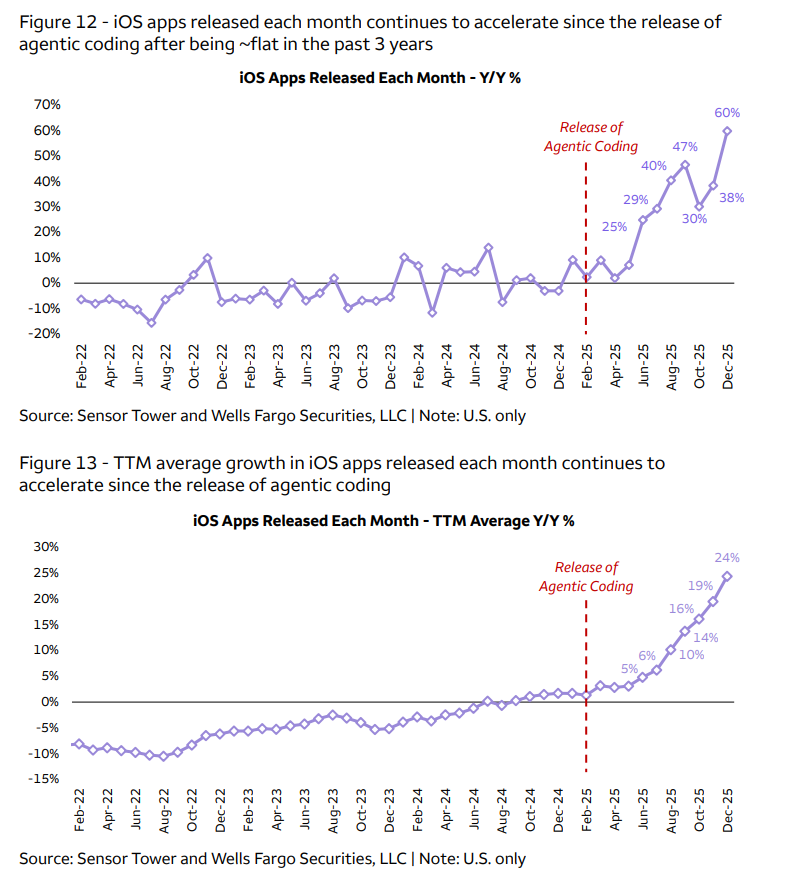
시장은 CPO라는 단어는 알지만, 아직 CPO 공급망은 제대로 이해하지 못하고 있다고 본다.
요즘 AI 인프라 투자에서 광학은 이미 가장 뜨거운 테마 중 하나다.
광모듈, 광부품, 레이저, 실리콘 포토닉스, CPO 관련주들이 크게 움직였고, 이제 대부분의 투자자들도 co-packaged optics라는 단어는 들어봤다.
그런데 단어를 아는 것과 돈이 어디로 흘러가는지 아는 것은 완전히 다르다.
CPO를 쉽게 말하면, 스위치 칩 근처에 광학 부품을 더 가까이 붙여서 전력 소모를 줄이고 대역폭을 키우려는 구조다.
AI 데이터센터가 커질수록 GPU와 서버 사이를 오가는 데이터가 폭증한다.
기존 pluggable 광모듈만으로는 전력, 대역폭, 지연시간 문제가 점점 커진다.
그래서 스위치 ASIC 가까이에 optical engine을 붙이는 CPO가 등장한다.
다만 여기서 구분이 필요하다.
지금 말하는 CPO는 주로 scale-out networking 쪽이다.
즉 AI 클러스터 안에서 스위치와 서버를 연결하는 네트워크 레이어다.
반면 Ayar Labs, Marvell, NVLink Fusion 같은 scale-up optical I/O는 GPU/XPU 패키지 가까이로 광연결이 더 깊게 들어가는 장기 흐름에 가깝다.
둘 다 광학 병목이라는 큰 흐름 안에 있지만, 같은 제품도 아니고 같은 타이밍도 아니다.
이걸 구분하지 않으면 CPO 뉴스 하나에 모든 광학주를 한 바구니로 사고파는 실수를 하게 된다.
CPO는 단일 부품이 아니다.
공급망 전체로 봐야 한다.
크게 보면 세 개의 레이어가 있다.
첫째, 빛을 만드는 레이어.
둘째, 그 빛에 데이터를 싣는 레이어.
셋째, 모든 것을 패키징하고 연결하고 검사하는 레이어다.
