I recently spent a few weeks using #ClaudeDesign and #ClaudeCode to redesign a mobile app I'd built in my spare time. Some of it worked well, some did not.
Details in the thread.
5/ #ClaudeCode and @ChatGPTapp are both pretty bad at taking a PNG of an icon and turning it into an SVG or SwiftUI vector format.
I built a skill to handle this, it still isn't perfect but the results are good with a few iterations.
👉 https://t.co/jOlVn8tzWt
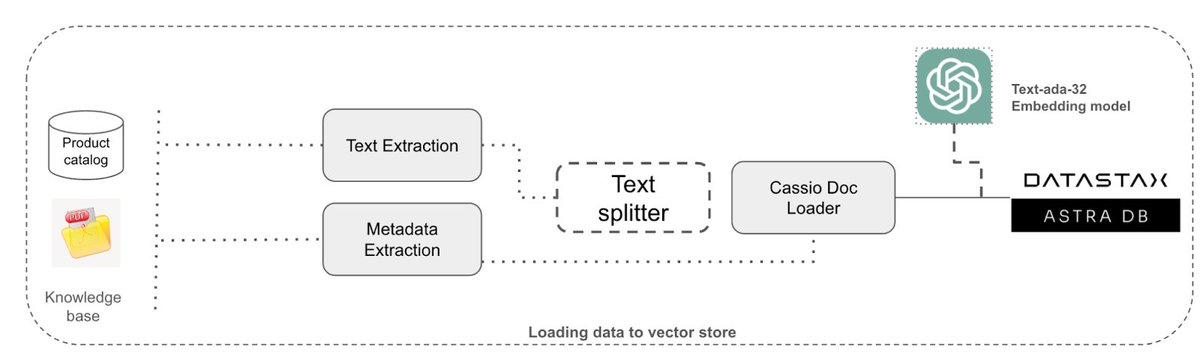
GAME-CHANGING news from @DataStax at #GTC25! 🚀
Introducing Astra DB Hybrid Search 💥
With @NVIDIA NeMo Retriever Text Reranking, Astra DB Hybrid Search boosts relevance by 45%, delivering smarter, more accurate AI responses.
Learn more: https://t.co/hAYmDzWqWi
ColBERT Live! is a library that makes your existing vector database smarter with ColBERT multi-vector search. Get the relevance of ColBERT while respecting your ACLs and integrating with your metadata filtering. And introducing query embedding pooling!
Article in thread.
⭐️How Physics Wallah Uses LangChain, DataStax Astra DB, Vector Search and RAG to Revolutionize Education
Physics Wallah built an AI Guru - a personalized AI tutor application, to assist students with their academic and support queries.
https://t.co/xu3uOAU91j
Building GenAI apps just got 100x easier and more fun. ⛓🎉🤝 Langflow joins DataStax!
Learn how Langflow’s visual framework for building RAG apps with LangChain helps developers get their wild new GenAI ideas into production — quick. https://t.co/kF6iwMwtcI
@AstraDB Cassandra-based Vector DB 🌌
Explore the langchain-astradb integration package! Harness the serverless, vector-capable database built on Apache Cassandra for scalable NoSQL solutions enhanced with the power of vector similarity search.
https://t.co/0NlMqatiqB
We’re excited to feature the AI Chatbot Starter 🤖🧰 - a web server powered by AstraDB (@DataStax) and @llama_index that you can easily spin up to chat over any web documentation 🌐📑
Easily use this as a standalone service or integrate it with your full-stack application.
Set it up by simply setting a few credentials and ingesting your documents.
A huge shoutout to the @Datastax team for creating this: check it out below 👇
Repo: https://t.co/yENP00DorQ
@ThawabHAlsubaie@skalskip92@ClementDelangue OpenAI is pretty limited here. Only 20 documents. No control over how they are searched. Insanely expensive storage (about 20x most DBs).
Good enough for some experiments but can’t see running a production app on this.
