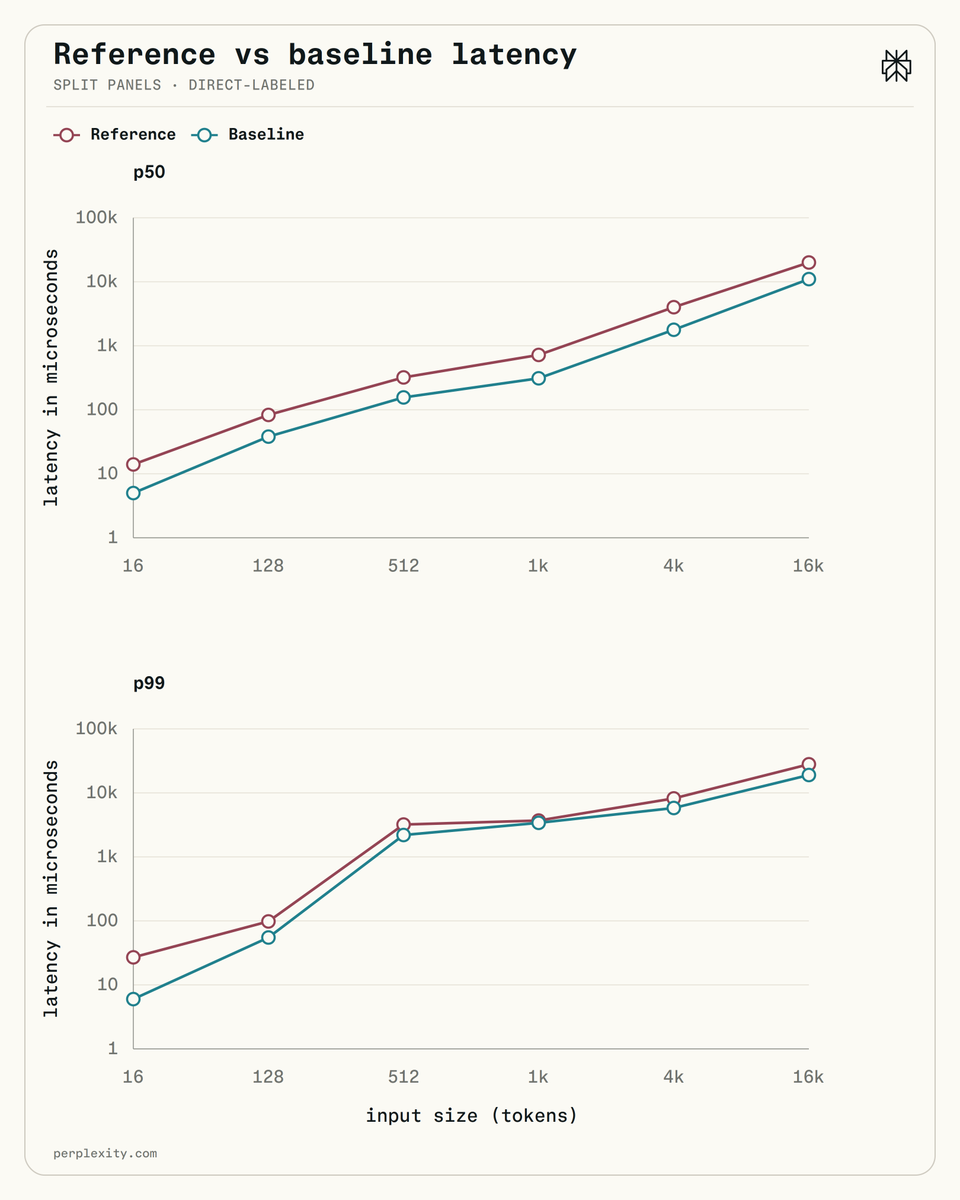
We're open-sourcing the Unigram tokenizer we rebuilt to reduce CPU utilization by 5-6x.
Small rerankers and embedders run in single-digit milliseconds on GPU, making CPU tokenization a meaningful share of total latency.
https://t.co/QUnHeiho56
🎉 Presenting at #MLSys2026 today!
fabric-lib: RDMA Point-to-Point Communication for LLM Systems
Talk by Nandor Licker at 3:15 PM. Poster 28 this evening — come say hi! 👋
We showcase three production applications:
🚀 KV-cache transfer for disaggregated inference.
⚡ RL weight transfer in 1.3 seconds for 1T-parameter models.
