🚨BREAKING: Microsoft Research + Salesforce just dropped a paper that should scare every AI builder.
They tested 15 top LLMs GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, o3, DeepSeek R1, Llama 4 across 200,000+ simulated conversations.
Single-turn prompt: 90% performance.
Multi-turn conversation: 65% performance.
Same model. Same task. Just... talking normally.
The culprit isn't intelligence. Aptitude only dropped 15%.
Unreliability EXPLODED by 112%.
→ LLMs answer before you finish explaining (wrong assumptions get baked in permanently)
→ They fall in love with their first wrong answer and build on it
→ They forget the middle of your conversation entirely
→ Longer responses introduce more assumptions = more errors
Even reasoning models failed. o3 and DeepSeek R1 performed just as badly.
Extra thinking tokens did nothing.
Setting temperature to 0? Still broken.
The fix right now: give your AI everything upfront in one message instead of back-and-forth.
Every benchmark you've seen was tested on single-turn prompts in perfect lab conditions.
Real conversations break every model on the market and nobody's talking about it.
El @BancSabadell no abona les promocions. Encara espero 300e per nòmina + bizum (que m'havien d'abonar abans del 10 d'abril). Els reclames per escrit (SAC) i et diuen que els truquis. De què serveix la reclamació per escrit?
❓ What's the key to generating arbitrarily long human motion from sequences of texts (🏃🏻♀️➜🚶🏻♀️➜🧎🏻♀️➜🧘🏻♀️...)?
Check out FlowMDM, our #CVPR2024 paper w/ @SergioEscalera_@cpalmeroc.
FlowMDM avoids:
- Setting transition lengths.
- Postprocessing and complex pipelines.
🧵⬇️
one of the most important things I know about deep learning I learned from this paper: "Pretraining Without Attention"
this what I found so surprising:
these people developed an architecture very different from Transformers called BiGS, spent months and months optimizing it and training different configurations, only to discover that at the same parameter count, a wildly different architecture produces identical performance to transformers
