Prediction: OpenAI is going to drop a "Memory Boost" add-on for ChatGPT soon.
With Dreaming V3 storing way more background context, power users are hitting a wall. Expect a "$20/mo for 10x Memory Capacity" tier before the end of the year. Context is the new cloud storage.will
I’ve been using ChatGPT since it first became available in my region.
I started using Claude as soon as I read about it. I used Claude Code before Codex was available, and I started using Codex within 1 or 2 days of getting access.
For the past 6 or 7 months, I paid for the $200 plans for both Claude and ChatGPT so I would not have to think about limits.
The limits were not the problem.
Work quality, consistency, and trust were the problem.
When I first used Codex, I noticed real issues. Some were major. One example was context pollution: I would ask it to edit, review, or plan something based on the current codebase, and even when explicitly instructed, it would sometimes rely on cached or outdated assumptions instead of the updated files.
That made it difficult to trust for serious project work.
Things changed a lot with the 5.4 update, especially for code review, implementation planning, and verification tasks. I started using it more seriously to check whether the code written by other agents actually matched the scope, architecture, and product intent.
5.4 Spark was strange. At first, I genuinely thought “life changing.” But once I placed it inside my actual workflow, on tasks that previous models could handle without much trouble, it sometimes entered non-ending loops and became hard to control.
And now we are here, in May 2026, with Codex and 5.5.
The difference between Claude Opus 4.7 and 5.5, for the kind of work I do, feels like the difference between an overconfident generalist and a cold, calculated expert.
Planning, analysis, system design, logical fallacy detection, code dynamics, blast-area reasoning, review discipline, and scope control are all on another level.
The biggest difference is not that 5.5 writes more code.
It is that it can hold a large, messy project context, reason through it, identify what should not be changed, and produce structured plans that a local coding agent can actually execute without destroying adjacent systems.
That was not reliably possible for me with earlier models.
I now use Codex/5.5 for large investigation files, implementation plans, code reviews, architecture consistency checks, admin-panel upgrade planning, Prisma/Next.js blast-area analysis, and verification prompts across a real production SaaS codebase.
Some of these tasks involve absurdly large context windows: codebase maps, governance files, investigation docs, plan files, review files, schema files, route files, UI components, API paths, and previous failure logs.
Earlier models could read some of that.
5.5 can actually work with it.
There is no practical way for me to return to Claude Code for a large category of the tasks I now rely on Codex for.
So yes, you did good.
Better than I expected.
Just saw Codex waste a bunch of time on a basic markdown rewrite because it kept fighting the edit tool. The task was simple, just updating a report file, but it tried to delete and recreate the whole thing through apply_patch instead of just editing the text. The delete kept failing with an error but it just kept retrying the same move over and over again.
The fail was really more procedural than technical. A tiny update worked so the file was obviously editable, but Codex just choked on that full delete/add operation. It should have switched to smaller patches or a different overwrite method immediately instead of stalling. Big takeaway from the report is that when a tool proves a file is editable but one specific op fails, the agent needs to stop repeating the mistake and change tactics. For .md files especially it should just use the smallest write path possible instead of wasting operator time fighting the mechanism.
ChatGPT’s web interface really needs an artifact collapse or virtualization feature. When a single session accumulates multiple high-density artifacts, the DOM overhead becomes massive. The browser's main thread eventually chokes trying to manage the state and rendering of several large code blocks or previews simultaneously, leading to frequent tab freezes.
I've noticed that once you get 4 or 5 of these things open, the whole tab just stops responding. A compact mode or some kind of lazy loading for old artifacts would solve the memory pressure issues for long-form technical sessions. Right now, it feels like the browser is fighting for its life just to scroll. OpenAI should really prioritize this because it's making the power user experience pretty frustrating when the UI hangs every couple of mins.
Codex is not perfect.
But after switching from Claude Code with Opus 4.7 to Codex for real project work, the difference has been obvious.
For context: I spent roughly a week trying to push through DevOps and implementation sessions with Opus 4.7. The result was a lot of friction, repeated context loss, overconfident wrong moves, and scope drift.
After 3-4 days using Codex instead, the practical differences were hard to ignore.
Codex seems to understand the initial scope of a task better. More importantly, it stays inside that scope. It does not constantly expand the problem, redesign adjacent systems, or turn a focused fix into a philosophical migration plan.
When it hits unknowns, it is also more willing to stop and inspect. That matters. In a real codebase, “I need to check the file” is infinitely better than inventing structure, hallucinating missing code, or pretending the architecture is obvious.