빛을 만드는 레이어
AI 데이터센터가 커질수록 더 많은 광신호가 필요하다.
그리고 광신호의 출발점은 레이저다.
이 레이어는 다시 InP 기판, 에피택시, 고출력 레이저, ELS로 나뉜다.
InP 기판은 레이저의 원재료에 가깝다.
대표 기업은
AXT(AXTI)
Sumitomo Electric(5802.T)
JX Advanced Metals(5016.T)다.
에피택시는 InP 기판 위에 정밀한 층을 쌓아 레이저 웨이퍼를 만드는 단계다.
여기에는
IQE(IQE.L)
LandMark(3081.TWO)
VPEC(https://t.co/MYJp30E1mq)가 연결된다.
이 공정에 필요한 MOCVD 장비는
Aixtron(https://t.co/mxeqWLqeCa)이 중요하다.
기판과 에피가 늘어나면 장비 주문이 먼저 움직일 수 있기 때문에, Aixtron은 upstream capex를 보는 장비주에 가깝다.
그다음은 고출력 레이저와 ELS다.
ELS는 External Laser Source, 즉 레이저를 스위치 패키지 밖에 따로 두고 빛을 공급하는 모듈이다.
CPO에서는 스위치 ASIC 주변이 뜨겁기 때문에 레이저를 패키지 밖으로 빼는 구조가 중요하다.
이쪽에는
Lumentum(LITE)
Coherent(COHR)
AAOI(AAOI)
Sumitomo Electric(5802.T)
Sivers(https://t.co/W51pdjvYWt)가 걸린다.
Lumentum과 Coherent는 고출력 laser/ELS 쪽에서 가장 직접적인 대형주에 가깝다.
AAOI는 transceiver와 ELSFP 양쪽에 발을 걸친 이름이다.
Sivers는 DFB laser array와 ELS 쪽 옵션이 있는 소형주로 볼 수 있다.
다만 Sivers를 Nvidia 확정 공급사처럼 말하면 안 된다.
현재 공개적으로 안전한 표현은 CPO, LPO, optical I/O용 laser array와 ELS 공급망에 옵션이 있는 회사 정도다.
내가 이 빛을 만드는 레이어를 중요하게 보는 이유는 단순하다.
CPO가 조금 늦어져도 이 수요가 완전히 사라지기 어렵다.
LPO가 시간을 벌든, 기존 pluggable 광모듈이 더 오래 버티든, AI 클러스터가 커질수록 더 많은 빛은 필요하다.
그래서 InP, epi, laser, ELS는 CPO 순수도는 낮을 수 있어도 구조적으로 더 강한 병목에 가깝다.
빛에 데이터를 싣는 레이어
빛만 만든다고 데이터가 이동하는 것은 아니다.
그 빛에 실제 신호를 실어야 한다.
여기가 SOI wafer, PIC foundry, optical engine, modulator가 들어가는 레이어다.
SOI wafer는 silicon-on-insulator다.
실리콘 안에서 빛이 새지 않고 waveguide를 따라 움직이게 하려면 특수한 SOI 기판이 필요하다.
여기서는 Soitec(https://t.co/I7E5afSs88)이 가장 직접적인 이름이다.
그다음은 PIC foundry다.
PIC는 photonic integrated circuit, 즉 빛을 다루는 반도체 칩이다.
여기에는
Tower Semiconductor(TSEM)
TSMC(TSM / https://t.co/rPCjYczoy6)
GlobalFoundries(GFS)
UMC(UMC / https://t.co/ULCuj90UgN)
Samsung Electronics(005930.KS)가 연결된다.
Tower(TSEM)는 open silicon photonics 쪽에서 봐야 한다.
중요한 건 Tower가 단순히 “CPO 선급금”을 받은 게 아니라, SiPho capacity reservation과 customer prepayment가 찍힌 회사라는 점이다.
이 수요는 pluggable, NPO, CPO를 포함한 broader optical connectivity 수요와 연결된다.
TSMC(TSM)는 COUPE와 SoIC를 통해 CPO를 advanced packaging과 묶는 핵심 플랫폼이다.
Nvidia의 초기 scale-out CPO ramp와 가장 밀접하게 봐야 하는 이름 중 하나다.
GlobalFoundries(GFS)는 GF Fotonix와 SCALE CPO/LPO reference design 쪽으로 보면 된다.
