This is the most dangerous place to be when running AI agents in production.
Thinking that daily log review, manual approval before sending, and active monitoring is enough to keep your agent under control.
You’re missing something crucial that could save your whole pipeline.
Let’s dig into what it is:
🧵1/6
You’ve seen this setup before.
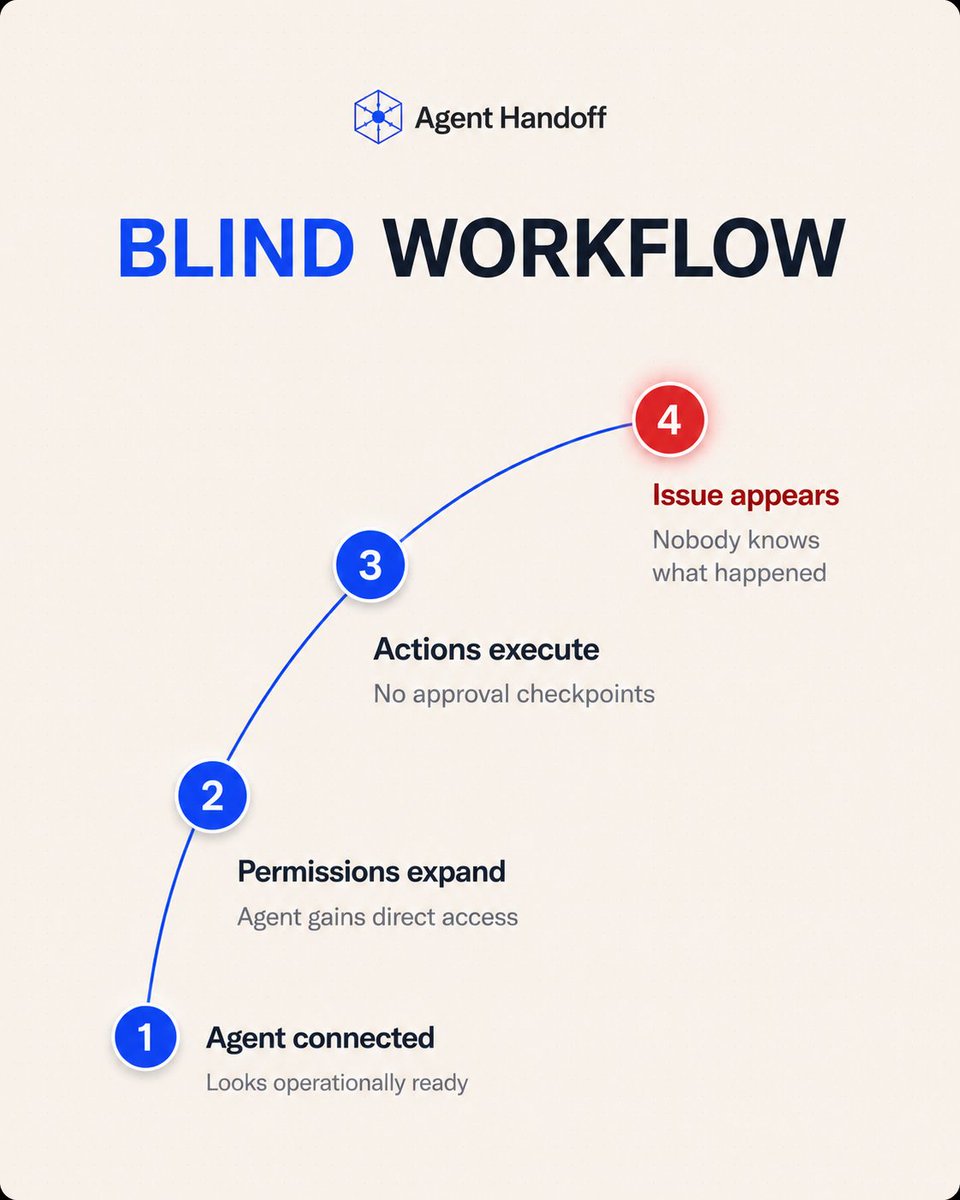
The agent works. Tasks complete. Automation scales. Everything looks production-ready.
The problem is rarely the model. It’s the workflow around it.
Permissions expand.
Actions execute directly.
Approvals disappear.
A workflow can look operationally mature on the surface. It isn’t.
The system scales. A governed workflow holds. A blind one breaks, because the second layer of operational control was never there.