this may imply that as long as there are enough parameters, and things are reasonably well-conditioned (i.e. a decent number of nonlinearities and and connections between the pieces) then it really doesn't matter how you arrange them, i.e. any sufficiently good architecture works just fine
i feel there's something really deep here, and we may be already very close to the upper bound of how well we can approximate a given function given a certain amount of compute. so we should spend more time thinking about other questions, such as what that function should actually look like (what data? which objective function?) and how to make it more efficient
🎁 ¡¡¡ 𝗦𝗨𝗣𝗘𝗥 𝗦𝗢𝗥𝗧𝗘𝗢 #AORUS !!! 🎁
🎉 ¡¡Participa y llévate esta Geforce RTX 4080 SUPER AORUS MASTER !!!
¿Quieres ganarla?
1️⃣ - Haz RT
2️⃣ - Sigue a @aorus_es
3️⃣ - Comenta para que la usarías y menciona a un amig@
🗳 05/04/2024 ☘️ ¡Suerte a todos!
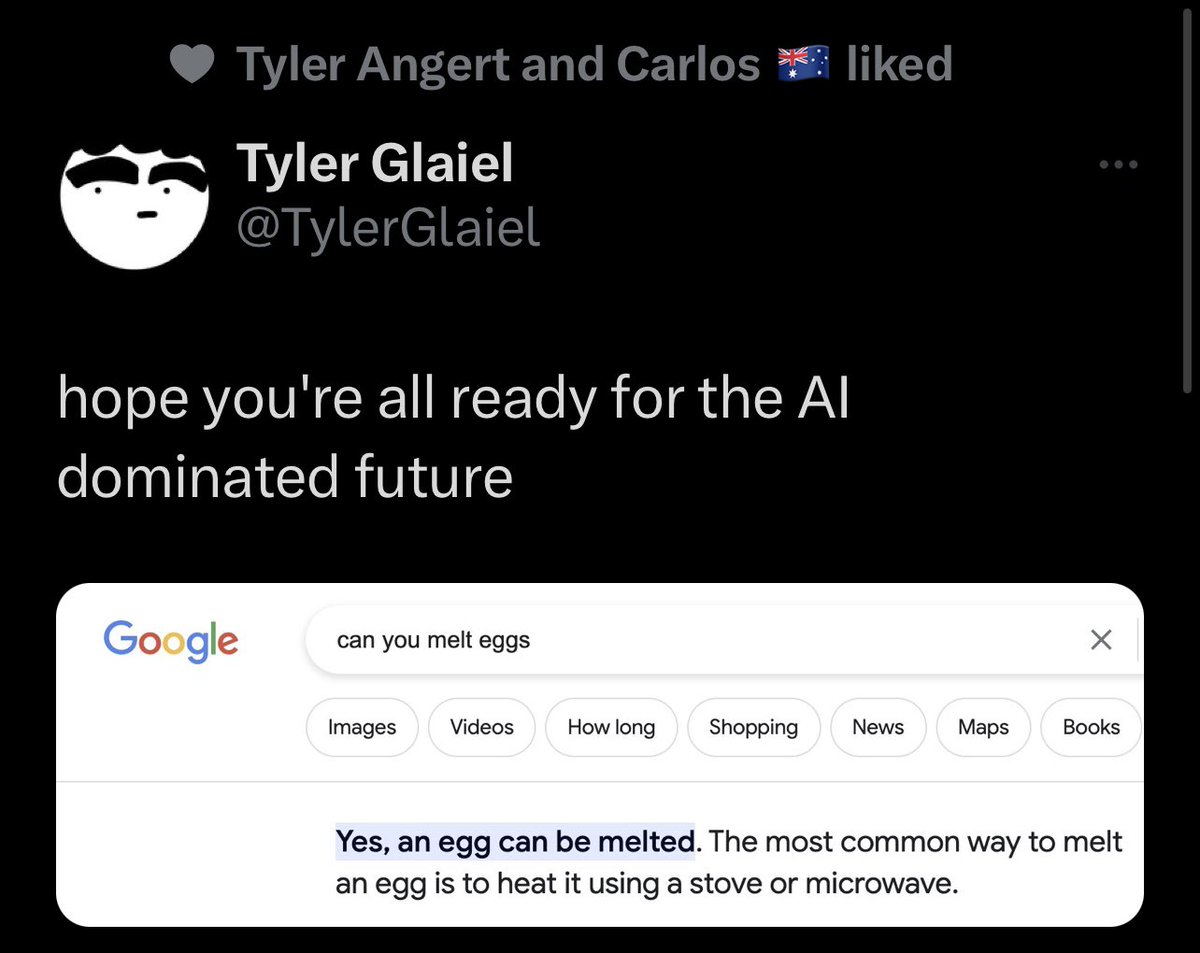
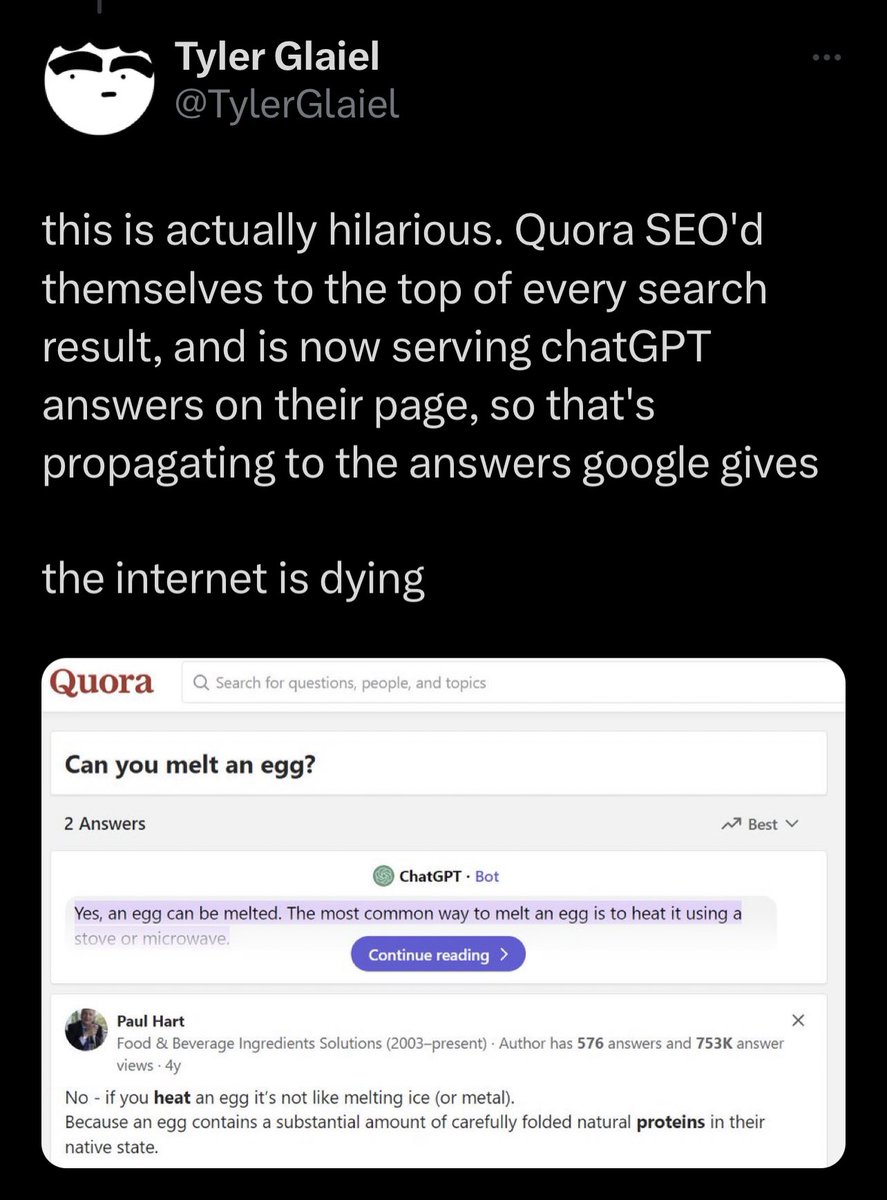
Vicious Self-Degradation
> you Google
> Quora spots query and id’s as frequent
> Quora uses ChatGPT to generate answer
> ChatGPT hallucinates
> Google picks up Quora answer as highest probability correct answer
> ChatGPT hallucination is now canonical Google answer
The upcoming death of the Transformer.
Stop. Hear me out:
Million tokens in the prompt. Intrested?
Meet the (might be) transformer killer: Hyena.
More powerful than a transformer. [*]
Order of magnitude cheaper than a transformer. [**]
But is it scalable like a transformer? 🤔
This is the million dollar question.
If the answer is "yes.": This model is going to change the world.
And we might just got a hint about the answer.
------------
Hyena? What?
---
TL;DR: Convolutional network with tricks
(Kinda convolutional.. I'll get to it).
I personally had given up on this model.
But I was wrong.
What we know:
- For small models: It is already stronger than a transformer.
- For all model sized and lengths: It is faster than a transformer.