Sivers 투자자 입장에서는 GF와의 reference design 흐름 때문에 계속 봐야 하는 이름이다.
UMC와 Samsung은 후발 silicon photonics / CPO 서비스 후보에 가깝다.
지금 당장 핵심 승자라기보다, 후속 생태계 확장 관점에서 보는 게 맞다.
Optical engine과 optical I/O 쪽은 업사이드가 크지만 리스크도 크다.
여기에는
Broadcom(AVGO)
Marvell(MRVL)
Credo(CRDO)
POET Technologies(POET)가 있고
비상장으로 Ayar Labs와 Lightmatter가 있다.
Broadcom(AVGO)은 Tomahawk 스위치 ASIC과 CPO switch platform 쪽에서 중요한 이름이다.
Marvell(MRVL)은 Celestial AI 인수와 NVLink Fusion 생태계 진입으로 scale-up optical interconnect 쪽 옵션이 커졌다.
Credo(CRDO)는 DustPhotonics 인수로 silicon photonics optical engine 쪽 노출을 확보했다.
POET(POET)는 optical interposer 기반 접근이다.
맞으면 업사이드는 크지만, 아직은 검증 리스크가 큰 고위험 옵션에 가깝다.
Ayar Labs는 비상장이지만 scale-up optical I/O에서 중요한 이름이다.
Lightmatter도 photonic interposer와 optical interconnect 쪽에서 봐야 한다.
이 레이어는 가장 흥미롭지만 가장 조심해야 한다.
모든 구조가 동시에 이길 수는 없기 때문이다.
TSMC COUPE가 주도할지,
Tower의 open SiPho가 얼마나 커질지,
Broadcom의 CPO switch platform이 어디까지 확장될지,
Ayar Labs식 optical I/O가 Nvidia 생태계 안에서 얼마나 깊게 들어갈지,
POET, Credo, Marvell, Lightmatter의 방식이 얼마나 채택될지는 아직 모두 확정된 게 아니다.
그래서 이 구간은 torque가 크지만 architecture risk와 design-win risk도 크다.
연결하고 조립하고 검사하는 레이어
시장이 가장 덜 보는 구간이 여기라고 생각한다.
많은 사람들은 GPU, HBM, 스위치, 광엔진만 본다.
하지만 CPO 양산에서 정말 어려운 부분은 패키징, 정렬, 수율, 테스트다.
빛은 전기보다 훨씬 예민하다.
아주 작은 정렬 오차도 loss로 이어진다.
connector 품질이 안 나오면 삽입 손실이 생기고,
fiber routing이 불안정하면 신뢰성 문제가 생기고,
hybrid bonding이 흔들리면 수율이 깨지고,
thermal drift가 커지면 장기 안정성이 떨어진다.
그래서 CPO에는 테스트와 검사 단계가 계속 붙는다.
Known-good engine.
Wafer sort.
Burn-in.
Optical alignment.
Hybrid bonding inspection.
Connector loss measurement.
System-level test.
전기 신호는 pass/fail로 끝나는 경우가 많지만, 빛은 loss, noise, coupling, alignment, power budget 같은 연속적인 변수의 세계다.
그래서 optical content가 늘어날수록 test intensity도 구조적으로 올라간다.
패키징과 OSAT 쪽은 TSMC(TSM)
ASE Technology(ASX / https://t.co/zqIGnLhPmA)
Amkor(AMKR)
Samsung Electronics(005930.KS)가 연결된다.
TSMC는 COUPE/SoIC로 가장 직접적인 플랫폼이다.
ASE와 Amkor는 OSAT 및 advanced packaging 인접 후보로 보면 된다.
Samsung은 후발 CPO/turnkey packaging 후보에 가깝다.
광섬유, 커넥터, micro-optics 쪽은
Corning(GLW)
Sumitomo Electric(5802.T)
Fujikura(5803.T)
Furukawa Electric(5801.T)
FOCI(3363.TWO)
Browave(3163.TWO)
TFC Communication(https://t.co/e9vXbJN38m) 등이 있다.
이 중 Corning(GLW)은 가장 공개적으로 확인되는 광연결 수혜주 중 하나다.
Nvidia가 Corning과 optical connectivity capacity를 크게 확대하기로 한 것은 중요한 신호다.
플랫폼 업체가 직접 capacity를 잡는다는 것은 그 부품이 단순 부품이 아니라 병목 후보라는 뜻이다.
