This is a terrible take.
Anthropic has been hiking $ per token with every model release, efficiency is not improving because 🤷♂️, and they don’t care because they need cash flow before IPO. And we’re supposed to throw MORE money at them?
anthropic should really just add a $500 plan
> 100% weekly limits instead of 50%
> fable stays available after july 7
> higher fable usage limits
so many people would get this
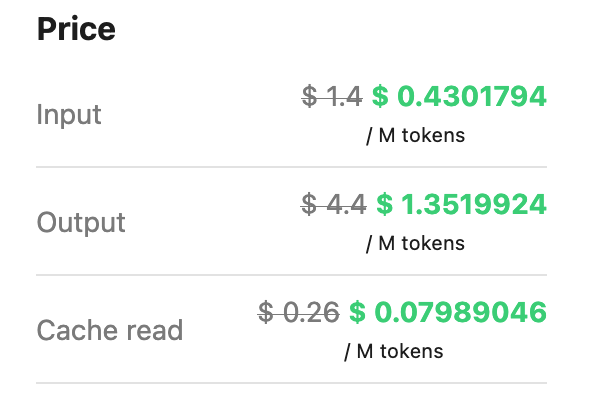
@kingofknowwhere You’re glancing over GLM-5.2 which blows most of those other Chinese models out of the water, and is very cheap if you know where to look https://t.co/BsXOaou3be
ps: ZenMux is a gateway, similar to openrouter. It has some input validation quirks that might 4xx some of your (normal) requests. Let me know if that is a common problem and I'll be able to help out..
Some are still asking, is the GLM 5.2 any good?
From my experience over last 2 weeks:
- I've hammered it with 800k+ context sessions, long-running planning, debugging and coding tasks.
- It's got great agency and follows instructions well, it's more eager to use tools and skills than GPT 5.5.
- It feels more like Opus - good attitude and to-the-point explanations, less chatty and verbose than GPT.
- For coding it feels more direct and effective than Opus, but comes short compared to GPT 5.5/5.4 (high and above) - makes mistakes more often.
- Design gives me mixed results. Requires a bit more guidance, but gives results similar to opus 4.6, better outcomes faster compared to GPT 5.4/5.5 models.
Compared to other open weight models:
- it executes much better than DS4Pro, gets lost less often and gets to results faster.
- it's slower but better coder than Kimi 2.7 and M3 esp. for complex, long-horizon tasks and problems
- Smarter than qwen3.6, but much slower in comparison. Diminishing returns with easier tasks.