(To the extent of 160 times faster)
- For all sizes: It needs an order of magnitude less memory (!!) than a transformer.
(To the extent where you you can run million tokens prompts in... Google Collab.
- Training this model on astronomical sequence lengths (million tokens) is possible on a single machine (!!)
- And if this was not enough: Training an extremely long context lengths has an interesting side effect: It also improves the model on shorter scales.
We still need to answer:
Is it also scalable like a transformer?
Will it continue working so well even in GPT-4 sizes? 🤔
We should expect to receive an answer to this question soon. because apparently there is a secret model of this type currently training. [4]
------------
Enough with the speculation, what else do we know about this model?
---
Paper summary: HyenaDNA - A language model for astronomically long DNA sequences.
Paper: https://t.co/CYfBHq5A2W
Code: https://t.co/Y6OCHSlTRu
Blog: https://t.co/rEnsdBFydr
Notebook: https://t.co/HBA6nsYHrH
Models: https://t.co/BjyEzCgQjz
([*] [**] - Check out this paper to see the insane results)
A few days ago I received a notification about a paper I am a co-author of [2]: Some new paper cited us.
[Of course I didn't notice it at all and @danofer made sure to tell me]
This paper presented a language model that makes use of a special architecture: Hyena.
This architecture itself was released a few months ago as a particularly promising replacement for the transformer.
The performance of this model was "almost" as the performance of a transformer. [3]
..wwwhich made me immediately ignore it altogether.
But then..
Another "teaser" was released few days ago [4].
Another gazzilion-tokens long model about to be released.
So I went to check and as it turns out: The original model had already undergone some improvements defeats transformers larger than it.
Now I was interested.
---------
Super long models
---
The context window length is a particularly hot topic today.