시스템 조립은
Fabrinet(FN)
Celestica(CLS)
Foxconn/Hon Hai(https://t.co/lxxxSbrG6g)
Jabil(JBL)이 연결된다.
다만 이 구간은 보통 마진이 얇고, CPO 순수 노출로 과장하면 안 된다.
거래량과 물량 흐름이 먼저 보이는 인접 레이어 정도로 보는 게 맞다.
테스트와 검사 장비는
Advantest(6857.T)
Teradyne(TER)
Keysight(KEYS)
Viavi(VIAV)
FormFactor(FORM)
AEHR Test Systems(AEHR)
Onto Innovation(ONTO)
Camtek(CAMT)이 연결된다.
여기도 전부 CPO 순수주는 아니다.
하지만 CPO가 커질수록 optical test, burn-in, wafer probing, hybrid bonding inspection, system-level validation의 중요성이 올라간다는 방향은 분명하다.
개인적으로 이 test/inspection 레이어는 시장이 아직 충분히 가격에 반영하지 못한 구간이라고 본다.
결국 투자 관점에서 봐야 할 질문은 하나다.
“누가 CPO 관련주인가?”
이 질문은 너무 넓다.
진짜 질문은 이거다.
AI 인프라가 더 많은 빛을 필요로 할 때, 반드시 돈을 받는 레이어가 어디인가?
CPO가 빨리 와야만 돈을 버는 레이어가 있고,
CPO가 조금 늦어져도 optical demand 자체가 커지면 살아남는 레이어가 있다.
Optical engine, COUPE packaging, CPO-specific connector는 CPO 침투율이 올라갈 때 torque가 크다.
대신 timing risk와 design-win risk가 있다.
반대로 InP substrate, epi, MOCVD, high-power laser, ELS, fiber, optical connectivity, test equipment는 CPO 순수도는 낮아도 더 resilient하다.
AI 데이터센터가 커지는 한 더 많은 대역폭이 필요하고,
더 많은 대역폭은 더 많은 optical link를 요구하고,
더 많은 optical link는 더 많은 빛, 더 많은 fiber, 더 많은 packaging, 더 많은 test를 요구하기 때문이다.
그래서 앞으로 광학 투자 2라운드는 단순히 “CPO 관련주 사자”가 아니라고 본다.
1라운드는 AI가 더 많은 광연결을 필요로 한다는 걸 먼저 이해한 사람들이 먹는 구간이었다.
2라운드는 더 어려울 것이다.
이제는 병목과 동행자를 나눠야 한다.
어디에 customer prepayment가 들어오는지,
어디에서 capacity reservation이 찍히는지,
어디에서 장비 주문이 나오는지,
어디에서 증설 자금이 들어가는지,
어디를 Nvidia 같은 플랫폼 업체가 직접 확보하려 하는지,
어디가 실제 양산에서 수율을 좌우하는지 봐야 한다.
시장은 아직 CPO를 하나의 테마로 본다.
그래서 CPO 지연 뉴스 하나에 광학주 전체가 흔들리고,
Nvidia 로드맵 하나에 다시 전체가 움직인다.
하지만 실제 돈은 테마 전체로 똑같이 들어가지 않는다.
돈은 병목으로 간다.
내가 보는 AI 인프라 병목의 이동은 이렇다.
GPU에서 HBM으로.
HBM에서 networking으로.
Networking에서 optical interconnect로.
Optical interconnect에서 laser, fiber, packaging, test로.
CPO는 그 흐름의 한가운데 있다.
중요한 건 누가 CPO라는 단어를 쓰느냐가 아니다.
AI 인프라가 더 많은 빛을 필요로 할 때, 반드시 돈을 받는 레이어가 어디냐는 것이다.
개인 투자 기록용.
투자 조언 아님.
AI “trainers” for finance are getting up to $25k / day to teach AI applications
Useful application of AI for pod shops and other analysts = instant model updates based on live earnings call transcripts:
“Sinisterra, 30, then walked the class through how to scan transcripts from earnings calls with OpenAI's ChatGPT and Anthropic's Claude to find the most market-moving statements. The machine ran sentiment analysis and translated management’s spoken remarks into numerical spreadsheet inputs to forecast future financials. Participants could see how AI could help streamline some of the most labor-intensive parts of their jobs.”
