🚀 Introducing Nemotron-Cascade 2 🚀
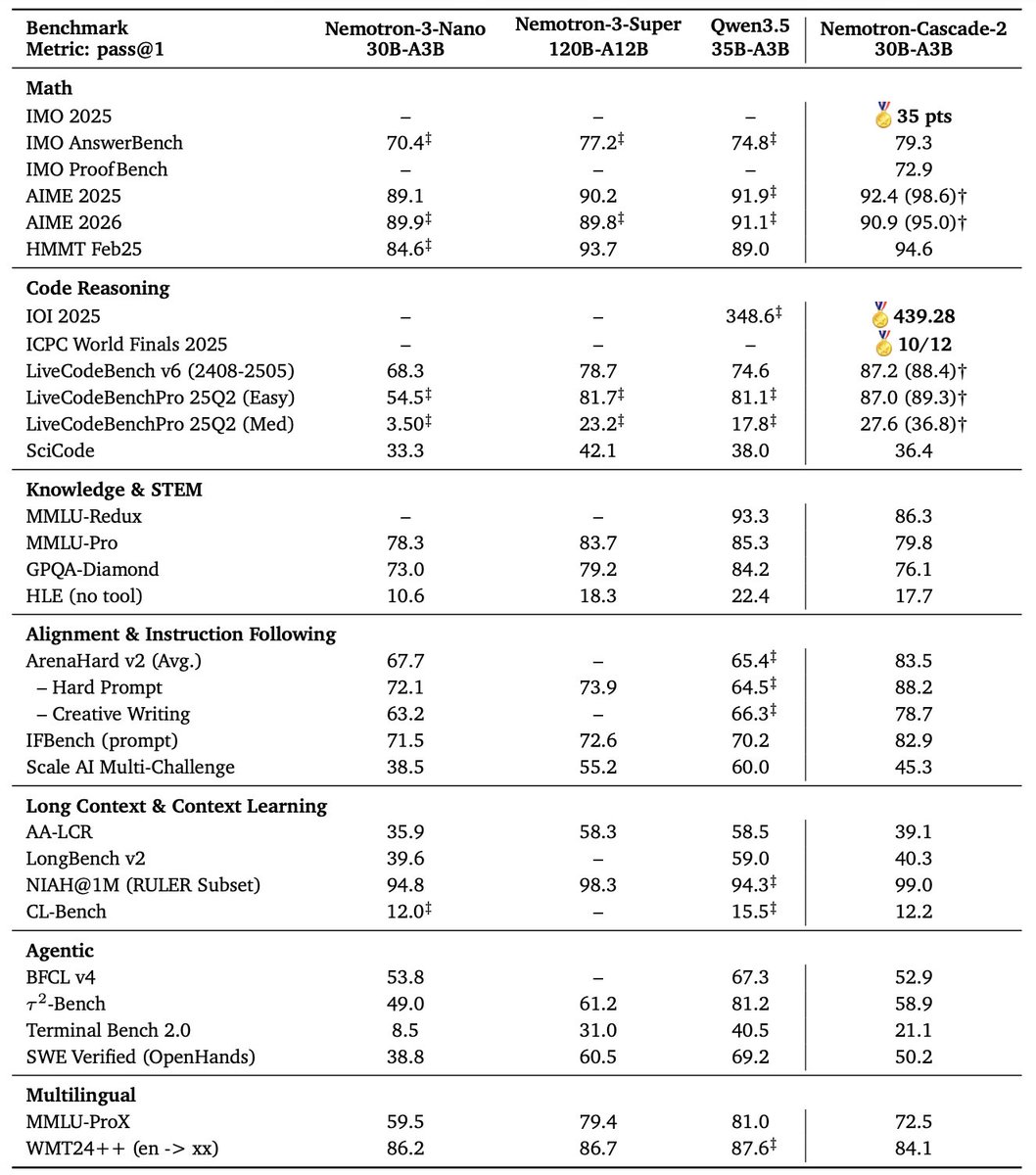
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 https://t.co/4QJqfTOt6I
📄 Technical report:
👉 https://t.co/dFC00m6RZU
only 10% tok/s drop from 4k → 900k context
hybrid sparse/compressed attention w/ serious serving engineering is changing the game
1m context serving is just the beginning
🚀 We just published a deep technical blog on how SGLang and Miles delivered Day-0 support for DeepSeek-V4.
