한 작업이 끝나면 에이전트가 자율적으로 재사용 가능한 스킬을 생성하고 저장한다. 뭘 기억할지, 뭘 스킬로 만들지 에이전트가 스스로 판단하는 구조다.
공식 설명 그대로 "built-in learning loop", "autonomous skill creation", "skills self-improve during use." 인간이 아무것도 안 해도 에이전트가 점점 영리해진다.
커뮤니티에서는 Hermes를 "Claude Code 스타일 CLI와 OpenClaw 스타일 메시징 에이전트의 중간"으로 부르기도 한다. 둘 다 되려 한다는 뜻이다. 터미널에서도, 텔레그램에서도, VPS에서도. v0.2.0 출시 이후 빠르게 스타 10,000개를 넘겼고, 현재 22,000개를 돌파했다.
개인적으로도 이 전략은 영리하다고 생각한다. 사람들은 "3% 더 똑똑한 모델"보다 "나를 기억하는 에이전트"라는 스토리에 더 끌린다. Hermes의 슬로건 "The agent that grows with you"는 성능이 아니라 나와 에이전트의 관계를 판다.
AI 에이전트의 다음 전쟁터는 모델 성능이 아니다. 얼마나 빠르게 배우고, 얼마나 오래 기억하느냐가 아닐까?
그리고 개인 맞춤 에이전트 브랜드가 점점 다가오는 느낌이다.
나도 오늘 한번 설치하고 돌려보려고 한다.
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
@vectro We just published our evals benchmarks for agent harnesses. You can see for yourself below, but Hermes is really powerful straight out of the box. https://t.co/vIQfiF3i4s
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
@ashen_one@VadimStrizheus We ran the evals for that very question here. We tested against different AI models powering it against OC and CC.
https://t.co/vIQfiF3i4s
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
Hermes Agent outperformed Claude Code and OpenClaw as an agentic harness for both Opus 4.6 and GPT-5.4 on 89 real-world tasks.
Not just higher scores but a higher floor. More tasks solved reliably, every single run.
@teknium@NousResearch really cooked with this one. 🔥
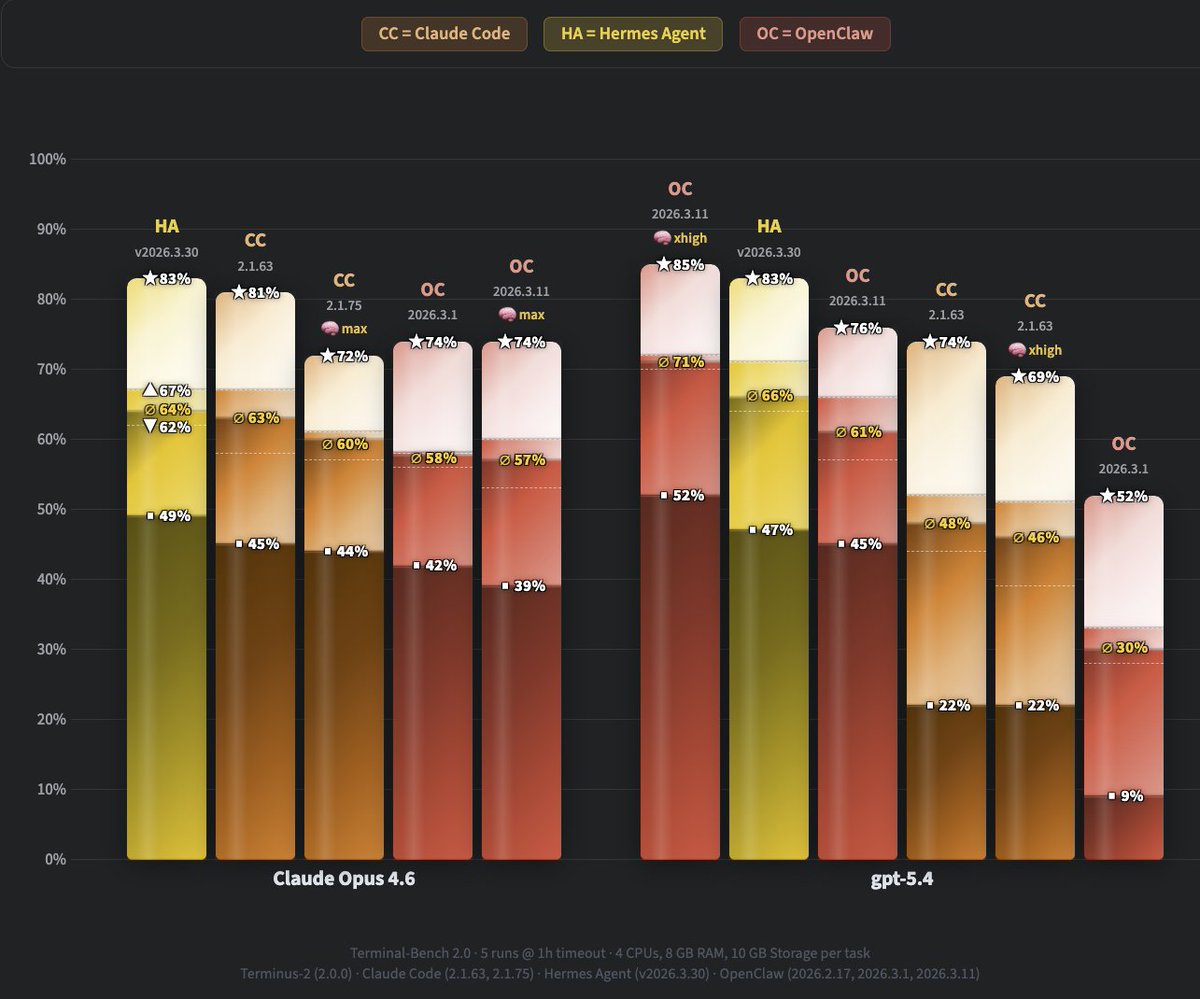
Key takeaways from our latest eval:
> Hermes Agent (default settings) hits 64% avg on Opus 4.6 vs Claude Code's 63% and OpenClaw's 58% — but the solid base jumps from 45%/42% to 49%.
> On GPT-5.4 the gap is massive: 66% avg vs Claude Code's 48% and OpenClaw's 61%, solid base 47% vs 22%/45%.
> It takes GPT-5.4 with xhigh effort for OpenClaw to surpass Hermes Agent with default=medium effort.
> Only with xhigh effort could OC surpass HA with GPT-5.4.
Full breakdown here: https://t.co/IGlGiHLTdc