Wild how fast AI is changing the landscape
호들갑이 아니라 이 글은 요약 없이 원문을 꼭 읽어보는 것을 추천함
-사업체가 돈을 버는 맥락
-인간이 병목이 되는 이유
-기업 노하우란 것의 본질
-새로운 기술이 제대로 쓰이는 방향 (반대로 잘못 쓰이는 방향도)
아주 실질적으로 짚어주는 글임.
하지만 읽는 게 어렵다면.. 요약본은 아래와 같음
---
- 회사(특히 전문성 기반 회사)의 전통적 수익 구조는 일감을 가져온 뒤 하위 인력에게 나누어주고(delegate) 수익이 비용보다 크게 하는 방식
- 원문에서는 이를 '조직적 레버리지'라고 부름. 수익은 “개인의 순수 생산성”보다 조직의 레버리지 구조에 비례해서 올라가는 형태
- 이 구조가 필요한 이유는 복잡한 업무를 한 사람이 전부 인지하고 처리하기 어렵기 때문이다 (잠은 자고 밥은 먹어야지)
- 인간은 긴 문서 소화, 정보의 다층 관계, 상호작용 조항을 동시에 다루는 데 한계가 있음 (인지적 병목)
- 그래서 기존 조직은 인지 병목을 분업과 위계로 해결했다 (사람 수로 해결)
- 근데 분업과 위계 체계 만들어놓으면, 사람과 사람 커뮤니케이션 중 맥락이 희석되어 사라짐... (AI에서 많이 들어봤을 컨텍스트 문제)
- AI는 바로 이 병목, 즉 컨텍스트 압축 문제를 완화한다
- 결과적으로 뛰어난 상위 실무자가 과거 팀 전체가 하던 작업을 훨씬 더 직접적으로 수행할 수 있다
- 이건 단순 자동화가 아니라, 판단력의 전달 손실(delegate tax) 을 줄이는 변화임
- 여태까지 테크회사에서 돈 엄청 태우면서 만들어놓는 '솔루션형 프로덕트'들 (aka SaaS)는 그 도구의 능력의 한계가 작업물 퀄리티의 상한선이 된다
- 검수에는 도움이 될지 몰라도, 퀄리티의 제한은 너무 명확한 한계점..
- 하지만 AI로 인해 한 사람이 다룰 수 있는 컨텍스트의 폭과 압축 효율은 어마어마하게 높아졌음
- 상위 실무자가 더 직접적으로 문제를 처리하게 만드는 기술
- 큰 조직일수록 '회사의 노하우'따윈 사실 없음. 개인들이 가진 지식의 집합일 뿐임.
- 그래서 맥락 희석이 치명적임.
- AI를 네이티브하게 활용하고 과정을 고민하는 사람은 이 문제로부터 자유로울 수 있음
- 심지어 AI를 쓰는 (컨텍스트와 업무 지시를 극도로 효율적으로 압축하는) 경험이 풍부한 사람은 실력도 비례해서 증가함
The upcoming Market Wizards book is approaching completion. As such, @jackschwager and I have decided to release the names of the traders included in the book and their associated X handles. Here they are:
Kristjan Kullamägi @Qullamaggie
Lance Breitstein @TheOneLanceB
Simon Russo @simonrusso__
Lukas Fröhlich @TheShortBear
Phil Goedeker @Tradestl
Kelvin Chiu @KC_SilverCape
Jason Berry @Positive_Equity
Kenny Sharkness of @smbcapital (Kenny has no public X account)
Rick Bandazian Jr. @Off_The_Tape
Looking forward to sharing the book with the world!
If you'd like to pre-order the book, you can do so here: https://t.co/yJ9wjrw9Pp
For discounted bulk orders (US only) go here: https://t.co/gJoKIF2dr5
Feels like some important context was left off here... The HBM shortage/bottleneck is only half of the message. Below is the full response the SMIC CEO gave re the current memory shortage (translated using chatgpt). If the commodity DRAM and NAND shortage for PC and smartphones in China can be alleviated by CXMT and YMTC, that domestic supply response will affect the entire global memory market. Do not let anyone convince you that China and ex-China are separate markets for commod DRAM and NAND.
$MU $SNDK SK Hynix Samsung
[translation]
NAND Flash or DRAM (whether 32GB of DRAM or 64GB) — everyone says “the more, the better.” Essentially, what we are discussing is whether a minimum configuration is sufficient.