199 tok/s on B200 (Pro 1.6T), 266 tok/s on H200 (Flash 284B) at 4K context, and throughput stays strong at 900K context (180 and 240 tok/s respectively).
This is a full story behind V4 Pro (1.6T) and Flash (284B): how we built systems for hybrid sparse attention, manifold-constrained hyper-connections (mHC), and FP4 expert weights, plus a full RL training stack that runs at 1.6T scale.
What's covered:
1. Inference (caching and attention): ShadowRadix prefix cache, HiSparse CPU-extended KV, MTP speculative decoding with in-graph metadata, Flash Compressor, Lightning TopK, hierarchical multi-stream overlap.
2. Inference (kernels and deployment): fast kernel integrations (FlashMLA, FlashInfer TRTLLM-Gen MoE, DeepGEMM Mega MoE, TileLang mHC), DP/TP/CP attention, EP MoE on DeepEP, PD disaggregation.
3. RL training: full parallelism (DP/TP/SP/EP/PP/CP), tilelang attention, enhanced stability, FP8 training.
4. Multi-hardware: NVIDIA Hopper, Blackwell, Grace Blackwell, AMD, NPU.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Excited to be in Rio de Janeiro for ICLR 2026! #ICLR2026
I’ll be presenting AceReason-Nemotron 1.1 at the poster session on April 24
🕥 10:30 AM – 1:00 PM
📍 Pavilion 4, P4-#4815
Feel free to stop by and say hi!
Poster & Slides 👉 https://t.co/PBMS3CBMJD
Report 📰: https://t.co/xDWgTB0Wcy
Model 🤗: https://t.co/gSdCclcaJ7
The GLM-5 technical report is the best I’ve read since DeepSeek-V3 / R1. It’s packed with valuable studies, rich insights, and detailed analyses.
- The ablation studies on efficient attention variants, such as DeepSeek sparse attention, sliding window attention, and gated DeltaNet, are particularly useful.
- The cascaded RL pipeline (reasoning RL → agentic RL → general RL), coupled with multi-domain on-policy distillation, is especially fascinating. It also resembles the approach used in Nemotron-Cascade, particularly the post-training method in Nemotron-Cascade 2.
- The agentic engineering is exceptionally well-crafted, with a wealth of practical execution details thoughtfully shared.
Many thanks for documenting and sharing all this valuable knowledge with the community!
@Zai_org@jietang@ZixuanLi_
Link: https://t.co/oG70EKY3ur
amazing! observed this think long --> compress --> think long trend during the nemotron-cascade math rl training on a 14B model last year
i thought the training collapse somehow but the next day it recovered!😳
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: https://t.co/hmyDe4Nel3
Weights: https://t.co/CuUjXcPKJD
API: https://t.co/fz6reja4fb
Coding Plan: https://t.co/Nk8Y98HNhU
Coming to https://t.co/WCqWT0qCQb in the next few days.
This is god tier and fits on 24gb +
It crushes everything up to 6x its size and ties with Gemini deep think and Deepseek on Math
https://t.co/0Wwad8HZ4N
"Merging Thinking and Instruct is much easier to describe than to execute well" — SO TRUE
In Nemotron-Cascade, we find that the reasoning performance gap between unified (hybrid thinking/instruct) models and dedicated thinking models can be closed by:
1) Curating SFT data with parallel responses in both Thinking and Instruct modes for the same prompts
2) Using RLHF training that fuses the two modes by allocating an equal split of sampled prompts to each mode in every batch
nvidia's 3B mamba destroyed alibaba's 3B deltanet on the same RTX 3090. only 24 days between releases. same active parameters, same VRAM tier, completely different architectures.
nemotron cascade 2: 187 tok/s. flat from 4K to 625K context. zero speed loss.
flags: -ngl 99 -np 1. that's it. no context flags, no KV cache tricks. auto-allocates 625K.
qwen 3.5 35B-A3B: 112 tok/s. flat from 4K to 262K context. zero speed loss.
flags: -ngl 99 -np 1 -c 262144 --cache-type-k q8_0 --cache-type-v q8_0. needed KV cache quantization to fit 262K.
both models held a flat line across every context level. both architectures are context-independent. but nvidia's mamba2 is 67% faster at generating tokens on the exact same hardware and needs fewer flags to get there. same node, same GPU, same everything. the only variable is the model.
gold medal math olympiad winner running at 187 tokens per second on single RTX 3090 a card from 6 years ago. nvidia cooked.
