A few things I've noticed as all devs write code with AI.
When you write foundational / architectural code of a new project by hand, you "feel" the code pushing back if your abstraction isn't right. You feel when something is harder than it should be. The code is telling you it's not in the right shape. Good engineers are sensitive to this.
When you're using an LLM, you keep pushing right through this in a way that feels like you're making progress, and it may even be directionally correct in a sense, but the underlying foundation of it all is actually bad in a way that either kills progress of the LLM later as it buckles under the complexity it has created or destroys your ability to maintain the code long term.
Related to this, I see a general restlessness with just sitting and thinking about a problem for a while.
As I've been working on a new library here at Laravel, there have been days where it feels like I mainly just stare at my screen thinking about something. When Claude Code is at your fingertips, it's tempting to just start yapping into the terminal and watching code come out the other end. Again, directionally correct in some ways, but often doesn't land on the elegant solution that is waiting to be discovered.
So, reminder: the quality of code output by these systems is *very low* and the AIs themselves don't understand the output.
This is obvious to anyone who knows how to program.
There are still use cases, for example, to output a large volume of low-quality code that is not intended to be used for serious purposes and is not expected to have a long lifetime.
Anyone extoling the virtues of AI code generation, who actually knows how to program, will do so with the context of the above paragraph in mind.
Anyone running around saying "the AI just generates all this code and it's great!!" either:
(a) Does not understand code and should not be trusted with making decisions about code;
(b) If representing themselves as people who understand code, are obvious frauds, or else have so much Dunning-Kruger they don't know how bad they are.
This may improve in the future. I would love it if I could have an AI help me write complex programs more quickly. But it's just not the state of things today, and anyone claiming it is, is either lying or being fooled.
https://t.co/H4jCDVnm8V
English as a Programming Language sucks cause your computer can do things that are barely describable in a natural language. By using English you willfully nerfing yourself as an Engineer, if you ever wanted to be one of course. Some don't and it's fine, just dont delude yourself
It's kinda insane how if you really love Programming you should probably not go into the current software development industry because you are certainly not gonna be doing enough Programming to be content with your life.
You can either code fast or produce fast code.
You cannot do both.
All frameworks, libraries, ORMs, no code movement aim to allow you to code fast, not necessarily produce fast code.
Understandably so, we live in an age where we are expected to ship fast, we have stakeholders to satisfy. we can always improve quality and performance later. Heck, we got used to ship with day 1 patch.
It is wise to ship fast because the market expects it. And to ship fast you have to code fast and to code fast you have to write less code. Or (god help us) you can use AI to write the code.
But, when you write less code, you didn’t really write less code, you simply hid a large piece of code under the carpet and expose it behind a simple API call. You abstracted away complexity, which eventually leaks in all sorts of nasty ways. Large CPU usage, large memory usage, large disk usage, slow running operations, and if you are on the cloud that translates to a large $$ bill.
You can either code fast or produce fast code. You cannot do both.
I understand why frameworks advertise how fast it is to spin a web server with their product. They truly know how complex web servers are (because they had to wrap it all away) but they have to do this to sell.
Honest frameworks will say: ‘hey, we know this stuff is complex but we made it easy by creating these abstractions and used some defaults. However, please consider looking at those defaults values and change them for your use case. We had to pick defaults that fits all but we don’t know your use case.’
My advice to software engineers - understand what you use.
For example, if you want to use a Node or a Bun web server, please consider writing one using C first as an exercise. You will appreciate the framework 10 times more.
You will even ask the framework maintainers to expose this and that configuration to tune your web server. You will ask for detailed doc of how the framework handles connection acceptance and request reading. And whether the number of SO_REUSEPORT threads can be changed.
Web server is just an example, this applies to any component.
If I would summarize this, understand the code, even if you didn’t write it. Maybe then you can code fast and also produce fast code.
And by fast code I mean efficient and fast.
The names of the 15,000+ Palestinian children murdered by Israel in Gaza.
The first 35 seconds are the names of those under 1 year old. Babies and toddlers.
This video is 7 minutes long.
Read that again.
This is a holocaust.
https://t.co/OcvLoKAbFQ
Google Cloud accidentally deleted a company's entire cloud environment (Unisuper, an investment company, which manages $80B). The company had backups in another region, but GCP deleted those too. Luckily, they had yet more backups on another provider.
