What a finish! Gemini 2.5 Pro just completed Pokémon Blue!  Special thanks to @TheCodeOfJoel for creating and running the livestream, and to everyone who cheered Gem on along the way.
We reproduced DeepSeek R1-Zero in the CountDown game, and it just works
Through RL, the 3B base LM develops self-verification and search abilities all on its own
You can experience the Ahah moment yourself for < $30
Code: https://t.co/UcGKN2SVGj
Here's what we learned 🧵
Our last CEO f'd things up. I'm fixing them.
Introducing white label hot sauce.
Go fucking buy it now.
https://t.co/dnBsPvbK8f
Ricky Berwick (@rickyberwick)
CEO, Sticker Mule
P.S. 20 people who repost this win $500. Follow us so we can DM you.
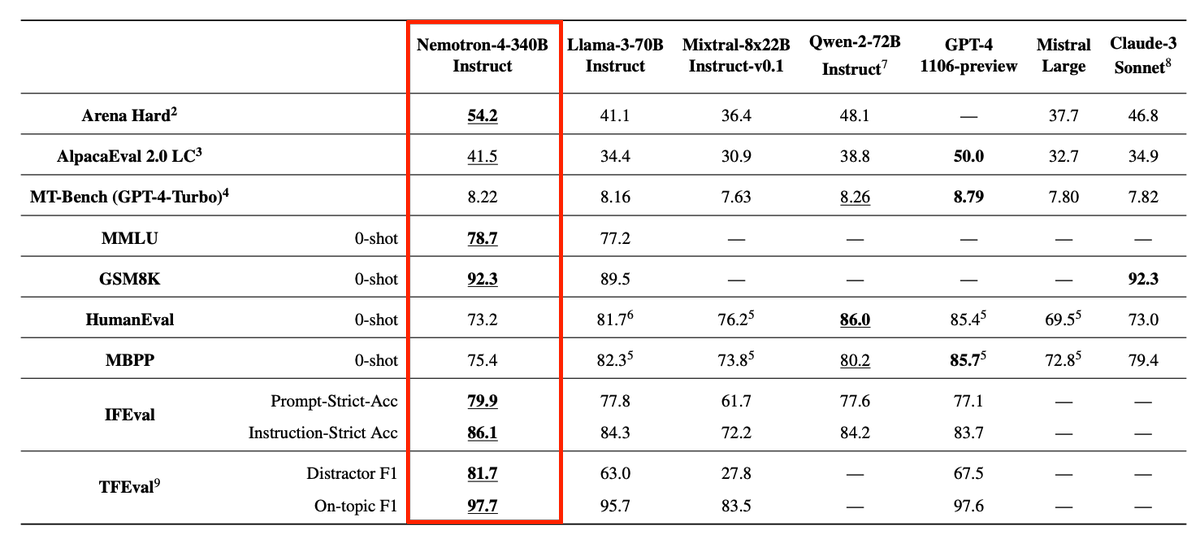
Nemotron-4 340B is a huge release by NVIDIA!
Why?
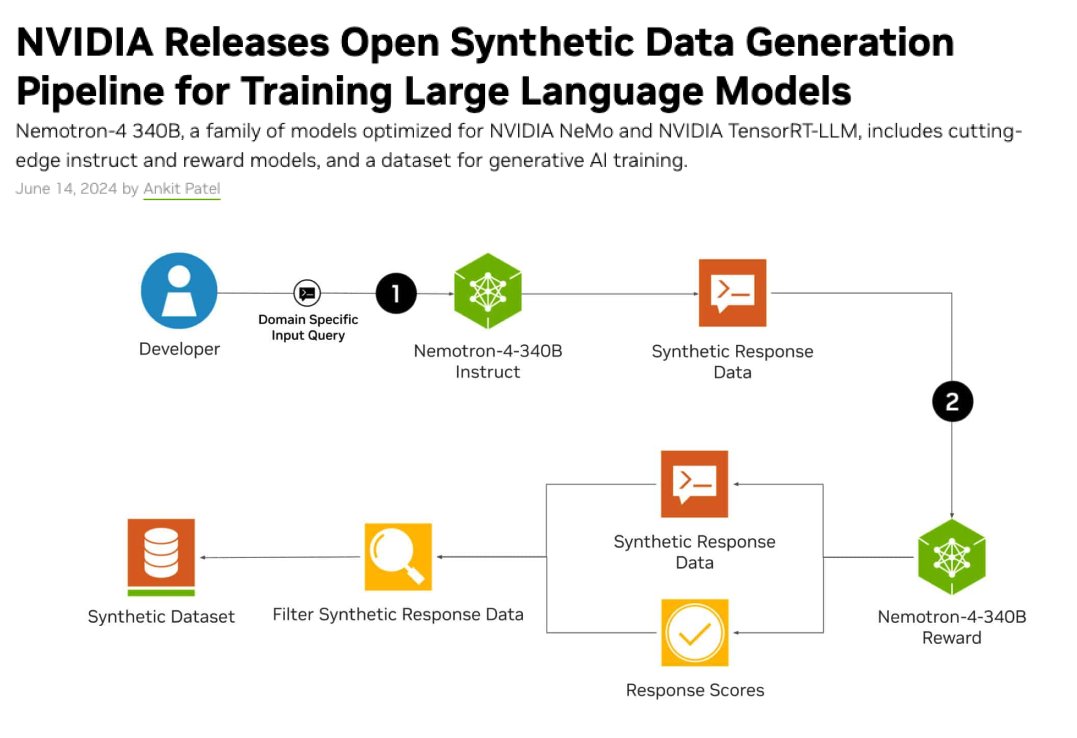
The Nemotron-4 340B instruct model lets you generate high-quality data and then the reward model (also released) can filter out data on several attributes.