Thank you to everyone in the community who is testing and using Nemotron models. It's great to see Nemotron-Cascade-2, Nemotron-3-Super and Nemotron-3-Nano trending on HF.
The Nemotron team is working hard to incorporate all your feedback into Nemotron 4.
And yes, Nemotron 3 Ultra is still on track for release.
https://t.co/lkEwmlUng9
We released Nemotron Cascade 2 30B A3B.
What makes this release especially meaningful to me is that it reflects a 1.5-year journey at NVIDIA around one core idea: improving AI math reasoning through self-improvement at test time.
Each project tackled a different part of that problem.
With AceMath (24 Q4), we built an external verifier model to identify the right solution during test-time scaling.
With AceReason (24 Q1-2), we scaled the reasoning capabilities of the model through RL so the model could spend more time reflecting while solving problems. Along the way, we found a general, simple and effective RL recipe that we’ve kept using since.
And now with Cascade 2 (25 Q1), we’ve pushed that effort further: the model can generate hypotheses, verify them, and refine them on its own. That self-improvement loop is what enabled IMO gold-level performance at 30B level.
From MATH500, to AIME, and now IMO Proof.
This team is THE BEST.
Technical report:
https://t.co/V0XZn2ypPg
Nemotron-Cascade-2 is now available to run with Ollama.
ollama run nemotron-cascade-2
To run it locally with OpenClaw:
ollama launch openclaw --model nemotron-cascade-2
This model from NVIDIA delivers strong reasoning and agentic capabilities on par with models with up to 20x more parameters.
🚀 Introducing Nemotron-Cascade 2 🚀
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 https://t.co/4QJqfTOt6I
📄 Technical report:
👉 https://t.co/dFC00m6RZU
🚀 Introducing Nemotron-Cascade 2: our new best-in-class 30B-A3B MoE model.
🥇 Gold Medal at IMO 2025, IOI 2025, and the ICPC World Finals.
🔥 Outperforms Qwen3.5-35B-A3B across Math, Code Reasoning, alignment, and instruction following.
🔓 Great reproducibility: Model weights, SFT, and RL data are open!
Check out our technical report and huggingface page for more details and insights 👇
📰 Technical Report: https://t.co/m9sZCE3Zxy
🤗 Model & Data: https://t.co/sy7YTCwEub
It’s been a busy but remarkable spring season, with frontier labs releasing their powerful models with impressive results at large scale. Still, we are excited to see our 30B-A3B MoE model could match or even outperform frontier-series models on general domains with our cascade RL pipeline design.
Still few bullets here:
* Cascade RL is still robust. We observed minimal drop across all RL stages on various domains.
* MOPD is a magic. We saw this (or it’s variants) was applied in frontier lab’s tech report, and it is super useful on aggregating multi-domain’s expertise throughout your cascade RL training pipeline. I would describe it as "learn from your slice of life, in parallel worlds".
* For competitive coding domain, yes I’m finally outclassed, but proud that this model is stronger than I am. I really feel my "Aja Huang" moment.
Hope you enjoy this spring gift.
