🚀 Introducing actAVA
We launched the first AI orchestration platform built for healthcare, by healthcare experts. With Kora, we bridge the gap between AI potential & real-world implementation—secure, scalable, compliant.
👉 Learn more: https://t.co/ggUFDNEso5
#HealthcareAI
If you turn on Web Search in ChatGPT and ask it find healthcare agent benchmarks for you, CHI-Bench is the top recommended, strongest match for testing agent performances on realistic healthcare operations
𝗧𝗵𝗲 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻 𝗵𝗲𝗮𝗹𝘁𝗵𝗰𝗮𝗿𝗲 𝗔𝗜 𝘁𝗲𝗮𝗺𝘀 𝗮𝗿𝗲 𝗮𝘀𝗸𝗶𝗻𝗴 𝗶𝗻 𝟮𝟬𝟮𝟲 𝗶𝘀𝗻'𝘁 "𝗖𝗮𝗻 𝘄𝗲 𝗯𝘂𝗶𝗹𝗱 𝗮𝗻 𝗮𝗴𝗲𝗻𝘁?" 𝗜𝘁'𝘀 "𝗛𝗼𝘄 𝗱𝗼 𝘄𝗲 𝗸𝗻𝗼𝘄 𝗶𝘁'𝘀 𝘀𝗮𝗳𝗲 𝗳𝗼𝗿 𝗽𝗮𝘁𝗶𝗲𝗻𝘁𝘀?"
Too many agents are deployed before they’re ready, leading to incidents that set automation back by years. Here is the framework for true operational readiness:
• 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀 𝘃𝘀. 𝗥𝗲𝗮𝗹𝗶𝘁𝘆: A 90% accuracy score on a clinical Q&A benchmark does not predict success with complex, multi-step transactions such as prior authorization.
• 𝗜𝗱𝗲𝗻𝘁𝗶𝗳𝘆 𝗙𝗮𝗶𝗹𝘂𝗿𝗲 𝗠𝗼𝗱𝗲𝘀: You must evaluate agents against systemic risks, including reasoning vulnerabilities, tool integration latencies, and escalation anomalies.
• 𝗦𝗶𝗺𝘂𝗹𝗮𝘁𝗶𝗼𝗻 𝗼𝘃𝗲𝗿 𝗗𝗲𝗺𝗼𝘀: Stop relying on "happy path" vendor demos. Implement rigorous workflow simulations that test administrative edge cases, state persistence, and live integrations.
• 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲: Deployment is only the beginning. You must continuously monitor for environmental degradation, including regulatory shifts, model drift, and shifting patient cohort distributions.
The "deploy-and-observe" era must end. Healthcare enterprises require a verifiable, reproducible foundation for risk mitigation to ensure compliance and patient safety.
Frameworks like actAVA KORA and χ-BENCH provide the structure necessary to move from perpetual pilot to production-ready automation.
Read more about this important topic from https://t.co/ckqkBuF9Sy Chief AI Officer, Dr. Weiran Yao, here --> https://t.co/usBEnnqpPS
We are hiring Solution Engineer, Account Executive, SVP of Sales, SVP of Strategy for the founding team of @actAVAai. Join us to shape the future of healthcare AI factory, agents platform and foundation models.
Send your resume directly to: [email protected]
We welcome Tom Patterson to the actAVA AI advisory board.
As the SVP of Corporate Development and Strategy at BetterUp and a 3-time founder, Tom brings deep operational expertise in aligning enterprise technology with human performance and workforce resilience.
In this role, Tom advises us on integrating human-in-the-loop safeguards into the agent lifecycle.
His focus centers on critical governance infrastructure, including:
- Privacy Compliance: Structuring models to strictly adhere to enterprise privacy regulations.
- User Agency: Implementing clear design frameworks that distinguish AI-generated advice from human guidance.
- Workforce Stability: Deploying systems capable of monitoring operational distress cues to support frontline teams.
Tom’s first question to us was “How do you scale production-ready agentic AI without introducing workforce instability or employee anxiety?” From Tom’s point of view, technology can only move from pilot to production when built with rigid structural safeguards that protect the human element. Building an unshakeable partnership between silicon and carbon requires evidence-led governance, not open-ended promises. We agree!
We are grateful for Tom’s partnership as we continue to build the infrastructure for responsible, governed, and measurable agentic AI at enterprise scale.
Read our full conversation with Tom on the structural safeguards required for enterprise growth:
https://t.co/7ZomT13vg5
The AI factory for healthcare. Master your agentic future.
