You too can build a workflow engine. Here's a blueprint on how to do it, which I've called "durable execution the hard way."
The first seven lessons are out now!
https://t.co/AFuCuL11v6
Did you ever hear the one about three workers who walk into an S3 bucket? They all processed the same object. 🥁 Ba dum tss.
(That's a really bad joke and also a bad thing that happens without concurrency control. We can't fix our sense of humor but we can help with the second part.)
Our new homepage is looking good! Also, as @abelanger5 mentioned, we've nearly doubled @hatchet_dev usage and revenue since the beginning of the year.
Big couple of months for us. 🚀
We've updated the @hatchet_dev landing page... again.
Why? In 2026, we've nearly doubled usage and revenue on the platform. We've also seen lots of new use cases and patterns when companies are adopting Hatchet, which we needed to better illustrate.
In particular, platform teams are using Hatchet to provide a set of guardrails for their product teams building AI workloads at scale (data ingestion and AI agents, especially).
We've seen platform teams take the primitives that Hatchet provides, like tasks, streaming, and observability, and compose them into more complex patterns.
As always, feedback is welcome.
@abelanger5 Our marketing can be a bit much sometimes, but is a good engineering content.
@abelanger5 is building a durable execution engine in 7 lessons. “Kubernetes The Hard Way” energy, but for workflow engines. If you care about orchestration, queues, etc. you will probably enjoy this.
I have many thoughts on the pitfalls of using Celery in Python applications based on years of personal experience and conversations with users.
So many in fact, that I wrote a blog post about them: https://t.co/LkV0ZXRWmP
We just published a guide for teams moving from Celery to Hatchet, including common Celery patterns, the Hatchet replacements, and what to watch out for.
Say Sláinte 🇮🇪 Bonjour 🇫🇷 Hola 🇪🇸 Hej 🇸🇪 Hallo 🇩🇪 to Hatchet EU! 🌍 We're now available in eu-west-1.
Sign up at https://t.co/4THKIooxu0 to get up and running.
It’s really nice to see Google launching AX https://t.co/N6Pqpoxkst
Agents are making async workflows, including durable execution, much more prominent. Running agents in production means a lot of unreliable RPCs, with all the consequences: retries, waits, rate limits, partial failures, and resuming work without duplicating expensive steps.
At @hatchet_dev, we bet that this is where the infrastructure is going.
🧵
Great to meet with the @SweetspotGov team! Sweetspot is using Hatchet for document processing pipelines, we spent some time today optimizing their setup for lower latency and scale.
Excited to see how far we can push Hatchet as they continue to ramp up their workflows. 🔥
New @hatchet_dev HQ in Brooklyn! We started with a 3-person space in January and outgrew it quickly.
Remote-first Hatchlings from across the EU and US (Boston, SF, Philadelphia, Amsterdam, and Luxembourg) are now regularly working in-person with us here in NYC.
we're hiring a growth engineer at @hatchet_dev!
if you're a talented, ambitious person looking to work in startup growth alongside truly world-class product engineering talent (who also happen to be brilliant, kind, and hilarious), here are a couple things you should know... 🧵
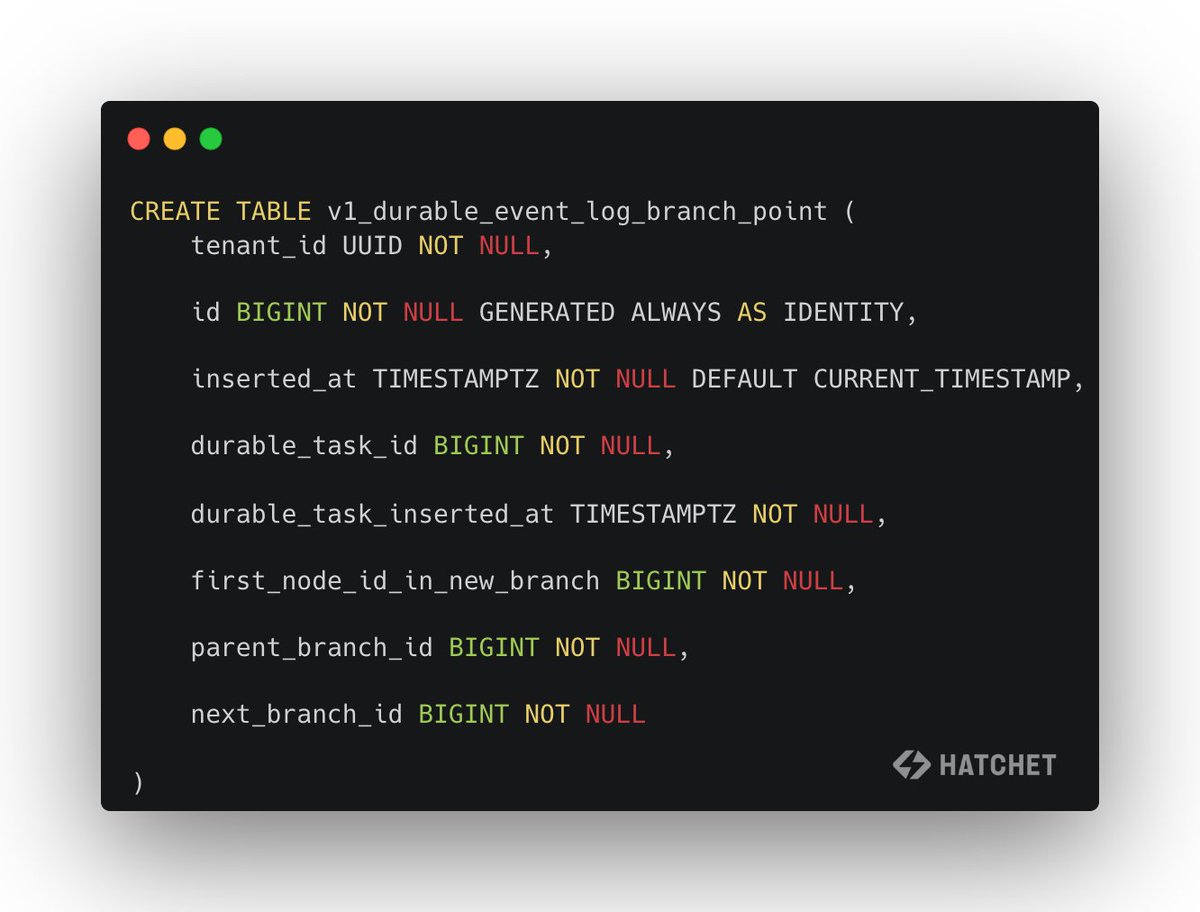
As a result, we actually model the durable event log as a *tree* in @hatchet_dev. Each branch of the tree represents a complete history, but you can fork from any point in an existing branch into a new branch.
This provides a lot more flexibility on replay and recovery, when starting from the beginning is expensive or non-tractable.💪
Most of the time, applications that rely on event sourcing will model the history as a linear and immutable log.
... Which is a good mental model, until you need to support replays! And there are two different types of replays:
1. Replay as new — clear the event history and start again. This is essentially a completely new run, and could be modeled as such.
2. Replay from an arbitrary point in the execution history. While this isn’t supported in every durable execution platform, we felt it was critical to support forking a durable task from a previous point in time. For example, perhaps the execution history relied on events which are no longer available in the system. How can you recover gracefully?