Model weights: https://t.co/6PN29EqyI6
Tech report: https://t.co/4eWKGxbU1Z
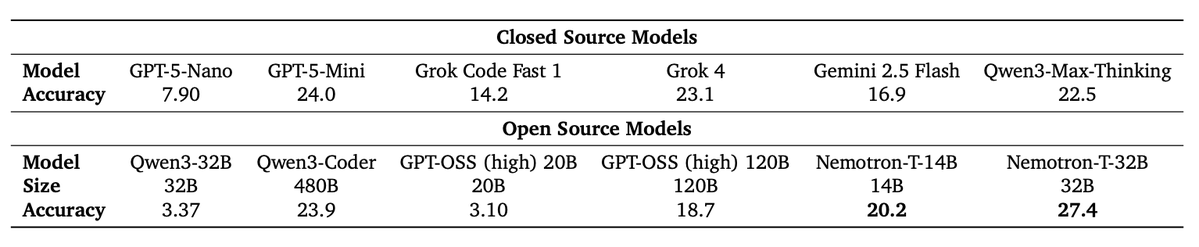
I like this Nvidia RL paper for its complete reproducibility, so much so that, in Feynman's language, you can "invent" the whole RL training pipeline yourself. A ton of persuasive ablations you would find missing even in those frontier model reports. Some takeaways:
- RLHF is important as a warmup stage for even math and code RL. In a lot of tech reports we see that reasoning RL is often the first stage of training. The authors compare training math and coding directly after SFT vs after RLHF. They find lifted math/coding performances after RLHF on all benchmarks and even just training RLHF shows lifts.
- It is beneficial to train math RL on different context lengths progressively. The authors train it in three stages: 24K, 32K, 40K. Each stage has its own use. The first two stages are motivated by the fact that models have a high probability of going over the max context length, so training them at 24/32K stabilizes the reasoning and makes it more effective, and is judged by the decrease in incomplete ratio. The final stage is motivated by the opposite problem: when extending to longer context (eg. 64K), the model cannot use all of the context effectively to solve hard AIME problems. So the authors introduce a third stage to let models extend their comfortable context length to 40K and see lift in performance.
An interesting property is that when the context size is small (<=24K), ablations show that throwing away responses going over the context size is more beneficial than assigning them 0 reward. But at a longer context size (>=32K), assigning 0 reward is more beneficial. (p2)
Another interesting property is that they empirically find that training with a temperature of 1 (as opposed to 0.6/0.8) leads to better performances of math and coding, and needs to be carefully maintained to not have entropy explode (p3).
- Probably the most interesting part: you can improve SWE performances with RL that does not execute code in an environment at all. Specifically, to solve the code repair problem of a SWE task, the training setup is as simple as giving the model the problem files (with some noise) and asking it to come up with a patch.
Since there is no code execution to give an outcome reward, the reward, which is very novel, is to let an LLM compare the predicted patch with the true patch, and get the probability of the model outputting the token "yes". As a probability, this reward naturally falls into [0, 1]. By training on this signal alone, the authors are able to scale up the number of tasks. And they find lift in SWE-Bench verified.
- Plain old policy gradient work. The authors choose to keep the training fully on-policy. As a result, each rollout is trained for one gradient update, and therefore the importance sampling ratio is always 1. The authors state that this is for training stability and avoids entropy collapse.
Overall, the pipeline is RLHF -> instruction following -> math -> coding -> SWE, and the authors keep track of benchmark performances after each stage to see the dynamics. They also go into details of data preparation, reward function, dynamic filtering for each stage. A great resource for the open source community.
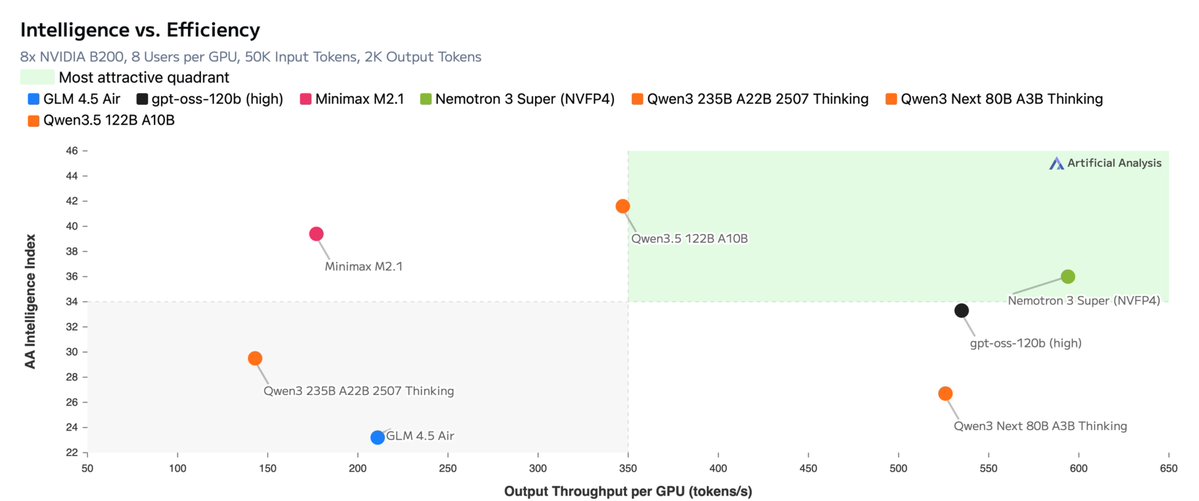
Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell
💚36 on AAIndex v4
💚up to 2.2X faster than GPT-OSS-120B in FP4
💚Open data, open recipe, open weights
Models, Tech report, etc. here:
https://t.co/CAYpP1iK3i
And yes, Ultra is coming!