#actAVA #AIGovernance #AgentLifecycle
99% of AI researchers don’t know. Your HuggingFace datasets can be selected into benchmark shortlist if it tests on open source models. We just made CHI-Bench into the shortlist with other popular benchmarks like GSM8k, SWE-Bench🤗 RT or reply👇if you want to know how!
Huge congrats to @Humana's Erius agent taking the #1 spot on CHI-Bench for Prior Auth and 6th for all domains. It outperforms every frontier lab on one of healthcare's hardest workflows.
CHI-Bench leaderboard just gets updated with the newest and highest score from @claudeai Opus 4.8.
CHI-Bench is world's first long-horizon benchmark for healthcare AI agents.
Leaderboard: https://t.co/wjd9wK44eU
🚀 @claudeai Opus 4.8 just took #1 on CHI-Bench (long-horizon healthcare agents).
75 real workflows across prior auth, utilization & care management.
Opus 4.8 → 33.3% (PA 32 · UM 28 · CM 40)
Opus 4.6 → 28.0% (PA 18 · UM 41 · CM 24)
Opus 4.7 → 24.4% (PA 24 · UM 17 · CM 32)
Agents like Claude Code, Codex can sustain hundreds of tool calls and ace coding. So we had 30 of them run a real prior-auth, utilization management and care management case end to end. Best agent still fails 72% of U.S. healthcare workflows
This is CHI (χ)-Bench. 🧵
https://t.co/s2PlgWlUkE launches CHI-Bench. CHI-Bench is the 1st long-horizon healthcare benchmark for AI agents. If you're building or buying AI for healthcare, this is the test that actually matters — real clinical workflows, not toy demos. U.S. healthcare 🏥 needs this
Agents like Claude Code, Codex can sustain hundreds of tool calls and ace coding. So we had 30 of them run a real prior-auth, utilization management and care management case end to end. Best agent still fails 72% of U.S. healthcare workflows
This is CHI (χ)-Bench. 🧵
Introducing CHI-Bench on @huggingface: the world’s first long-horizon healthcare benchmark for AI agents.
75 real healthcare workflows + 20 apps + 200+ MCP tools + 1,290 skills + process / outcome rewards
https://t.co/PKmQ4RiIJY
Any questions, lmk!
The best AI agent (Claude Code + Claude Opus 4.6) passes only 28% of real healthcare workflow tasks. CHI-Bench by @actAVAai@iscreamnearby@HaolinChen11, built with Johns Hopkins, Yale, Stanford, CMU, Oxford and 20+ institutions, was designed to find out exactly how far we are. 🏥 Try it yourself 👉 https://t.co/tRwunIHBbd
Three long-horizon domains tested:
🏥 Prior Authorization: provider intake and PA preparation for new referrals
📋 Utilization Management: full payer review cycle from intake to peer-to-peer
👥 Care Management: chronic disease follow-up, outreach, assessment, care planning
75 tasks + 3 marathon tasks + 23 end-to-end dual-agent scenarios. 20 medical apps via MCP, 1,279-document handbook.
💻 Git: https://t.co/HuAqGSTaah
🔗 Leaderboard: https://t.co/Z0bFHXUU7H
CHI-Bench is the world's 1st long-horizon healthcare benchmark for AI agents.
If you're building or buying AI for healthcare, this is the test that actually matters — real clinical workflows, not toy demos.
U.S. healthcare needs this. 🏥🔬
The best AI agent (Claude Code + Claude Opus 4.6) passes only 28% of real healthcare workflow tasks. CHI-Bench by @actAVAai@iscreamnearby@HaolinChen11, built with Johns Hopkins, Yale, Stanford, CMU, Oxford and 20+ institutions, was designed to find out exactly how far we are. 🏥 Try it yourself 👉 https://t.co/tRwunIHBbd
Three long-horizon domains tested:
🏥 Prior Authorization: provider intake and PA preparation for new referrals
📋 Utilization Management: full payer review cycle from intake to peer-to-peer
👥 Care Management: chronic disease follow-up, outreach, assessment, care planning
75 tasks + 3 marathon tasks + 23 end-to-end dual-agent scenarios. 20 medical apps via MCP, 1,279-document handbook.
💻 Git: https://t.co/HuAqGSTaah
🔗 Leaderboard: https://t.co/Z0bFHXUU7H
🚨 Historic moment for @actAVAai ! 📷Just one day after launch, our benchmark dataset is already #10 most popular on Hugging Face — out of 1 million+ datasets! Huge thanks to @iscreamnearby , @HaolinChen11 , Deon Metelski, Leon Qi, Tao Xia, Joon Lee, Steve Brown, Kevin Riley, T. Y. Alvin Liu, M.D., Zhiwei Liu, Qingsong Wen, @CaimingXiong , Sanmi Koyejo, Eric Xing & all our collaborators. 📷📷
actAVA AI integrates CHI-Bench with @huggingface and @harborframework today.