https://t.co/v5WFxqUtaB
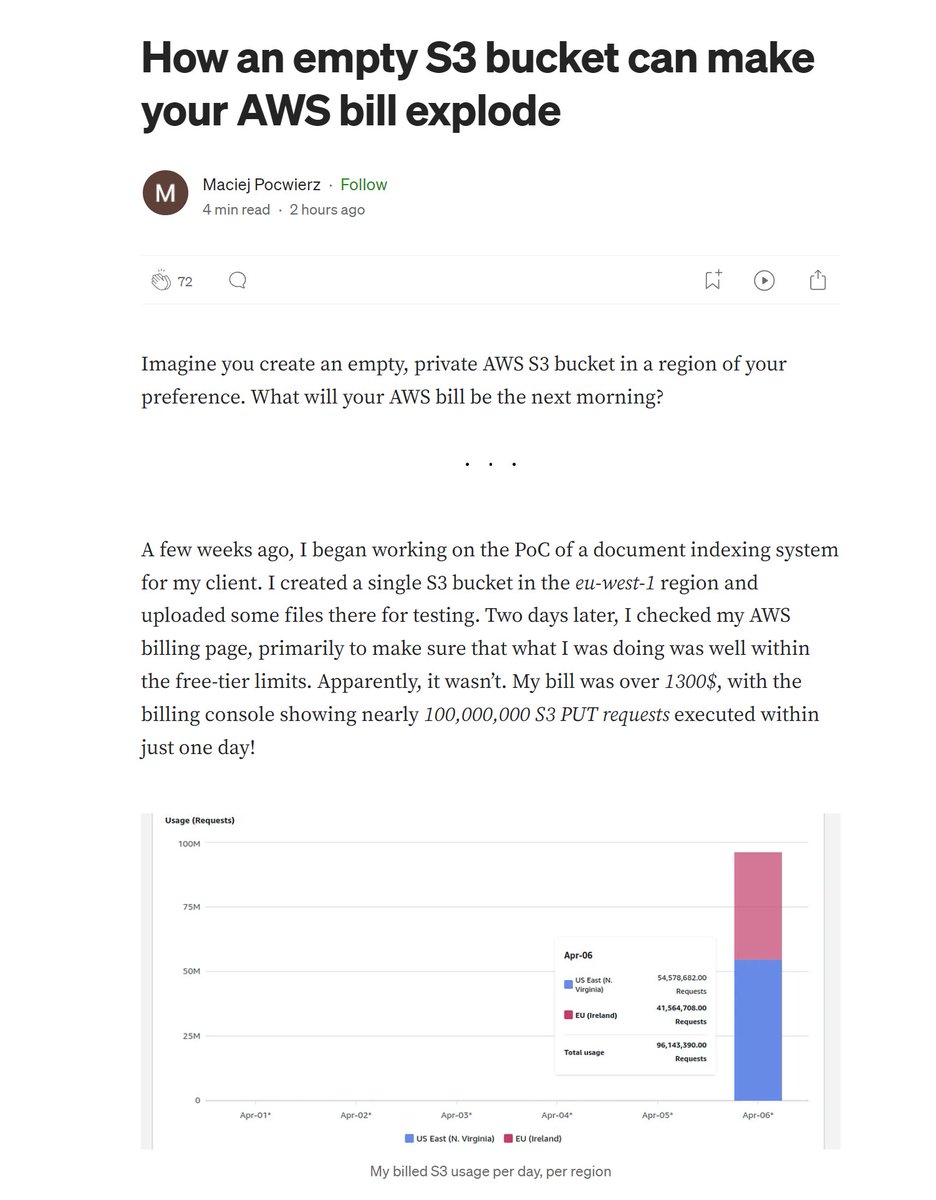
So apparently if someone knows / guesses the name of your S3 bucket - even if it's private (!) - they can just bankrupt you by sending infinite PUT requests and there is nothing you can do about it.
> requests get rejected
> but AWS still counts it as a write operation against your account for which you have to pay at a rate of $0.005 per 1000 requests
This seems insane to me. Especially because a lot of services rely on presigned URLs for uploads / downloads which exposes your bucket name to the client. In this case the author got their bill waved, but AWS support made it clear it's an exception not the rule.
HashiCorp is excited to join @IBM to continue building the platform of choice for multi-cloud automation. @armon shares his thoughts on how this serves our community, customers, partners, and product innovation: https://t.co/xBIN6FkVsE (link contains important information)
One of the bigger mind-bends in tech is how Spotify never *truly* used the Spotify model (they iterated and moved on). The #1 ranking search result is Atlassian indirectly promoting this tooling with it.
We now have companies thinking they are copying Spotify: but they are not!
🚨Leaked Israeli drone footage shows how Israel bombed 5 *clearly unarmed* civilians into pieces in Khan Younis in broad daylight as they walked through their destroyed neighbourhood
The drone shows how each of them was fully unarmed before they were bombed anyways
TypeScript rule: If a function requires something, the function's type signature should require it.
This sounds obvious and reasonable, but I often see objects with nullable fields passed to functions which actually require the field.
Here's why: Developers declare a type once and try to reuse it everywhere. This can lead to overly broad types and low type safety.
Solution: If a field is required in some contexts, declare a dedicated type that requires the field. This way, the function's signature doesn't "lie".
If a field is required, I shouldn't have to check if the field is undefined inside the function. The function's type signature should ensure it is passed an object that contains the required fields.
🚀 Excited for a #LiveCoding adventure? Join @IsmailCherri and me as we build a Time Tracker with @remix_run ! 🕒✨
🗓️ Tues, 13.02.2024
⏰ 18:00 CET (07:00PM Cairo)
🔗 Live Stream on X
Dive into #FullstackDevelopment, get your questions answered, and let's code together! 💻🎉