Nemotron 3 Super is here — 120B total / 12B active, Hybrid SSM Latent MoE, designed for Blackwell.
Truly open: permissive license, open data, open training infra. See analysis on @ArtificialAnlys
Details in thread 🧵below:
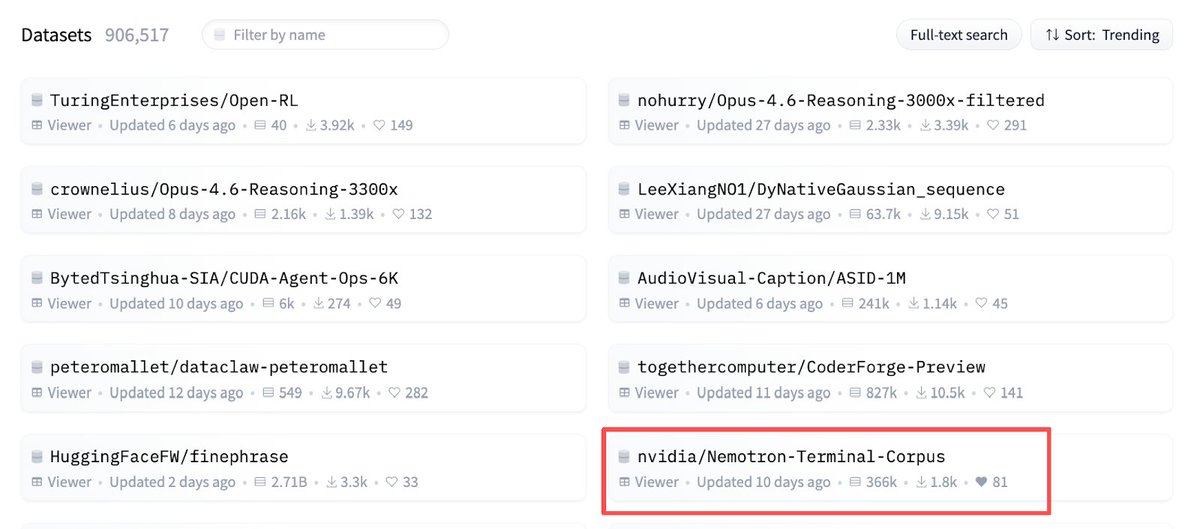
Introducing Nemotron-Terminal: a systematic data engineering pipeline for scaling LLM Terminal Agents.
We bridge the gap between open models and proprietary models with a fully open synthetic-to-real trajectory pipeline.
🤯The payoff: SFT on our Nemotron-Terminal-Corpus boosts Qwen3-32B from 3.4% → 27.4% on Terminal-Bench 2.0 (+24.0), rivaling models multiple its size.
What makes it work?
🌟Terminal-Task-Gen: A lightweight data curation pipeline that seamlessly combines the adaptation of existing datasets with robust synthetic task construction.
🌟Nemotron-Terminal-Corpus: A massive, open-source dataset covering diverse terminal interactions, which contains explicit planning and execution traces for complex long-horizon tasks.