It's often not enough just to have a good instruct model for generating high-quality synthetic data. You also need to filter that generated data on a set of requirements. It's common to use the same model to grade the outputs (LLM-as-Judge) but the reward model (Reward-Model-as-Judge), which is often not released, is ideal for this.
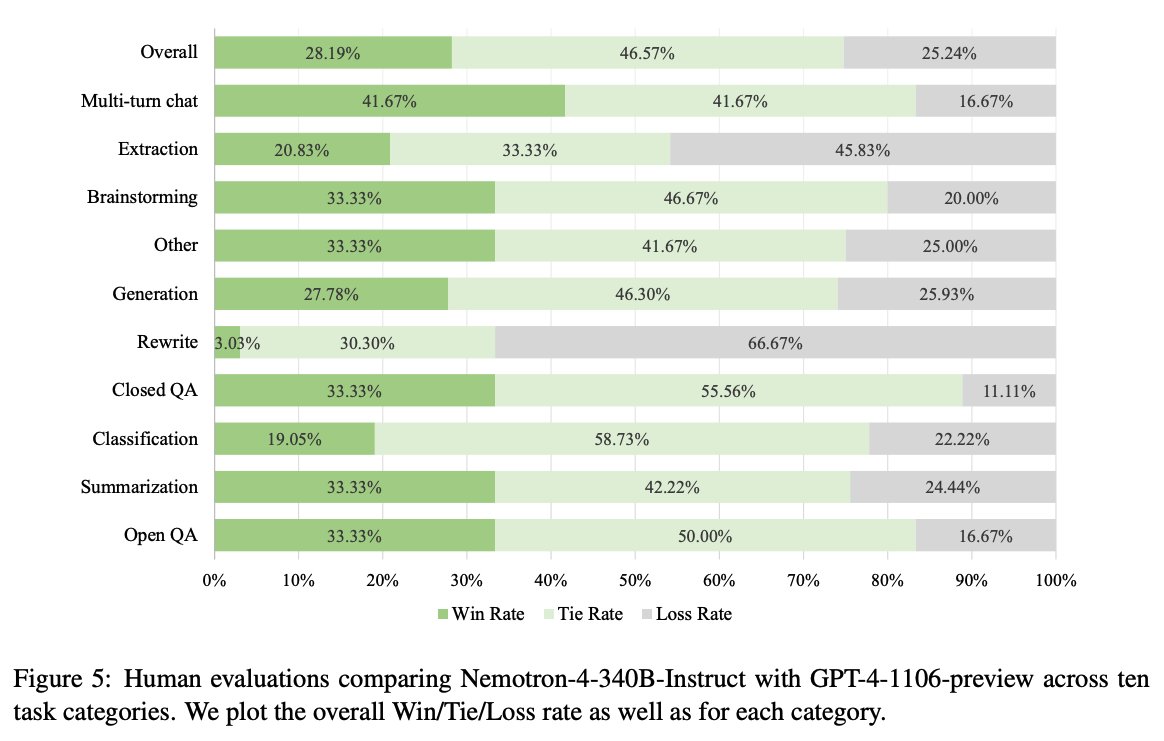
Also, check out in the paper how Nemotron-4-340B compares with GPT-4-1106-preview when evaluated by humans on several tasks.
Seems that GPT-4 is a lot better at rewrite and extraction but Nemotron-4-340B compared nicely on other tasks. Multi-turn chat has a high score!
Something else that caught my attention is that the majority of preference data used for alignment are synthetic.
The results show that Nemotron-4 340B is a strong model. Check out those MMLU, GSM8K, and Arena Hard numbers.
GPT-4 is still ahead but the gap keeps closing.
What's Meta's move now? Are we going to see a similar type of release? Could be a huge moment for the field and open LLMs.
Nice release from NVIDIA. They even released a preference dataset (link in the replies). Well done to the team!