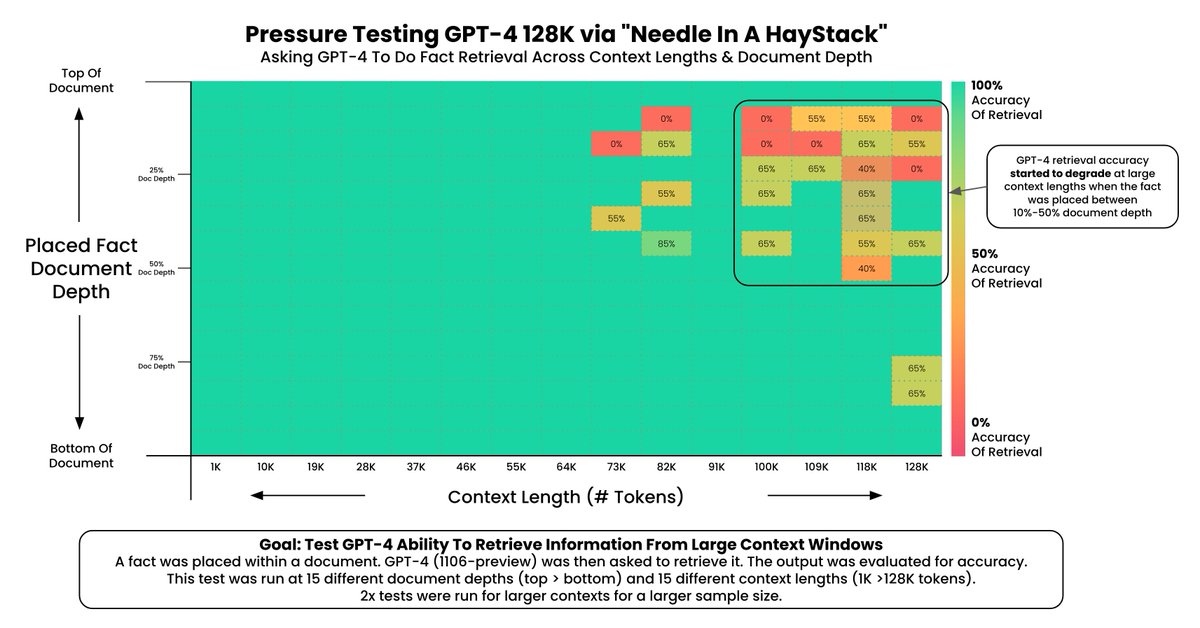
Pressure Testing GPT-4-128K With Long Context Recall
128K tokens of context is awesome - but what's performance like?
I wanted to find out so I did a “needle in a haystack” analysis
Some expected (and unexpected) results
Here's what I found:
Findings:
* GPT-4’s recall performance started to degrade above 73K tokens
* Low recall performance was correlated when the fact to be recalled was placed between at 7%-50% document depth
* If the fact was at the beginning of the document, it was recalled regardless of context length
So what:
* No Guarantees - Your facts are not guaranteed to be retrieved. Don’t bake the assumption they will into your applications
* Less context = more accuracy - This is well know, but when possible reduce the amount of context you send to GPT-4 to increase its ability to recall
* Position matters - Also well know, but facts placed at the very beginning and 2nd half of the document seem to be recalled better
Overview of the process:
* Use Paul Graham essays as ‘background’ tokens. With 218 essays it’s easy to get up to 128K tokens
* Place a random statement within the document at various depths. Fact used: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”
* Ask GPT-4 to answer this question only using the context provided
* Evaluate GPT-4s answer with another model (gpt-4 again) using @langchain evals
* Rinse and repeat for 15x document depths between 0% (top of document) and 100% (bottom of document) and 15x context lengths (1K Tokens > 128K Tokens)
Next Steps To Take This Further:
* Iterations of this analysis were evenly distributed, it’s been suggested that doing a sigmoid distribution would be better (it would tease out more nuanced at the start and end of the document)
* For rigor, one should do a key:value retrieval step. However for relatability I did a San Francisco line within PGs essays.
Notes:
* While I think this will be directionally correct, more testing is needed to get a firmer grip on GPT4s abilities
* Switching up prompt with vary results
* 2x tests were run at large context lengths to tease out more performance
* This test cost ~$200 for API calls (a single call at 128K input tokens costs $1.28)
* Thank you to @charles_irl for being a sounding board and providing great next steps
ran gpt4 128k context on the "1 useful document + K distractors" from our "attention sorting" paper, seems like the very long (more than 32k) doesn't work that well. 32k is still extremely impressive though!
also claude2 clearly has some nice trick behind the scenes
@jibinmathew_69 ➡️Limited to 20 documents
➡️Expensive storage ($.20/GB/day vs $0.25/GB/month in Astra DB and other similar vector databases), about 25x more expensive
➡️ Black box on chunking methodology.
Good for getting started, but not enough for production RAG.
Seems good for spinning up some quick tests and getting good results on small sets of documents for Q&A, but probably isn't going to be good enough for production-scale RAG applications.
➡ Limited to 20 documents
➡ Expensive storage ($.20/GB/day vs $0.25/GB/month in Astra DB and other similar vector databases), about 25x more expensive
➡ Black box on chunking strategies