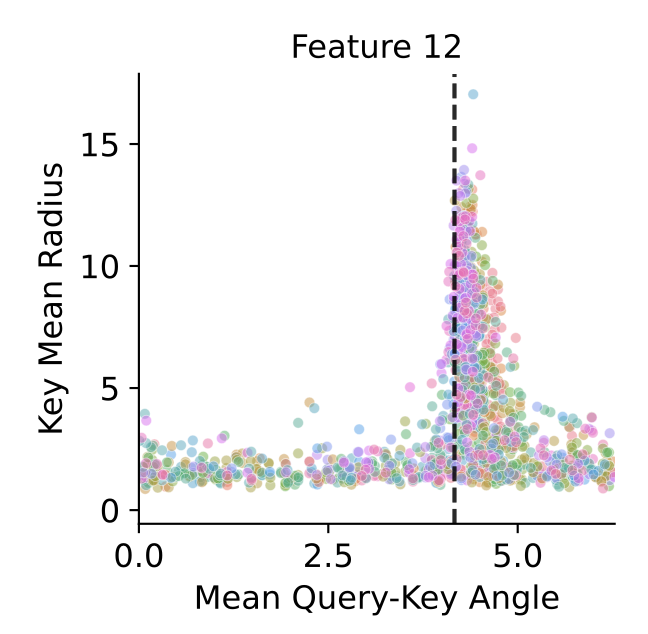
Interesting observation: features with large activations tend to cluster near the lower bound. By feeding just one sequence (shorter than context length) and inspecting key/query activations, you can get a rough estimate of a model’s context length. (black dashes = lower bound)
We're using this as part of an implementation of an AI Assistant with python code execution as a tool. Parsing the streaming json that's being generated for the tool call allows us to display the code as it's being generated to the users.
Found pydantic's `from_json` function's argument `partial_mode="trailing-strings"` for parsing streaming json and therefore tool calls (e.g. code) through an obscure github issue, deserves more visibility in this context.
Some additional aspects of Meta's paper on improving LLM performance using a multi-token objective function that I enjoyed:
1. Choice points, tokens that decide the future trajectory of the generation.
2. The sequential backward trick to maintain the memory consumption.
When developing Voyager, we only used the thinnest abstraction in LangChain and didn't touch the agent API at all.
Hackability is the No. 1 important feature to cutting-edge AI research & products. Libraries that augment LLMs (vector DB, search, interpreter) are more useful than wrappers around them.
Don't get me wrong: LangChain is fantastic for education and well-established workflows that work out of the box. But you are better off building your own pipeline for anything beyond.
This reminds me of the gazillion "high-level packages" that used to haunt Tensorflow, while nothing beats raw PyTorch code in usability, flexibility, simplicity, and elegance.
John Schulman's (OpenAI) presentation on RLHF has some great information about pitfalls when labeling Supervised Fine-tuning (SFT) answers for Large Language Models (LLMs).
Here are some nuggets from the presentation.
1/🧵
An immediate consequence is that Open Source Foundation Models that are fine-tuned on the data collected from the output of ChatGPT and GPT, or from any other LLM, may become incentivised to hallucinate or withhold information. 7/