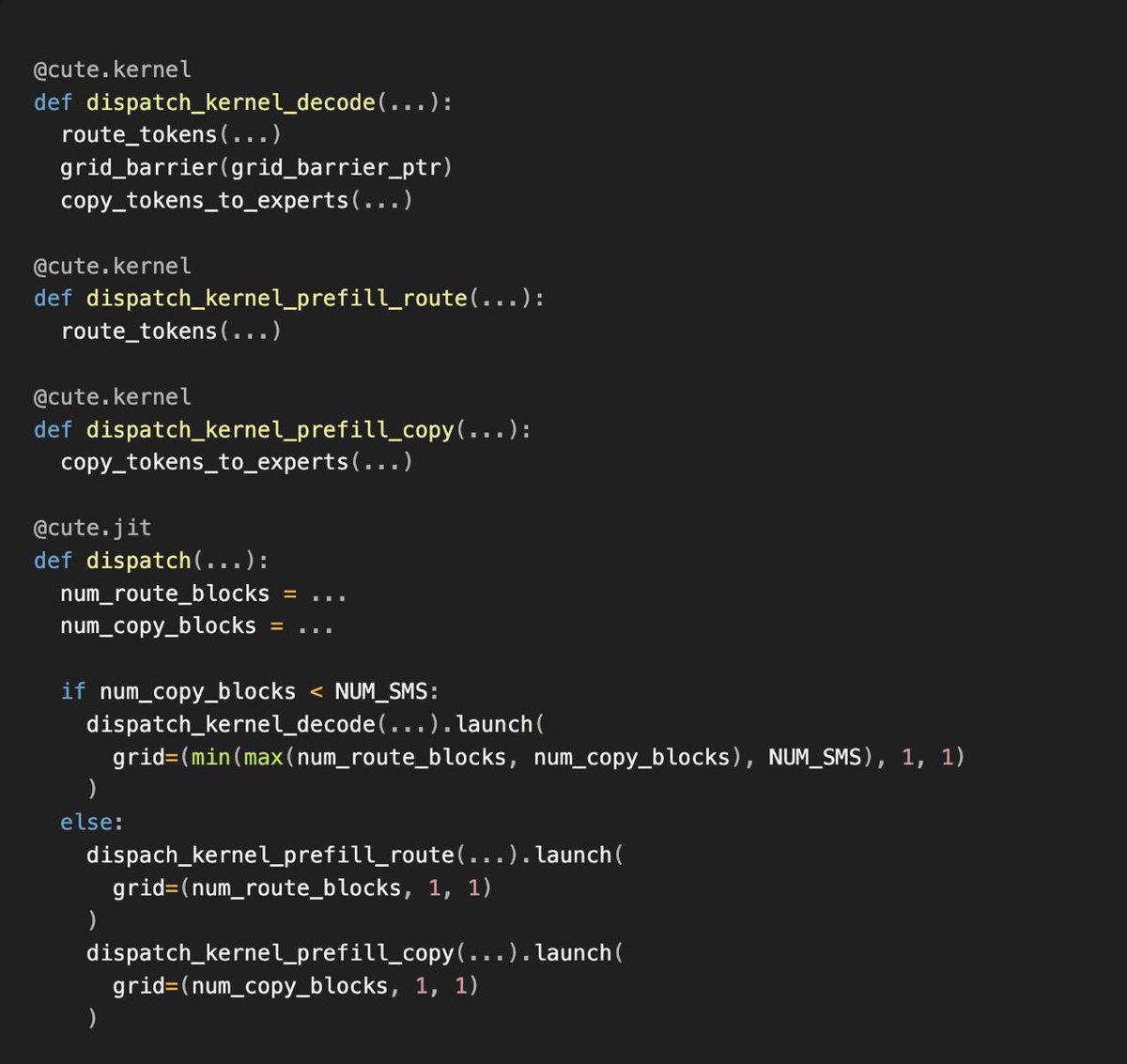
🔥 MoE dispatch/combine kernels — faster than DeepEP on ConnectX-7, fastest on EFA.
📄 Paper: https://t.co/Wech9mIqTr
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs.
With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to peak performance on NVIDIA Hopper and Blackwell GPUs.
@perplexity_ai Also check out our research paper accepted in #MLSys2026 fabric-lib: RDMA Point-to-Point Communication for LLM Systems https://t.co/Wech9mIqTr
#MLSys2026 is happening in two weeks! Our AI Infra team at @perplexity_ai is throwing a happy hour event at Bellevue on May 19. Come chat with us about inference, post-training, RL, kernels, GPUs, RDMA, agents, anything... https://t.co/mXf7laYt1s
@tskaerobot@Yuchenj_UW Upload all tax documents. Prompt "prepare my 2025 tax" and your information (like location, single or married, ...). Same as what you would send to CPA. (If you don't know which docs are needed, just ask it)
Wrote a blog post on why collective communication feels awkward for newer LLM workloads (disaggregated inference, RL weight update, MoE), why people don’t just use raw RDMA, how we approached it, and some behind-the-scenes stories. https://t.co/G0IiHo54qc
Faster than DeepEP for Decode on ConnectX-7. First viable kernel on EFA. SM-Free RDMA transfer. Support prefill. (Maybe portable to other hardware as well)
Perplexity is the first to develop custom Mixture-of-Experts (MoE) kernels that make trillion-parameter models available with cloud platform portability.
Our team has published this work on arXiv as Perplexity's first research paper. Read more:
https://t.co/SNdgWTeO8F
We divide the weight transfer process into pipeline stages to enable overlapped execution over different hardware resources (CPU->GPU memcpy, GPU computation, RDMA, Ethernet).