@WilliambilSf I think you need funding for your project. Someone created a coin for you on @bankrbot
Ca coin: 0x20d35a75b2547d8ad23e629868226c0bf3934ba3
Are you interested in integrating your project with Bankrbot? You'll get more money to develop your project.
ICYMI, just dropped the largest Open Source Multilingual OCR Dataset
> 1M images , 22 languages , 6 tasks
its also trending in the multimodal category with close to 3k downloads in the last 3 days
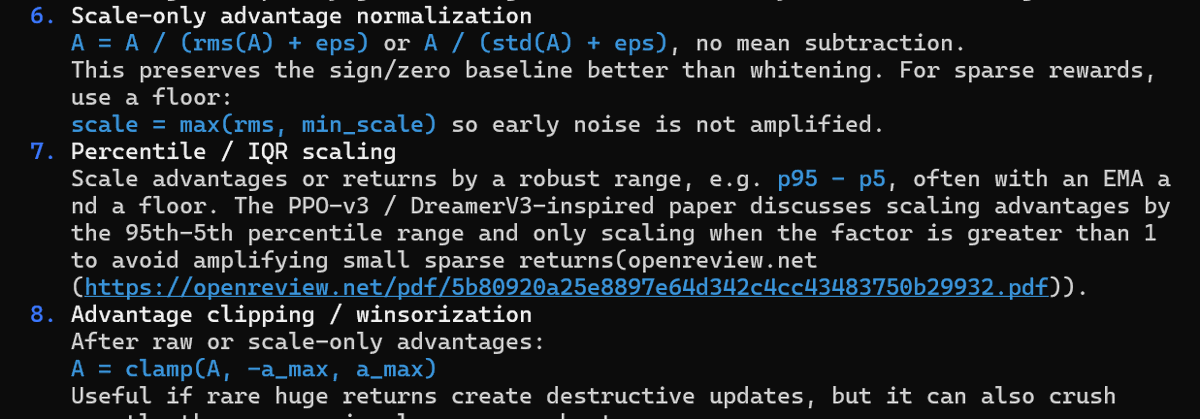
Another massive fail. Cites PPO-v3 + DreamerV3 on percentile scaling for robust advantage scaling. Pretty nifty right? Except I'm the last author on PPO-v3 and the paper states that DreamerV3's scaling tricks generally do not work at all.
🚨New Optimizer Paper
AMUSE: Anytime MUon with Stable gradient Evaluation
AMUSE combines Muon with Schedule-Free-style gradient evaluation for stable anytime training without LR decay.
• Stronger 124M / 720M / 1B pretraining
• Strong ImageNet / ViT fine-tuning performance.
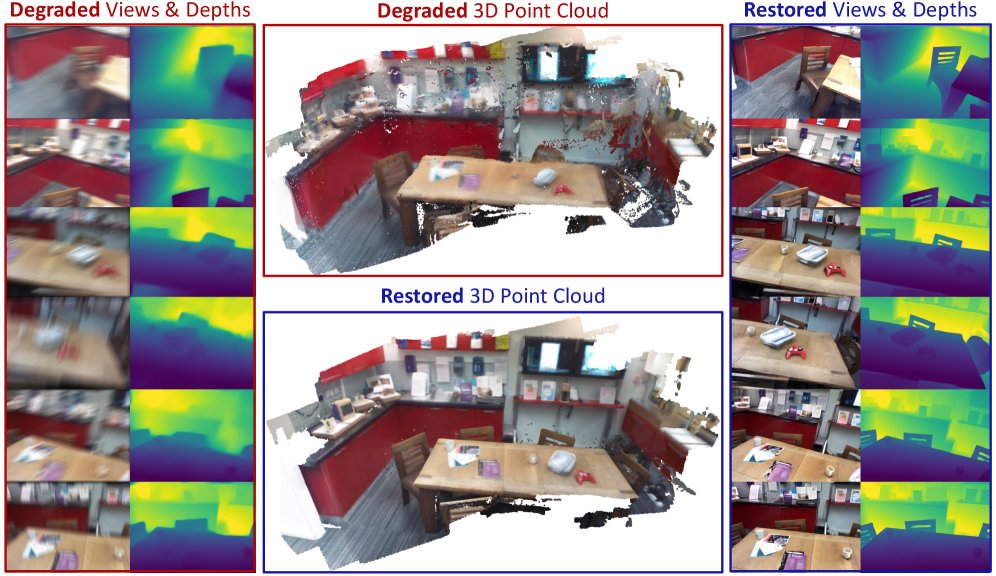
GARD: Geometry-Aware Representation Denoising
Diffusion-based restoration directly inside the feature space of a 3D reconstruction model.
Preserves cross-view geometry while recovering clean images and 3D structure from degraded inputs.
Outperforms pixel-space and VAE-based methods.
It is not the first time API providers have misled users by offering a weaker model than the one they claim. Even OpenAI can undermine the trust game.
Our latest paper is the first academic work to discuss this issue in detail. We propose an attack against existing detection methods, showing how a small model can impersonate a larger model in practice and fool users.
I really love working on these kinds of fresh ideas, whether or not they are directly related to my main research line lol
Your “Pro” LLM Subscription May Actually Be “Free”: Exposing Fingerprint Spoofing Risks in LLM Inference Services
Coming to arXiv in several days!
GPT-5.5 getting caught for silently downgrading intelligence
https://t.co/i0Xom5I3Yh
DATA QUALITY IS NOT JUST A MIXTURE WEIGHT, IT IS A SCHEDULING VARIABLE.
Curated data plays two roles: early, it amplifies signal through smaller batches; late, it suppresses noise through larger batches.
Drop-Stable-Rampup follows directly: drop batch at the quality transition, hold low, then ramp near the end.
Paper: https://t.co/HgmF2Gdz2A
New paper:
We present a "Unified Neural Scaling Law" functional form that accurately models & extrapolates the multivariate scaling behaviors of artificial neural networks as the variables listed in this attached video are varied.
(1/N)
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below:
1. Full attention as an anti-trend?:
They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2.
2. Linear and sparse attention deployment issues:
They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system.
In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision.
Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context).
3. Fine-grained Mixture-of-Experts (MoEs) are useful:
Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing.
Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing.
The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago).
4. Sophisticated agent pipeline
It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline.
They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc.
5. Interleaved thinking for context management
Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days).
6. Speed rewards
It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness)
7. Self-evolution
Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
Excited to release 🌟Polar🌟, our Agent RL rollout infra for real-world harnesses. Be it Codex, Claude Code, OpenClaw, Hermes, or your self-made ones 🔥 -- Polar takes your harnesses directly as training environments without code change.
Find a problem, design the harness, and train your own agents! 🧵