And we’re releasing everything:
📦 Nemotron-Terminal-Corpus (Large-scale dataset)
🤖 Nemotron-Terminal models (8B, 14B, 32B)
Paper: https://t.co/ORIZ01sav1
HF Daily: https://t.co/nSH4hu7I5D
Models & Data: https://t.co/J1Zc22M95r
Our tech report just hit the #1 spot on Hugging Face Daily Papers!
We're also incredibly excited to see the open-source community putting our work to the test, with the Nemotron-Terminal-Corpus dataset currently trending at over 1,800 downloads and counting.
We can't wait to see what the community build with it!














![HeMuyu0327's tweet photo. I like this Nvidia RL paper for its complete reproducibility, so much so that, in Feynman's language, you can "invent" the whole RL training pipeline yourself. A ton of persuasive ablations you would find missing even in those frontier model reports. Some takeaways:
- RLHF is important as a warmup stage for even math and code RL. In a lot of tech reports we see that reasoning RL is often the first stage of training. The authors compare training math and coding directly after SFT vs after RLHF. They find lifted math/coding performances after RLHF on all benchmarks and even just training RLHF shows lifts.
- It is beneficial to train math RL on different context lengths progressively. The authors train it in three stages: 24K, 32K, 40K. Each stage has its own use. The first two stages are motivated by the fact that models have a high probability of going over the max context length, so training them at 24/32K stabilizes the reasoning and makes it more effective, and is judged by the decrease in incomplete ratio. The final stage is motivated by the opposite problem: when extending to longer context (eg. 64K), the model cannot use all of the context effectively to solve hard AIME problems. So the authors introduce a third stage to let models extend their comfortable context length to 40K and see lift in performance.
An interesting property is that when the context size is small (<=24K), ablations show that throwing away responses going over the context size is more beneficial than assigning them 0 reward. But at a longer context size (>=32K), assigning 0 reward is more beneficial. (p2)
Another interesting property is that they empirically find that training with a temperature of 1 (as opposed to 0.6/0.8) leads to better performances of math and coding, and needs to be carefully maintained to not have entropy explode (p3).
- Probably the most interesting part: you can improve SWE performances with RL that does not execute code in an environment at all. Specifically, to solve the code repair problem of a SWE task, the training setup is as simple as giving the model the problem files (with some noise) and asking it to come up with a patch.
Since there is no code execution to give an outcome reward, the reward, which is very novel, is to let an LLM compare the predicted patch with the true patch, and get the probability of the model outputting the token "yes". As a probability, this reward naturally falls into [0, 1]. By training on this signal alone, the authors are able to scale up the number of tasks. And they find lift in SWE-Bench verified.
- Plain old policy gradient work. The authors choose to keep the training fully on-policy. As a result, each rollout is trained for one gradient update, and therefore the importance sampling ratio is always 1. The authors state that this is for training stability and avoids entropy collapse.
Overall, the pipeline is RLHF -> instruction following -> math -> coding -> SWE, and the authors keep track of benchmark performances after each stage to see the dynamics. They also go into details of data preparation, reward function, dynamic filtering for each stage. A great resource for the open source community.](https://pbs.twimg.com/media/HDL2Wg1bQAEuV4d.jpg)
![HeMuyu0327's tweet photo. I like this Nvidia RL paper for its complete reproducibility, so much so that, in Feynman's language, you can "invent" the whole RL training pipeline yourself. A ton of persuasive ablations you would find missing even in those frontier model reports. Some takeaways:
- RLHF is important as a warmup stage for even math and code RL. In a lot of tech reports we see that reasoning RL is often the first stage of training. The authors compare training math and coding directly after SFT vs after RLHF. They find lifted math/coding performances after RLHF on all benchmarks and even just training RLHF shows lifts.
- It is beneficial to train math RL on different context lengths progressively. The authors train it in three stages: 24K, 32K, 40K. Each stage has its own use. The first two stages are motivated by the fact that models have a high probability of going over the max context length, so training them at 24/32K stabilizes the reasoning and makes it more effective, and is judged by the decrease in incomplete ratio. The final stage is motivated by the opposite problem: when extending to longer context (eg. 64K), the model cannot use all of the context effectively to solve hard AIME problems. So the authors introduce a third stage to let models extend their comfortable context length to 40K and see lift in performance.