There are two things happening right now. One is that everyone’s compute capacity is insufficient, because there are very ambitious visions for artificial intelligence (AI). People would like to build, in one or two years, all the data centers that would otherwise be needed over the next ten years. As for what, exactly, those data centers will be used for once built, that is not fully thought through; but there is a belief that they will definitely be needed. It is like building high-speed rail stations or highways: even if in reality it should take ten or twenty years, people feel they cannot wait that long and want to build it now. Therefore, for AI-related demand, within a certain time window it will never be fully satisfied. You cannot simply “build it all at once” by making heavy investments in memory — investing in both the front-end and back-end to produce high-bandwidth memory (HBM). This shortage should persist for several years.
But the other thing I mentioned is that, in another respect, wafer equipment suppliers and wafer-fab construction are relatively fast. They can ramp wafer output for memory fairly quickly. However, new equipment and new fabs still require a long time to be qualified and validated for use in AI data centers. That means this additional capacity cannot immediately solve AI data-center demand, but it can help satisfy demand for consumer electronics: personal computers and smartphones. Right now, some smartphone and PC capacity has been diverted to AI because those are existing fabs. Once new fabs are built, they cannot serve AI (AI will still be short of HBM), but memory supply for phones and PCs will gradually become sufficient; distributors will no longer need to hoard inventory, and the overall supply chain will run more smoothly. This can be alleviated relatively quickly, and the speed of that easing depends on how quickly equipment companies deliver tools.
Based on historical equipment delivery timelines:
-Roughly the top one-third of orders (highest priority) can be delivered in about 4–5 months.
-“Normal priority” orders are delivered in about 7–8 months.
-The slowest (lowest priority) can still be delivered in about 12–16 months.
As that capacity comes online, it will first go to fill consumer demand. So we have a forecast: as this capacity is gradually released, those channel players who have been hoarding inventory will also release their stock. This is a “double whammy” (a twofold effect). At that point, there may be a turning point: end-device shortages for phones will ease, and PC shortages will ease.
If we align that timing with equipment delivery, capacity release, rapid qualification/ramp (“run mark”), and the release of hoarded channel inventory, we estimate roughly 9–12 months. Speaking personally, I think this is still relatively fast. So it is possible there will be some reversal as early as the third quarter of this year. As we said earlier, we are advising Semiconductor Manufacturing International Corporation (SMIC) customers not to stop lines and not to reduce output on their own; instead, it is better to build sufficient inventory in preparation for a third-quarter reversal.
[then he goes on to talk about the quoted HBM backend bottlenecks:]
However, on the AI side, what is needed is high-quality HBM, and that side’s delivery cycle is much slower than the front-end. For example, processes such as chamfering, backside thinning, and slicing have very slow capacity expansion. So looking out about a year, if we are still discussing constraints, it is possible that the biggest constraint for HBM AI memory will no longer be the wafer fab at the front end. Even if you devote wafer-fab capacity to AI, it does not help much, because the bottleneck is not in the front end — it is in the back end. Final test (FT) is very slow when so many wafers are stacked together; yield improvement is very slow; and quality validation is even slower. That is the bottleneck, and it cannot be relieved quickly in the short term. As a result, the leading position remains with the few largest players who started HBM earlier. New fabs built later will not be able to capture HBM’s profits as quickly, but they can immediately address shortages in the storage used for mid- to low-end phones, PCs and edge devices, wearables, and other consumer products — and the easing there will be relatively fast.
Understood. Thank you, General Manager Hai Jun — very clear, thank you. No further questions. Okay, thank you, Hu Jian. Thank you all for your questions. Now please invite Ms. Guo Guangli to deliver the closing remarks.
>be SaaS
>for years, make company website that says nothing
>we power transformative cloud workflows in the modern enterprise
>end-to-end solutions built for scale to unlock actionable insights
>drive operational excellence by turning data into decisions
>18 different landing pages
>speak in KPI jargon
>negative cumulative GAAP profits
>stock go up
>AI comes for you
>easy for people to think you’re dead
>because no one ever knew what you did in the first place
>be SaaS
>for years, make company website that says nothing
>we power transformative cloud workflows in the modern enterprise
>end-to-end solutions built for scale to unlock actionable insights
>drive operational excellence by turning data into decisions
>18 different landing pages
>speak in KPI jargon
>negative cumulative GAAP profits
>stock go up
>AI comes for you
>easy for people to think you’re dead
>because no one ever knew what you did in the first place
This period of time in SaaS reminds me of the living hell that is running a hedge fund when a sector dies and you have exposure.