And there's a good reason for this: If you had an infinite window length, you could simply "paste" entire books or even entire databases into the prompt and ask the model questions.
As part of Sam Altman's world tour, it was said that OpenAI set a goal of one million tokens.
At the same time another company, Magic recently announced that they had reached 5M tokens.
While out of nowhere anthropic also released a model with 100K context window.
And what about the open source community?
Right now we are in the middle of a context-length party!
TL;DR:
- Language models trained with a limited context length.
- They are very bad if you try to run them on longer text.
- But it turns out that you can simply divide the model's positional encoding by 4 and thus trick the model making it work with lengths 4 times longer.
***
About two weeks ago, a user on 4-chan discovered this: The user called his method SuperHOT.
The method was so successful that even a paper by meta cited a the guy for the method! 😂 [5]
The inventor of the method did a particularly impressive research job in order to arrive at this trick. I highly recommend reading his blog. There are two important posts in this blog,
- First one: tells about creating a synthetic dataset for training with almost no effort (create an example->correct, create an example->correct.. until the model understands the idea and produces the right examples).
- The second: a summary and in-depth discussion of all the possible location coding articles .
***
- Immediately after this trick, an anonymous Reddit user adopted this idea and improved it: instead of using linear interpolation, the same user chose to use non-linear interpolation and thus improved the performance of the "stretched" models. [6]
- But there are no free gifts in life: this method also has its drawbacks and the power of the models is damaged as a result of the "stretching". Also adding the hyperparameter "how many parts" requires calibration and this parameter significantly controls the power of the model .
- Solution: simply determine "how many tensioners" in relation to the length of the text at the moment. This way, while creating the text, we will only stretch the window as much as we need and thus "delay" the performance hit in the model
---------
RWKV Open model with infinite length
---
RWKV - the largest LSTM network in the world (14B)
Which is also currently among the five best models in the Vicuna table, trained in the most languages.
And is also among the most trained models in all of Huggingface.
And if it is not clear: It is particularly cheap to run:
This is an RNN: Each step only looks at the current token and the hidden representation, so in theory it has an infinite context length.
---------
So transformers are pretty good.
Even GPT-4..
----------
Tangent: Everything we know about GPT-4's Architecture
---
..Which is an ensemble of 8 different transformers (MoE) with a size of 220 billion parameters each of which is trained on a different data set (probably from the same base model) with one of them specially trained to be "creative".
About the rest we don't know yet: but we know that the three options Bing are different models.
So either it is running with entire set of weights running (So estimates from Chinchilla's scaling laws: 4-5T tokens to train)
OR
The model was pre-merged (Kaggle style) into a single ensemble of 220B parameters (So estimate from Chinchilla's scaling laws: 20T tokens to train - probably not).
And there are theories that the model itself even "changes" while running or that each model has 2-beams while creating the text.
Papers to read about it:
Probably close to the architecture: GLam, mixture of experts.
Paper: https://t.co/UgdPzonesv
And rumors suggest that the next improvements will come from the following papers:
Switch Transformer:
Paper: https://t.co/qWYigIaaWZ
Routed Language Models
Paper: https://t.co/rDQmRFyZB4
Branch-Train-Merge
Paper: https://t.co/JY4Zhno9kd
> This paper also finds the optimal number of experts which is surprisingly also the exact number of GPT-4.
Other important info about the subject:
- The scaling laws of expert networks: https://t.co/rDQmRFyZB4
- Combining several knowledge domains in an MoE net with each expert specializing in a different field: https://t.co/cYobQfvpnz
----------
Sorry about that.
So even GPT-4 will agree with you that transformers are VERY good.
But the problem with transformers is that they are also very expensive due to the need of transmitting information from all tokens to all tokens.
Recently, Hyena (convolution, roughly) has shown that performance comparible to transformers can be reached with significantly less computational complexity, which allows the model to be trained and used on much longer sequences.
----------
Hyena
---
- Paper: https://t.co/93aJTnjbLW
- Code: https://t.co/oCnEr0eBfj
- Blog 1: https://t.co/VjajhCF9Bq
- Blog 2: https://t.co/xZiES9gmRi
- Blog 3: https://t.co/z8p5CE5mD4
The authors of the Hyena paper recently defeated [1] (!!) a transformer larger in size with an improved model of hyena.
If nothing unexpected happen larger models of this kind: This is the end of the transformer era.
