🚀 Thrilled to present our QUEST poster at #NeurIPS2024 in Vancouver!
📅 Thursday, Dec 12th | 4:30-7:30 PM PST
📍 East Exhibit Hall A-C #3108
Looking forward to engaging discussions & connecting with fellow researchers! Stop by to learn more about our work.
Joint work with @swetaagrawal20@tozefarinhas@RicardoRei7@accezz@andre_t_martins
🔗 Details:
https://t.co/XypgTrKDUK
https://t.co/zibypeUMed
Today we release EuroLLM-9B: the best EU-made multilingual LLM of its size!
Check the blog post for more info and results: https://t.co/jjuSqXzpFk.
Stay tuned for the technical report and bigger and more powerful models!
Super happy with this new product based on our Tower models we have been developing in the last year! Try it out and let us know what you think and what could be improved! https://t.co/Ut0N3BqZu4
💥 Today we’re excited to announce the launch of https://t.co/ZbdjnejqRJ - our new standalone AI solution built for businesses looking to scale quickly with cost-effective translations you can trust.
👇 Learn more about Widn and try it for free.
https://t.co/YUosXMb3Y8
Today we release the first EuroLLM paper and models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct!
The EuroLLM project will develop open-weight multilingual LLMs that understand and generate text in all official EU languages.
Stay tuned for the bigger and stronger EuroLLMs (9B, 22B)!
The good news continue 🥳
We are delighted that Tower has been selected as a oral spotlight presentation at @COLM_conf (top 2% of submissions)!
Check out our paper here: https://t.co/Dlqm8WivjL
I’m super proud to announce that our Tower 🗼 paper was accepted at COLM 24!
To celebrate, we are releasing a new version of TowerInstruct based on Mistral 7B: it achieves similar performance to our 13B model, while being almost half the size!
COLM Paper: https://t.co/QiZx3XfYYQ
We offer this 1y postdoc to work with us on the @UTTERProject EU project on LLM-based agents ! Come work with us on 1 or several of these topics: i] managing uncertainty and ambiguity ii] improving the use of conversational context iii] ensuring the safety and alignment of LLMs.
The Chat Shared Task (WMT2024) is live! 💥💥
Happy to announce this year’s Chat Shared Task which aims to translate a corpus composed of genuine bilingual conversations from the customer support domain!
Today we release the Tower paper! 🗼
Tower is an open-weight suite of multilingual models — built on top of LLaMA-2 — for translation-related tasks. It supports 10 different languages.
Paper: https://t.co/aHqGFe1bBw
Models and data: https://t.co/HS4Pm1NufH
🧵Thread below.
🎉 Our great team has just released a much improved Tower! We reach super high performance with TowerInstruct-13B, particularly for MT, outperforming much bigger models and dedicated translation models.
Next step: beating GPT-4? 👀
Bonus news: the paper is coming soon! 👨🏻🍳
We are releasing:
* TowerBase, a continued pre-trained LLaMA2
* TowerInstruct, a finetuned TowerBase on a curated instruction set
* TowerBlocks, the instruction set used for TowerInstruct
https://t.co/wN5uHvOii9
Super happy to share something we have been working on lately:
TowerLLM, a multilingual model geared towards cross-lingual and translation-related tasks. It has very good performance on translation benchmarks and supports 10 languages.
Introducing Tower our cutting-edge multilingual #LLM for translation-related tasks! 🚀
With 7B parameters and support for 10 languages, Tower dominates in pre-translation tasks and machine translation. 🌎
Explore the future of #NLP now 👉 https://t.co/3AY2X8NGy8
I am thrilled to share xCOMET! 😇
This metric has been in the works for a while and we are super proud of it. xCOMET will provide, contrary to previous efforts, sentence-level scores alongside error spans and their severity.
Check the paper:
📑 https://t.co/aoeNEOlL5S
Excited to share that we've won the prestigious #QualityEstimation shared task at #WMT23 for a 2nd year in a row!🎉
Our winning build was a LLM QE system with 11B parameters -- the largest #QE system ever built. 💪 Check out the win here >> https://t.co/4IYLVYUZoO @machtranslate
Old-ish news but this paper is *so good*. It does such a thorough and systematic comparison of, like, every conceivable setting you could use for n-best reranking or MBR. Extremely useful for figuring out what actually works.
Improving Machine Translation Evaluation with COMET v2.0 - Say Goodbye to Outdated Metrics! 🌟
With all the hype around GPT-4 is more important than ever to have reliable evaluation metrics and methodologies. That why we are excited to release COMET v2.0: https://t.co/I8PYFSiq2C
nice chat me and @RicardoRei7 had with @dwhitena about the work we have been doing at Unbabel related to machine translation and machine translation evaluation. check it out!
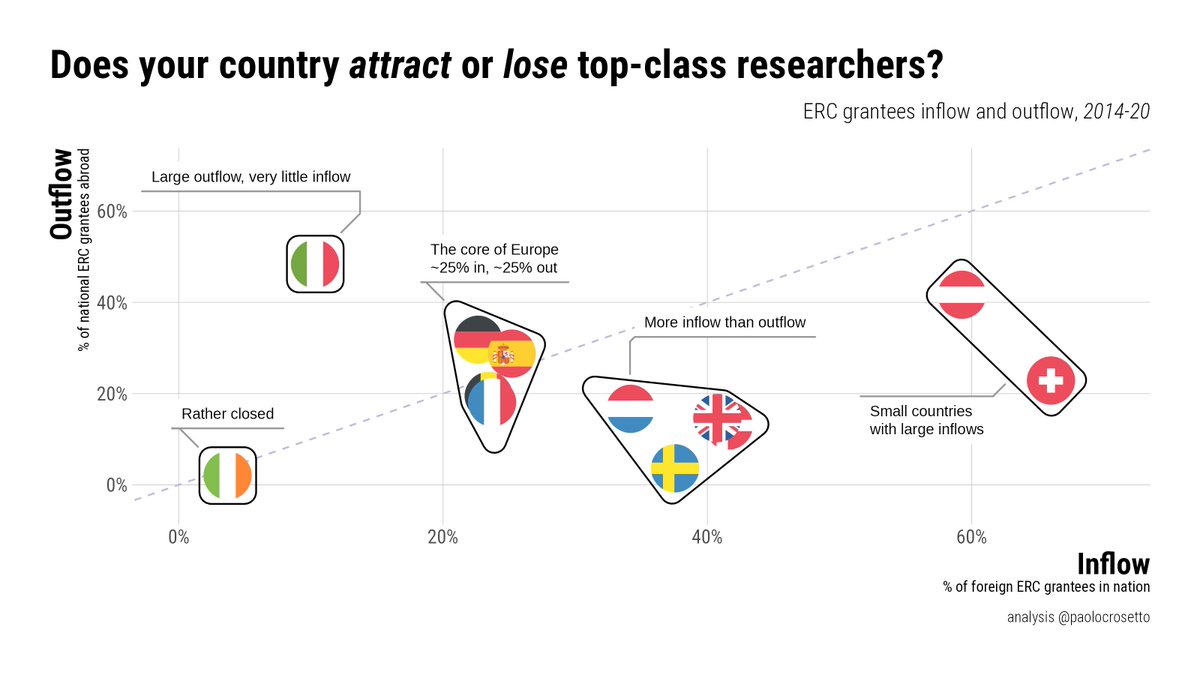
Does your (EU) country attract or lose top researchers?
AT, CH attract a lot.
FR, DE, BE, ES are open places: as many leave as arrive.
IE is a closed system.
Italy, there is something very wrong: *very* few come, many go.
Plot made with @ERC_Research data.