1) You wake up, reach for your phone, see your stocks are down pre-market for the fifth day in a row on no news. Good morning!
Go get a bacon / egg / cheese and coffee from a deli - this will be the only good thing about your day and you know it.
2) Enter the office and your SaaS analyst has a grimace on his face. You don't want to have the same conversation you've had in your head and with him 30x a day for the past week so you just go eat your breakfast at your desk while reading news / research.
3) Your analyst comes in and you have the 121st version of the conversation. No new insights. You can sense he is beaten up so you go through 50 mental model / frameworks but neither clarity nor comfort arrives.
4) Morning meeting with the investment team.
Someone will invariably ask "So what's our view on this sector?" [meaning the sector that is equal to hell on earth right now]. This kicks off a conversation in which the other analysts who know absolutely nothing about the sector in question will start by asking gently probing questions of you and the analyst. This escalates to unanswerable questions that people only have the nerve to ask when a sector is dead. You have to graciously entertain these questions because the stocks are down so apparently anything goes. You start thinking that everyone in the room is stupid including and maybe mostly you.
After 20-30 min of abuse (maybe more) and at the point where you literally have no clue what you're even talking anymore ("when will this turn?), someone will mention that their buddy works at a rival fund where the PM sold the entire sector earlier that week. Another analyst will then mention "That fund is really smart" (implying you are stupid with which you agree wholeheartedly).
5) Meeting over. Now you and your analyst have another conversation, and you can see the fight leaving his body. You wonder how his physical body remains upright seeing as the spine is dissolving in real time but then realize you're not a doctor because you're not smart enough. Anyways, this chat may or may not culminate with the suggestion that "maybe we should take some off or just come back later". At this point, your brain floods with the history of your interactions including how the two of you have patiently been waiting for a "buying opportunity" JUST LIKE THIS. And now that it is here, didn't immediately go up, and, in fact, went down further, you are having to contemplate trimming or selling. You restrain yourself from smashing something but also understand your analyst who doesn't want to destroy his year by January 16th and die like this. Who does?
6) At this point, you realize you are simultaneously fighting 1) the market, 2) your primary analyst, 3) your other analysts, 4) your competition including QQQ which only goes up. And you feel very, very alone in this investment. No joke, this part truly sucks.
Most times, you probably trim some of whatever is hurting. Because at least you did something. And if it all goes to hell, you can sell more and say / feel you took the right action. And if it goes higher, well, at least you somewhat stayed. Honestly, at this point, no one will give you any credit for your actions anyways and you're just going to get whatever potential discredit results. It rarely pays or is feasible to be the hero here.
7) Day is almost over. 10 minutes to close or maybe right after, your largest, most "proactive" institutional investor like Blackstone will email "Hey - got a second to chat about Saas?". Or maybe your most unsophisticated investor. Usually both. So then you hop on the phone and explain what you know, what you think and what you did or plan to do. This is the point where having a 10 out of 10 investor like Blackstone helps because they are professional and get it so long as you are sticking to your process.
8) Go workout and feel a bit better. Go home and try to be present with the family for a bit. Then whiskey time and mentally go over everything again. Alone. To make sure you hopefully aren't impairing capital permanently and, if so, have a plan.
And that plan is to fire everyone and become a monk.
[To my prior SaaS analyst and team, this is not really about you. I mean, you probably did this in some shape or form to me on many occasions. But it's ok. Everyone is doing what they think is best / most helpful at the moment. And I probably did the same thing when I was in your shoes. Just trying to laugh about team investment dynamics during meltdowns and grateful I only have to answer to myself during this SaaS drawdown. So much simpler! Hope you all are well].
Stanley Druckenmiller @standuquesne on how to start each
Year.
Druckenmiller explains that he doesn't start a year with maximum size; instead, he uses a "feedback loop" where his performance dictates his aggression. He attributes this philosophy of "earning the right to be aggressive" to his time working with George Soros.
"It's my philosophy, which has been reinforced by Mr. Soros, that when you earn the right to be aggressive, you should be aggressive. The years that you start off with a large gain are the times that you should go for it. ... The way to attain truly superior long-term returns is to grind it out until you’re up 30 or 40 percent, and then if you have the convictions, go for a 100 percent year."







































