Google releases Gemma 4 QAT. ✨
You can now run Gemma 4 at 3x less memory with near original performance.
Quantization-Aware Training (QAT) makes it possible to run Gemma 4 26B-A4B on 16GB RAM.
GGUFs: https://t.co/wQgEocxUId
QAT Guide: https://t.co/Nsm1yeGEHx
@ivanfioravanti Google version of MTP or namely speculative decoding model, Google naming their speculative decoding model 'assistant'. Combination of Gemma4-12B with its Assistant version increase inference speed afaik
@glnrcngz@Ozumraniyeli aletin ne olduğunu doğru tanımlarsak sorun yok, alet çok iyi bir blender sadece. Dondurma yapma makinesi değil yaptığın dondurmayı karıştırma makinesi ismi koyulmalıymış.
@gyilmazsde@CSProfKGD without a copilot plan you can still use copilot cli and agentic orchestration in vscode with other models within copilot model provider like Openrouter
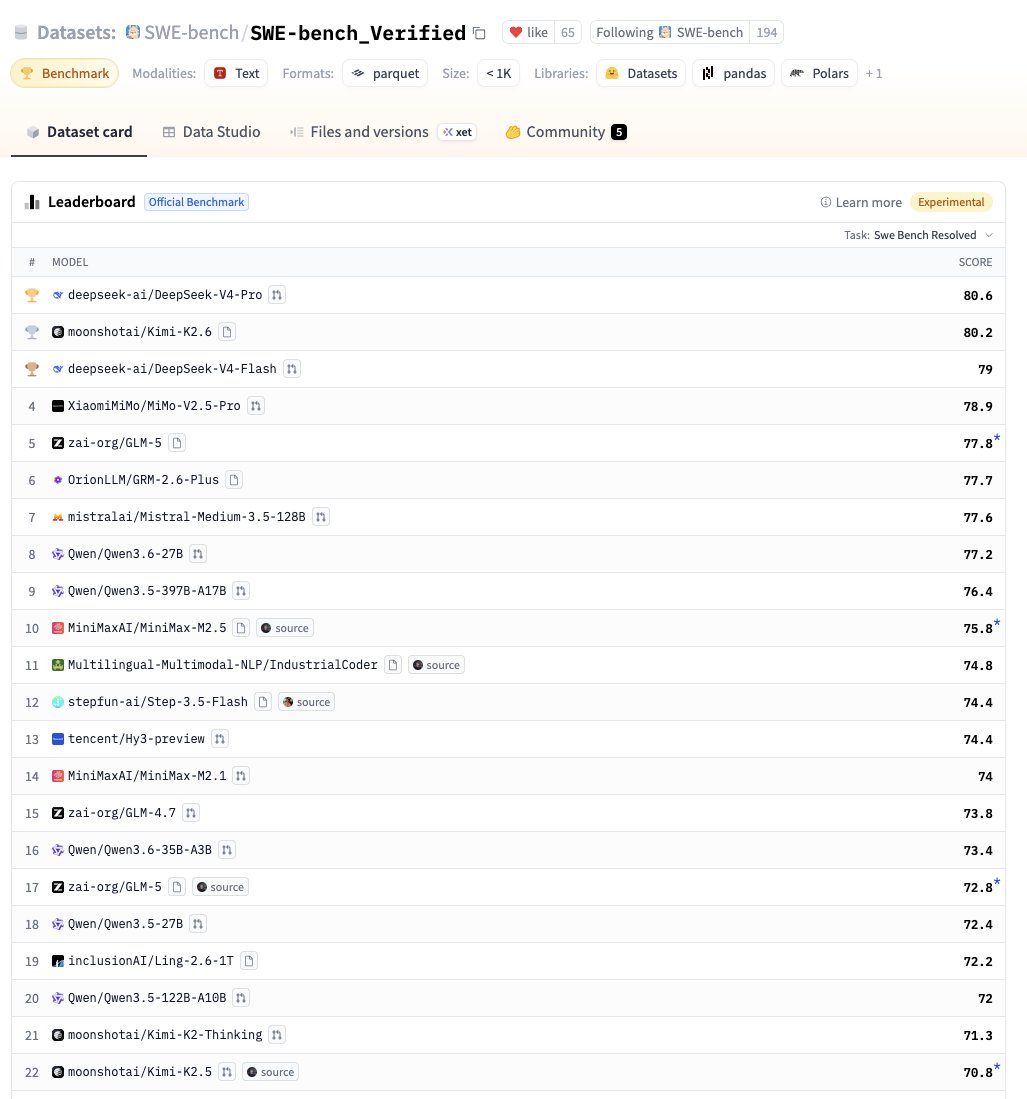
The SWE-bench Verified leaderboard on @huggingface now compares almost 50 models...
Community benchmarking > closed benchmarking. More participants, more data, better signal.
🏆 Top 5 models..
1️⃣ @deepseek_ai
2️⃣ @Kimi_Moonshot
3️⃣ @deepseek_ai
4️⃣ @XiaomiMiMo
5️⃣ @Zai_org
NVIDIA releases Nemotron-3-Nano-Omni, a new 30B open multimodal MoE model.
Nemotron-3-Nano-Omni-30B-A3B is the strongest omni model for its size and supports audio, video, image and text.
Run on ~25GB RAM.
GGUF: https://t.co/t4COCqVrLS
Guide: https://t.co/GWTr8165pM
@yabancibasin memurların yaptığı işten ziyade memurların kullandığı sistemlerin birbirlerinden haberi yok agentic e dönüşüm zor, önce dijital dönüşüm şart ama memurlar da elinden yapmayı bildikleri tek şey alınacak diye ayak sürüyorlar dönüşüme 🤷🏻♂️
@EVTR__ CR-Z güzel bir benzetme oluyor, ama Aztek "ugliest cars" listelerinin tepelerini zorladığı için eleştiri bakımından daha güzel bir benzetme bence 😅