- Monstrous sequence lengths for everyone!
- Faster.
- And might even be more accurate.
----------
The Model
---
So, we would like to remove the attention layers.
It turns out that a few individual attention layers are enough for reaching comparable results to fully attention-based models.
That is already good to know!
But we want more: If all the attention layers are completely removed there is still a significant gap of performance.
This gap can be interpreted by the fact that we are obliged to use at least one operation that compares all the tokens in the text to all the tokens in the text.
But can we somehow remove this action?
----------
Construction of a different operator:
---
An interesting feature of attention is that attention is controlled by the data itself.
The final matrix with which the calculation is performed is created on the fly based on the data.
So different data samples "choose" to use a different combination of weights in the model.
Experiments show that without this feature, in-context learning becomes much more difficult.
How can we strengthen a model without an attention layer to also be as "controlled by the data" as possible?
Simply: Generate its parameters based on the data, particularly based the position of the token.
The hyena model generate filters based on the positional encoding, these filters are then applied in a Toeplitz matrix..
***
WTF is Toeplitz matrix? You know about convolutions, right? Filter sliding from side to side? Ever wondered how to represent it in a single matrix multiplication? Just arrange it all in a diagonal of a 0s matrix.
***
..which corresponds to a convolution operation.
----------
The core Hyena trick
---
Instead of learning the filters directly, Hyena learns a map from the position encoding to the filter values.
It uses SIREN, which is a function that uses sinusoids of different frequencies to map inputs to outputs. These functions are great at approximating arbitrary functions.
----------
About the latest paper: HyenaDNA
---
In the HyenaDNA paper, the authors trained a Hyena model with a window length of one million tokens on the entire human genome.
This is because in genomics both context length and resolution are critical (you need single nucleotides).
There are many tricks and interesting bits in this paper, but on the technical side, here is everything important:
- The model itself is scalable sub-quandraticlly (NlogN) of the seq length.
- For long ctx lengths (millions) the model trains 160 times faster than transformers.
- It is so efficient, that is can be trained on 1M tokens on a single machine with 8 GPUs.
- They start the training with small sequences that gradually increase (Seq length scheduler) and thus manage to achieve the same results in almost half the time.
- And the nicest of all? The model is so easy to run that you can run it on 1M inference in Google Collab. Imagin this but in the shape of ChatGPT.
In summary:
Is the transformer going to die as the king of text generation?
I really hope so. Million tokens works for me well.
I really hope that the teaser we got is an LLM.
Such a model would be absolutely insane.
Fingers crossed!!
----------
Interesting Related Work
---
The researchers combined several breakthroughs from several different papers in order to get to the final model:
Models for particularly long sequences:
- RWKV model: https://t.co/YNtjTSs2lA
- S4 model: https://t.co/2dwdTFypsb
- H3 model: https://t.co/vvkinRRhzz
Different parameterization of the convolution operator:
- S4 Layer: https://t.co/2dwdTFypsb
- CKConv Layer: https://t.co/GZ7cMAc2YQ
- SGConv Layer: https://t.co/5KTkCpvyz5
Reverse engineering of attention networks:
- Induction heads and their importance in large language models: https://t.co/W3aP6uySw6 (Highly recommended!!)
- On Grokking (When the loss suddenly drops - A dramatic phase transition in which the network improves radically): https://t.co/yOz5F5PU02
- Measuring the distance to Grokking in order to reverse engineer the network: https://t.co/Hgr5aucAnh
----------
Tangent: Anthropic's 100K
----
Mmmm.. this reminds me something..
Is this how Anthropic got a their monstrous 100K model (100K)?
Because these models are very capable of easily running on such a long context, and they are also much much faster.
But the most importantly: If anthropic's model is a transformer, then it incorporates some kind of secret breakthrough that we are not exposed to because according to speed profiling of the API:
It is not even close to the running times of a transformer with flash attention.
[And if there is also a model out there that potentially is comparable to a transformer.. then..]
----------
---------
References:
-[1] And maybe make a mistake.
-[2] Our paper: ProteinBERT: a universal deep-learning model of protein sequence and function. Bioinformatics. Authors : N. Brandes, D. Ofer, Y. Peleg, N. Rappoport, and M. Linial.
-[3] When I say "almost" I mean it - in the graphs in the paper you can hardly see the difference between the transformer's loss and Hyena's loss.