The biggest difference for me is context excavation.
Using the same project documentation and the same source material, ChatGPT/Codex retrieved the important information faster, anchored it more accurately, and structured it closer to the requested format.
Opus 4.7, inside Claude projects, repeatedly ignored parts of the instructions, missed relevant context, and when something was not present in the docs, it often filled the gap with its own interpretation.
That sounds harmless until you are working inside a live SaaS codebase.
Then it becomes expensive.
The core issue is not that one model makes mistakes and the other does not. They both make mistakes.
The issue is how they fail.
Codex fails more like a cautious engineer: checks files, asks for evidence, narrows the next action.
Opus 4.7 often failed like a very confident consultant who read half the brief and started designing the department.
For writing, brainstorming, and broad analysis, I still see value in Claude.
But for codebase work, project management, implementation planning, DevOps debugging, and anything where file reality matters more than elegant reasoning, Codex has been much more usable so far.
A model does not need to sound brilliant.
It needs to stay grounded, preserve scope, and stop guessing when the answer is on disk.
Codex pulls ahead specifically because of how it handles plan mode. Competing CLI agents try to interleave reasoning and code execution into one continuous output stream. That approach inevitably poisons the context window with intermediate execution debris. Once the agent is forced to read its own failed execution attempts, it starts generating corrections based on broken logic.
Longer context windows can make a model feel worse, not better. You get more room for irrelevant carryover, so the answer starts dragging yesterday's bad assumptions into today's prompt.
Then the newer stop-and-ask behavior makes it look hesitant instead of careful. Frontier models optimized to check before acting will always expose more mid-answer uncertainty. But that reads as incompetence when it's actually just the model refusing to bluff as hard as older versions did,
Claude Opus 4.7 is a nightmare.
This is the classic Safety Theater Regression - when AI models get "safer" by becoming less useful at everything. This is the textbook case where aggressive safety training turns a capable tool into something that argues with you instead of helping.
Pushing safety reward signals to their max triggers a 91% false refusal rate on benign queries, according to recent arXiv data on the alignment tax. This explains the safety theater regression you're seeing with Claude.
And the "HARD STOP protocol" you're hitting is part of a massive over-correction across the entire AI development space where companies care way more about dodging theoretical bad PR than keeping the tool useful for people doing actual work. Anthropic's own data actually shows 35-40% higher token consumption for worse performance on routine tasks despite benchmark bumps that mean nothing for real workflows.
What's frustrating is how this safety theater adds friction without making the model safer in any real way.
41 kidnappings of crypto holders in France in 3.5 months of 2026.
Why?
🥖 French tax officials selling crypto owners' data to criminals (Ghalia C.) + massive tax database leaks.
Now the state also wants IDs and private messages of social media users.
More data = More victims.
"so you staked your ETH on the Ethereum blockchain to earn yield?"
"yes, Dave"
"except you didn't want your capital to be locked up so you actually staked it with a liquid staking protocol called Lido?"
"that's correct, Dave"
"and Lido gave you a liquid staking receipt token called stETH in return?"
"yes, Dave"
"and then you didn't think that was enough, so you juiced the yield even further by depositing your stETH receipt tokens into a restaking protocol called Eigenlayer?"
"you are correct, Dave"
"and now you didn't want to lock up your capital, so you actually restaked with a liquid restaking protocol called KelpDAO who provided you with a liquid restaking receipt token called rsETH?"
"you got it, Dave"
"and then that was surely not enough juice, so you then deposited your rsETH tokens into a lending protocol called AAVE so that you could open a leveraged looping position that borrows ETH against the rsETH collateral and restakes the ETH into rsETH which is then deposited as collateral, except it turns out rsETH used a cross-chain bridge called LayerZero whose security is held together by a 1/1 toothpick, which was obviously hacked by north koreans causing rsETH to become undercollateralized and now these looping positions are stuck and unprofitable, and everyone is pointing fingers at each other, and also DeFi is a very serious industry"
"you are 100% correct, dave"
jfc.