![itsDanielWu's tweet photo. Feels like some important context was left off here... The HBM shortage/bottleneck is only half of the message. Below is the full response the SMIC CEO gave re the current memory shortage (translated using chatgpt). If the commodity DRAM and NAND shortage for PC and smartphones in China can be alleviated by CXMT and YMTC, that domestic supply response will affect the entire global memory market. Do not let anyone convince you that China and ex-China are separate markets for commod DRAM and NAND.
$MU $SNDK SK Hynix Samsung
[translation]
NAND Flash or DRAM (whether 32GB of DRAM or 64GB) — everyone says “the more, the better.” Essentially, what we are discussing is whether a minimum configuration is sufficient.
There are two things happening right now. One is that everyone’s compute capacity is insufficient, because there are very ambitious visions for artificial intelligence (AI). People would like to build, in one or two years, all the data centers that would otherwise be needed over the next ten years. As for what, exactly, those data centers will be used for once built, that is not fully thought through; but there is a belief that they will definitely be needed. It is like building high-speed rail stations or highways: even if in reality it should take ten or twenty years, people feel they cannot wait that long and want to build it now. Therefore, for AI-related demand, within a certain time window it will never be fully satisfied. You cannot simply “build it all at once” by making heavy investments in memory — investing in both the front-end and back-end to produce high-bandwidth memory (HBM). This shortage should persist for several years.
But the other thing I mentioned is that, in another respect, wafer equipment suppliers and wafer-fab construction are relatively fast. They can ramp wafer output for memory fairly quickly. However, new equipment and new fabs still require a long time to be qualified and validated for use in AI data centers. That means this additional capacity cannot immediately solve AI data-center demand, but it can help satisfy demand for consumer electronics: personal computers and smartphones. Right now, some smartphone and PC capacity has been diverted to AI because those are existing fabs. Once new fabs are built, they cannot serve AI (AI will still be short of HBM), but memory supply for phones and PCs will gradually become sufficient; distributors will no longer need to hoard inventory, and the overall supply chain will run more smoothly. This can be alleviated relatively quickly, and the speed of that easing depends on how quickly equipment companies deliver tools.
Based on historical equipment delivery timelines:
-Roughly the top one-third of orders (highest priority) can be delivered in about 4–5 months.
-“Normal priority” orders are delivered in about 7–8 months.
-The slowest (lowest priority) can still be delivered in about 12–16 months.
As that capacity comes online, it will first go to fill consumer demand. So we have a forecast: as this capacity is gradually released, those channel players who have been hoarding inventory will also release their stock. This is a “double whammy” (a twofold effect). At that point, there may be a turning point: end-device shortages for phones will ease, and PC shortages will ease.
If we align that timing with equipment delivery, capacity release, rapid qualification/ramp (“run mark”), and the release of hoarded channel inventory, we estimate roughly 9–12 months. Speaking personally, I think this is still relatively fast. So it is possible there will be some reversal as early as the third quarter of this year. As we said earlier, we are advising Semiconductor Manufacturing International Corporation (SMIC) customers not to stop lines and not to reduce output on their own; instead, it is better to build sufficient inventory in preparation for a third-quarter reversal.
[then he goes on to talk about the quoted HBM backend bottlenecks:]
However, on the AI side, what is needed is high-quality HBM, and that side’s delivery cycle is much slower than the front-end. For example, processes such as chamfering, backside thinning, and slicing have very slow capacity expansion. So looking out about a year, if we are still discussing constraints, it is possible that the biggest constraint for HBM AI memory will no longer be the wafer fab at the front end. Even if you devote wafer-fab capacity to AI, it does not help much, because the bottleneck is not in the front end — it is in the back end. Final test (FT) is very slow when so many wafers are stacked together; yield improvement is very slow; and quality validation is even slower. That is the bottleneck, and it cannot be relieved quickly in the short term. As a result, the leading position remains with the few largest players who started HBM earlier. New fabs built later will not be able to capture HBM’s profits as quickly, but they can immediately address shortages in the storage used for mid- to low-end phones, PCs and edge devices, wearables, and other consumer products — and the easing there will be relatively fast.
Understood. Thank you, General Manager Hai Jun — very clear, thank you. No further questions. Okay, thank you, Hu Jian. Thank you all for your questions. Now please invite Ms. Guo Guangli to deliver the closing remarks.](https://pbs.twimg.com/media/HA7L0OsaMAAmGHc.jpg)