-[4] Teaser Here: https://t.co/CfXEe5kLKg
-[5] SuperHOT method - you can read about it here: https://t.co/RvmXYmtDdV
-[6] see more: https://t.co/RvmXYmtDdV
- [7] see more: https://t.co/RvmXYmtDdV
Do you want to deal with the latest developments in deep learning for 3D human behavior understanding? Apply and join our HuPBA research team in Barcelona:
https://t.co/MbD71530Xp
Open Problems in Applied Deep Learning
If you're looking for interesting open problems in DL, this is a good reference.
Not sure if intentional but it also looks useful to get a general picture of current trends in deep learning with ~300 references.
https://t.co/AXEZQNtCjr
Our follow-up work (https://t.co/lbYQHT2VyG) further shows such alignment behaviors happen in deep linear networks, on which deep CL can be regarded as PCA. In contrast, the dynamics can be very different in ReLU networks. A more detailed introduction is left for future tweets😃
Announcing @ICCV_2021 Understanding Social Behavior in Dyadic and Small Group Interactions (DYAD) Workshop, with an incredible line-up of speakers! #ICCV2021 Web: https://t.co/NjJ79qRmRc Time: 8:00-16:00 EDT, 16 Oct 2021. Sponsored by: ChaLearn, Facebook Reality Labs, 4Paradigm.




























![Yampeleg's tweet photo. The upcoming death of the Transformer.
Stop. Hear me out:
Million tokens in the prompt. Intrested?
Meet the (might be) transformer killer: Hyena.
More powerful than a transformer. [*]
Order of magnitude cheaper than a transformer. [**]
But is it scalable like a transformer? 🤔
This is the million dollar question.
If the answer is "yes.": This model is going to change the world.
And we might just got a hint about the answer.
------------
Hyena? What?
---
TL;DR: Convolutional network with tricks
(Kinda convolutional.. I'll get to it).
I personally had given up on this model.
But I was wrong.
What we know:
- For small models: It is already stronger than a transformer.
- For all model sized and lengths: It is faster than a transformer.
(To the extent of 160 times faster)
- For all sizes: It needs an order of magnitude less memory (!!) than a transformer.
(To the extent where you you can run million tokens prompts in... Google Collab.
- Training this model on astronomical sequence lengths (million tokens) is possible on a single machine (!!)
- And if this was not enough: Training an extremely long context lengths has an interesting side effect: It also improves the model on shorter scales.
We still need to answer:
Is it also scalable like a transformer?
Will it continue working so well even in GPT-4 sizes? 🤔
We should expect to receive an answer to this question soon. because apparently there is a secret model of this type currently training. [4]
------------
Enough with the speculation, what else do we know about this model?
---
Paper summary: HyenaDNA - A language model for astronomically long DNA sequences.
Paper: https://t.co/CYfBHq5A2W
Code: https://t.co/Y6OCHSlTRu
Blog: https://t.co/rEnsdBFydr
Notebook: https://t.co/HBA6nsYHrH
Models: https://t.co/BjyEzCgQjz
([*] [**] - Check out this paper to see the insane results)
A few days ago I received a notification about a paper I am a co-author of [2]: Some new paper cited us.
[Of course I didn't notice it at all and @danofer made sure to tell me]
This paper presented a language model that makes use of a special architecture: Hyena.
This architecture itself was released a few months ago as a particularly promising replacement for the transformer.
The performance of this model was "almost" as the performance of a transformer. [3]
..wwwhich made me immediately ignore it altogether.
But then..
Another "teaser" was released few days ago [4].
Another gazzilion-tokens long model about to be released.
So I went to check and as it turns out: The original model had already undergone some improvements defeats transformers larger than it.
Now I was interested.
---------
Super long models
---
The context window length is a particularly hot topic today.
And there's a good reason for this: If you had an infinite window length, you could simply "paste" entire books or even entire databases into the prompt and ask the model questions.
As part of Sam Altman's world tour, it was said that OpenAI set a goal of one million tokens.
At the same time another company, Magic recently announced that they had reached 5M tokens.
While out of nowhere anthropic also released a model with 100K context window.
And what about the open source community?
Right now we are in the middle of a context-length party!
TL;DR:
- Language models trained with a limited context length.
- They are very bad if you try to run them on longer text.