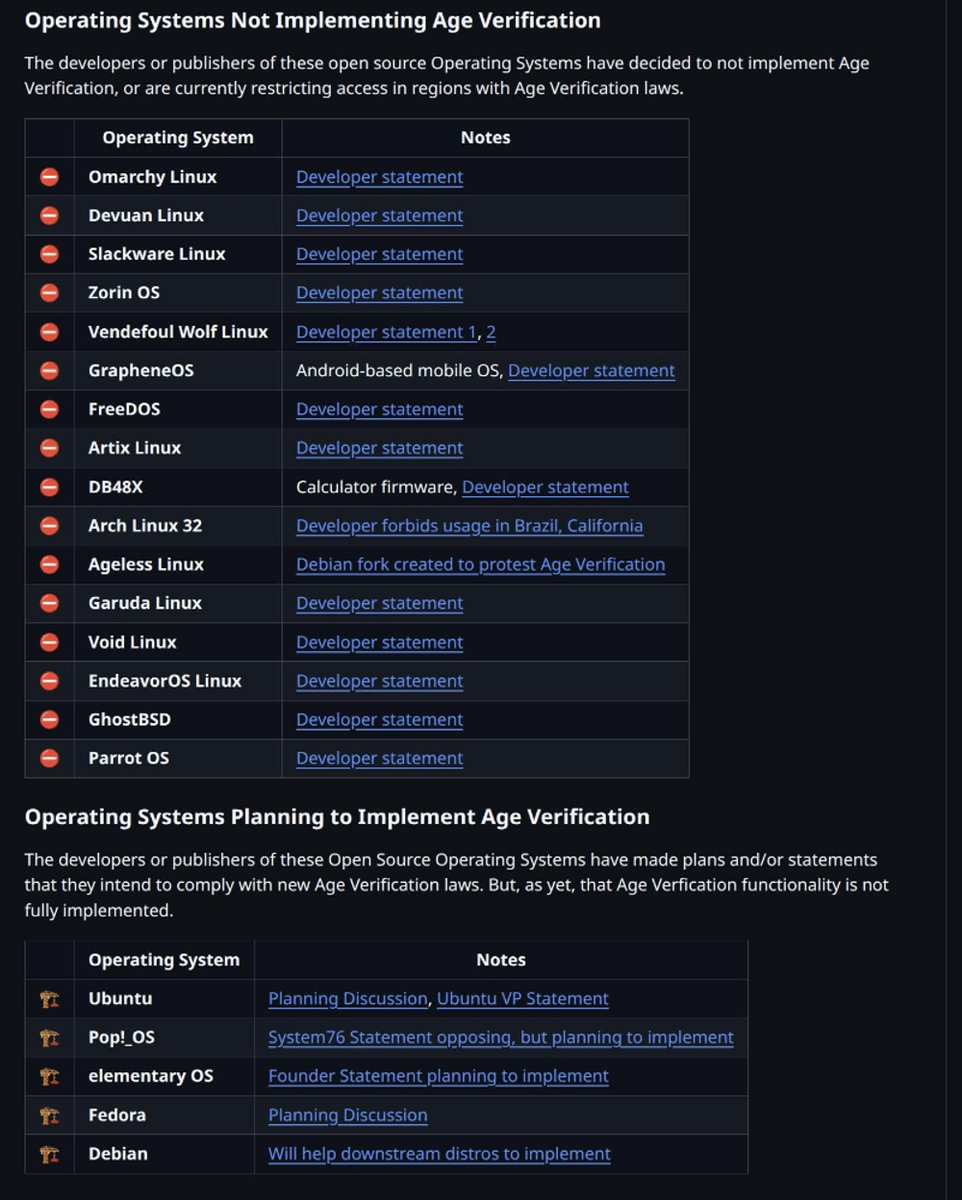
The fact that the first list is longer than the second list by itself is actually kind of reassuring.
The fact that we even need these lists is pathetic.
The median age in the U. S.
Senate is 65.3 years, per Pew Research - meaning the people who will write AI governance were born before pocket calculators existed. The 99.9% framing is actually too optimistic, because it implies the informed 0.1% are the ones setting the rules. They're not. The governing layer - senators, central bank economists, enterprise procurement officers deciding which AI systems get embedded into critical infrastructure - is mostly inside that 99.9%, and those are the people who will determine the shape of this race, not just watch it.
@trikcode Every week your product sits in draft someone else's early users are generating the words, edge cases, and specific complaints that become their landing page copy, long-tail SEO, and their FAQ.
The unsettling part of Altman's brain-upload bet isn't that it's crazy - it's that it makes sense given every single other thing he believes. Accepting death for a future payoff is the same as the OpenAI operating logic where you take near-term hits for long-term upside.
He isn't moving away from his professional logic, he's just applying it to his own body. That isn't instability - it's revealed preferences and the coherence is the scary part. But the "stability" framing is the easy way out because it lets you dismiss the guy without looking at the framework. The separate problem is that the Nectome approach produces a copy instead of a continuation. No neuroscience consensus supports the idea that the upload is