An interesting property is that when the context size is small (<=24K), ablations show that throwing away responses going over the context size is more beneficial than assigning them 0 reward. But at a longer context size (>=32K), assigning 0 reward is more beneficial. (p2)
Another interesting property is that they empirically find that training with a temperature of 1 (as opposed to 0.6/0.8) leads to better performances of math and coding, and needs to be carefully maintained to not have entropy explode (p3).
- Probably the most interesting part: you can improve SWE performances with RL that does not execute code in an environment at all. Specifically, to solve the code repair problem of a SWE task, the training setup is as simple as giving the model the problem files (with some noise) and asking it to come up with a patch.
Since there is no code execution to give an outcome reward, the reward, which is very novel, is to let an LLM compare the predicted patch with the true patch, and get the probability of the model outputting the token "yes". As a probability, this reward naturally falls into [0, 1]. By training on this signal alone, the authors are able to scale up the number of tasks. And they find lift in SWE-Bench verified.
- Plain old policy gradient work. The authors choose to keep the training fully on-policy. As a result, each rollout is trained for one gradient update, and therefore the importance sampling ratio is always 1. The authors state that this is for training stability and avoids entropy collapse.
Overall, the pipeline is RLHF -> instruction following -> math -> coding -> SWE, and the authors keep track of benchmark performances after each stage to see the dynamics. They also go into details of data preparation, reward function, dynamic filtering for each stage. A great resource for the open source community.](https://pbs.twimg.com/media/HDL2TFhbMAAdnNs.jpg)

















![HeMuyu0327's tweet photo. I like this Nvidia RL paper for its complete reproducibility, so much so that, in Feynman's language, you can "invent" the whole RL training pipeline yourself. A ton of persuasive ablations you would find missing even in those frontier model reports. Some takeaways:
- RLHF is important as a warmup stage for even math and code RL. In a lot of tech reports we see that reasoning RL is often the first stage of training. The authors compare training math and coding directly after SFT vs after RLHF. They find lifted math/coding performances after RLHF on all benchmarks and even just training RLHF shows lifts.
- It is beneficial to train math RL on different context lengths progressively. The authors train it in three stages: 24K, 32K, 40K. Each stage has its own use. The first two stages are motivated by the fact that models have a high probability of going over the max context length, so training them at 24/32K stabilizes the reasoning and makes it more effective, and is judged by the decrease in incomplete ratio. The final stage is motivated by the opposite problem: when extending to longer context (eg. 64K), the model cannot use all of the context effectively to solve hard AIME problems. So the authors introduce a third stage to let models extend their comfortable context length to 40K and see lift in performance.
An interesting property is that when the context size is small (<=24K), ablations show that throwing away responses going over the context size is more beneficial than assigning them 0 reward. But at a longer context size (>=32K), assigning 0 reward is more beneficial. (p2)
Another interesting property is that they empirically find that training with a temperature of 1 (as opposed to 0.6/0.8) leads to better performances of math and coding, and needs to be carefully maintained to not have entropy explode (p3).
- Probably the most interesting part: you can improve SWE performances with RL that does not execute code in an environment at all. Specifically, to solve the code repair problem of a SWE task, the training setup is as simple as giving the model the problem files (with some noise) and asking it to come up with a patch.
Since there is no code execution to give an outcome reward, the reward, which is very novel, is to let an LLM compare the predicted patch with the true patch, and get the probability of the model outputting the token "yes". As a probability, this reward naturally falls into [0, 1]. By training on this signal alone, the authors are able to scale up the number of tasks. And they find lift in SWE-Bench verified.
- Plain old policy gradient work. The authors choose to keep the training fully on-policy. As a result, each rollout is trained for one gradient update, and therefore the importance sampling ratio is always 1. The authors state that this is for training stability and avoids entropy collapse.
Overall, the pipeline is RLHF -> instruction following -> math -> coding -> SWE, and the authors keep track of benchmark performances after each stage to see the dynamics. They also go into details of data preparation, reward function, dynamic filtering for each stage. A great resource for the open source community.](https://pbs.twimg.com/media/HDL2o3WboAASdRS.jpg)