- But it turns out that you can simply divide the model's positional encoding by 4 and thus trick the model making it work with lengths 4 times longer.
***
About two weeks ago, a user on 4-chan discovered this: The user called his method SuperHOT.
The method was so successful that even a paper by meta cited a the guy for the method! 😂 [5]
The inventor of the method did a particularly impressive research job in order to arrive at this trick. I highly recommend reading his blog. There are two important posts in this blog,
- First one: tells about creating a synthetic dataset for training with almost no effort (create an example->correct, create an example->correct.. until the model understands the idea and produces the right examples).
- The second: a summary and in-depth discussion of all the possible location coding articles .
***
- Immediately after this trick, an anonymous Reddit user adopted this idea and improved it: instead of using linear interpolation, the same user chose to use non-linear interpolation and thus improved the performance of the "stretched" models. [6]
- But there are no free gifts in life: this method also has its drawbacks and the power of the models is damaged as a result of the "stretching". Also adding the hyperparameter "how many parts" requires calibration and this parameter significantly controls the power of the model .
- Solution: simply determine "how many tensioners" in relation to the length of the text at the moment. This way, while creating the text, we will only stretch the window as much as we need and thus "delay" the performance hit in the model
---------
RWKV Open model with infinite length
---
RWKV - the largest LSTM network in the world (14B)
Which is also currently among the five best models in the Vicuna table, trained in the most languages.
And is also among the most trained models in all of Huggingface.
And if it is not clear: It is particularly cheap to run:
This is an RNN: Each step only looks at the current token and the hidden representation, so in theory it has an infinite context length.
---------
So transformers are pretty good.
Even GPT-4..
----------
Tangent: Everything we know about GPT-4's Architecture
---
..Which is an ensemble of 8 different transformers (MoE) with a size of 220 billion parameters each of which is trained on a different data set (probably from the same base model) with one of them specially trained to be "creative".
About the rest we don't know yet: but we know that the three options Bing are different models.
So either it is running with entire set of weights running (So estimates from Chinchilla's scaling laws: 4-5T tokens to train)
OR
The model was pre-merged (Kaggle style) into a single ensemble of 220B parameters (So estimate from Chinchilla's scaling laws: 20T tokens to train - probably not).
And there are theories that the model itself even "changes" while running or that each model has 2-beams while creating the text.
Papers to read about it:
Probably close to the architecture: GLam, mixture of experts.
Paper: https://t.co/UgdPzonesv
And rumors suggest that the next improvements will come from the following papers:
Switch Transformer:
Paper: https://t.co/qWYigIaaWZ
Routed Language Models
Paper: https://t.co/rDQmRFyZB4
Branch-Train-Merge
Paper: https://t.co/JY4Zhno9kd
> This paper also finds the optimal number of experts which is surprisingly also the exact number of GPT-4.
Other important info about the subject:
- The scaling laws of expert networks: https://t.co/rDQmRFyZB4
- Combining several knowledge domains in an MoE net with each expert specializing in a different field: https://t.co/cYobQfvpnz
----------
Sorry about that.
So even GPT-4 will agree with you that transformers are VERY good.
But the problem with transformers is that they are also very expensive due to the need of transmitting information from all tokens to all tokens.
Recently, Hyena (convolution, roughly) has shown that performance comparible to transformers can be reached with significantly less computational complexity, which allows the model to be trained and used on much longer sequences.
----------
Hyena
---
- Paper: https://t.co/93aJTnjbLW
- Code: https://t.co/oCnEr0eBfj
- Blog 1: https://t.co/VjajhCF9Bq
- Blog 2: https://t.co/xZiES9gmRi
- Blog 3: https://t.co/z8p5CE5mD4
The authors of the Hyena paper recently defeated [1] (!!) a transformer larger in size with an improved model of hyena.
If nothing unexpected happen larger models of this kind: This is the end of the transformer era.
- Monstrous sequence lengths for everyone!
- Faster.
- And might even be more accurate.
----------
The Model
---
So, we would like to remove the attention layers.
It turns out that a few individual attention layers are enough for reaching comparable results to fully attention-based models.
That is already good to know!
But we want more: If all the attention layers are completely removed there is still a significant gap of performance.
This gap can be interpreted by the fact that we are obliged to use at least one operation that compares all the tokens in the text to all the tokens in the text.