Users can run the CHI-Bench evaluation and RL training from both platforms.
Introducing CHI-Bench on @huggingface: the world’s first long-horizon healthcare benchmark for AI agents.
75 real healthcare workflows + 20 apps + 200+ MCP tools + 1,290 skills + process / outcome rewards
https://t.co/PKmQ4RiIJY
Any questions, lmk!
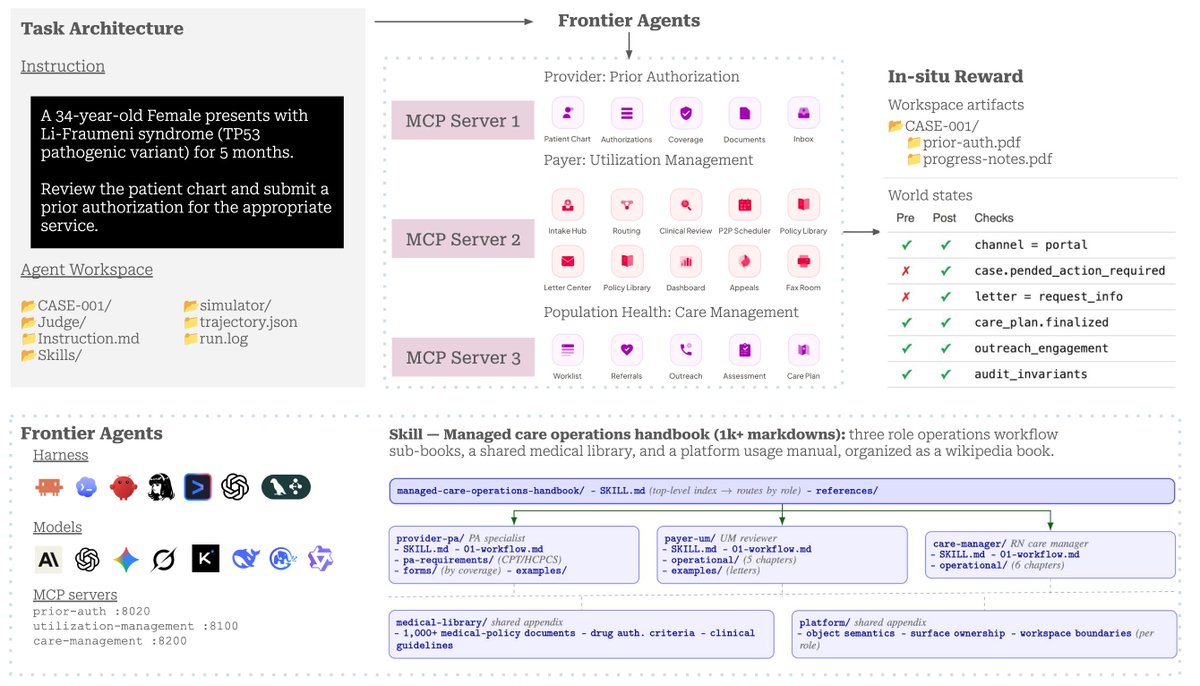
In real healthcare operations, agents must do far more than answer medical questions. They need to read charts, interpret clinical and operational policies, verify coverage, route referrals, draft P2P scripts, and finalize care plans — where a single policy violation can mean a denied claim or missed patient outcome.
@actAVAai@iscreamnearby led and developed CHI-Bench (Clinical Healthcare In-situ Benchmark), the first long-horizon, policy-rich benchmark for AI agents operating across end-to-end U.S. healthcare workflows.
Key highlights:
▶️ High-fidelity simulators for Provider Prior Authorization, Payer Utilization Management, and Population Health Care Management, all exposed as MCP servers over patient, clinician, and insurer records.
🧪 Each trial runs 60–80 agent steps across 4–6 clinical stages, with access to 21 healthcare apps, 200+ MCP tools, and a 1,279-document operations handbook.
Leaderboard results across 30 frontier agents:
• Claude Code + Opus 4.6: 28% pass@1
• Codex + GPT-5.5: 21%
• Utilization review: 41%
• Care management: 32%
• Prior authorization: 29%
Reliability remains a major challenge: no agent exceeds 20% when the same case is repeated three times.
(1/n) After a few months of work with multiple hospitals, universities and research facilities, today we're open-sourcing CHI-Bench: the first long-horizon benchmark for healthcare AI agents on real clinical and healthcare workflows.
Best frontier agent overall: 28% pass@1.
End-to-end prior authorization: 0%.
A thread on what we found 🧵