But can we somehow remove this action?
----------
Construction of a different operator:
---
An interesting feature of attention is that attention is controlled by the data itself.
The final matrix with which the calculation is performed is created on the fly based on the data.
So different data samples "choose" to use a different combination of weights in the model.
Experiments show that without this feature, in-context learning becomes much more difficult.
How can we strengthen a model without an attention layer to also be as "controlled by the data" as possible?
Simply: Generate its parameters based on the data, particularly based the position of the token.
The hyena model generate filters based on the positional encoding, these filters are then applied in a Toeplitz matrix..
***
WTF is Toeplitz matrix? You know about convolutions, right? Filter sliding from side to side? Ever wondered how to represent it in a single matrix multiplication? Just arrange it all in a diagonal of a 0s matrix.
***
..which corresponds to a convolution operation.
----------
The core Hyena trick
---
Instead of learning the filters directly, Hyena learns a map from the position encoding to the filter values.
It uses SIREN, which is a function that uses sinusoids of different frequencies to map inputs to outputs. These functions are great at approximating arbitrary functions.
----------
About the latest paper: HyenaDNA
---
In the HyenaDNA paper, the authors trained a Hyena model with a window length of one million tokens on the entire human genome.
This is because in genomics both context length and resolution are critical (you need single nucleotides).
There are many tricks and interesting bits in this paper, but on the technical side, here is everything important:
- The model itself is scalable sub-quandraticlly (NlogN) of the seq length.
- For long ctx lengths (millions) the model trains 160 times faster than transformers.
- It is so efficient, that is can be trained on 1M tokens on a single machine with 8 GPUs.
- They start the training with small sequences that gradually increase (Seq length scheduler) and thus manage to achieve the same results in almost half the time.
- And the nicest of all? The model is so easy to run that you can run it on 1M inference in Google Collab. Imagin this but in the shape of ChatGPT.
In summary:
Is the transformer going to die as the king of text generation?
I really hope so. Million tokens works for me well.
I really hope that the teaser we got is an LLM.
Such a model would be absolutely insane.
Fingers crossed!!
----------
Interesting Related Work
---
The researchers combined several breakthroughs from several different papers in order to get to the final model:
Models for particularly long sequences:
- RWKV model: https://t.co/YNtjTSs2lA
- S4 model: https://t.co/2dwdTFypsb
- H3 model: https://t.co/vvkinRRhzz
Different parameterization of the convolution operator:
- S4 Layer: https://t.co/2dwdTFypsb
- CKConv Layer: https://t.co/GZ7cMAc2YQ
- SGConv Layer: https://t.co/5KTkCpvyz5
Reverse engineering of attention networks:
- Induction heads and their importance in large language models: https://t.co/W3aP6uySw6 (Highly recommended!!)
- On Grokking (When the loss suddenly drops - A dramatic phase transition in which the network improves radically): https://t.co/yOz5F5PU02
- Measuring the distance to Grokking in order to reverse engineer the network: https://t.co/Hgr5aucAnh
----------
Tangent: Anthropic's 100K
----
Mmmm.. this reminds me something..
Is this how Anthropic got a their monstrous 100K model (100K)?
Because these models are very capable of easily running on such a long context, and they are also much much faster.
But the most importantly: If anthropic's model is a transformer, then it incorporates some kind of secret breakthrough that we are not exposed to because according to speed profiling of the API:
It is not even close to the running times of a transformer with flash attention.
[And if there is also a model out there that potentially is comparable to a transformer.. then..]
----------
---------
References:
-[1] And maybe make a mistake.
-[2] Our paper: ProteinBERT: a universal deep-learning model of protein sequence and function. Bioinformatics. Authors : N. Brandes, D. Ofer, Y. Peleg, N. Rappoport, and M. Linial.
-[3] When I say "almost" I mean it - in the graphs in the paper you can hardly see the difference between the transformer's loss and Hyena's loss.
-[4] Teaser Here: https://t.co/CfXEe5kLKg
-[5] SuperHOT method - you can read about it here: https://t.co/RvmXYmtDdV
-[6] see more: https://t.co/RvmXYmtDdV
- [7] see more: https://t.co/RvmXYmtDdV](https://pbs.twimg.com/media/F0PQdJZXgAM1Pxl.jpg)






