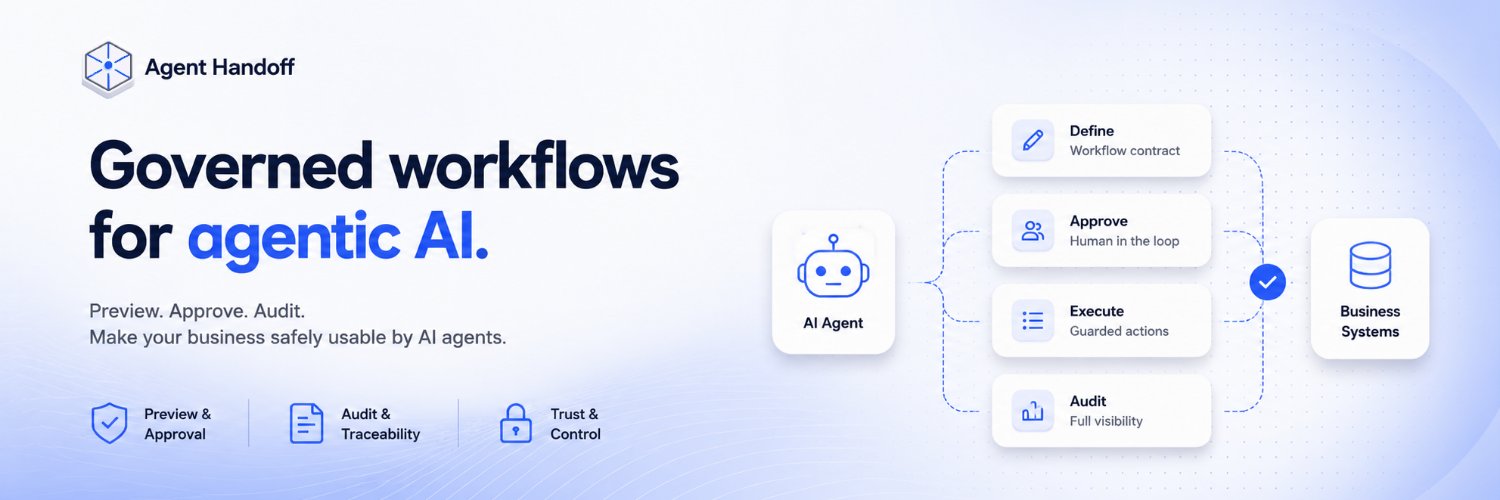
Agent Handoff shows you what’s behind an agent action, before production does.
@recouso C'mon guys, this is not only useful for traders...
If you do any creative work, color grading, animation, design, digital painting, video editing, this is incredible for managing ai pipelines/ batch generations and having refrences open.
AI benchmarks won’t save you from production failures.
A model can score incredibly well on evaluations and still create serious problems once connected to real business systems.
Production failures rarely happen because the model was “not smart enough.”
They happen because:
an agent had too many permissions
there was no approval layer
workflows had no operational controls
AI was connected directly to production systems
nobody could properly audit what happened afterwards.
Benchmarks measure intelligence.
Production systems require trust, controls, approvals, and governed execution.
The dangerous part isn’t just what the model says.
It’s what the model is allowed to do.
80.4% accuracy on computer-use agents is impressive. The real test comes when someone deploys this against production systems where the 0.4% failure doesn't just break the task — it breaks trust. That's when you need a governance layer sitting underneath that catches edge cases before they execute.
Exactly this.
And the thing that actually makes reliability possible isn't the model, it's the workflow layer underneath. Defined scope, governed execution, audit on every action. The boring infrastructure nobody talks about is what makes the exciting use cases survivable in production.
@idapixl Persistent memory solves the continuity problem. The next unsolved layer is persistent authority — what the agent is actually allowed to do across those 100 sessions as its context and confidence grow.
Memory makes agents smarter. Governance makes them trustworthy.
We’re entering the same phase with AI agents.
V1 demos are easy. The real challenge is whether the system survives changing workflows, permission scopes, retries, approvals, and production edge cases 30 days later.
At that point you’re no longer doing prompt engineering. You’re designing operational architecture.
You can’t fully solve this with prompting alone.
Agents drift because there’s usually no hard boundary between what they’re told they can do and what they’re actually allowed to execute.
The pattern that holds up in production is governing actions at the workflow layer, not the model layer.
The agent never gets raw production access.
It can only request scoped actions through controlled workflows.
6/ This is why we're building Agent Handoff.
A control layer that sits between your AI agents and your production systems.
Before the action executes — not after.
If you're deploying agents against real systems right now and this thread made you nervous — that's the right reaction.
https://t.co/TVFCVCKOL2— we're onboarding the first teams now.
This is the most dangerous place to be when running AI agents in production.
Thinking that daily log review, manual approval before sending, and active monitoring is enough to keep your agent under control.
You’re missing something crucial that could save your whole pipeline.
Let’s dig into what it is:
🧵1/6
5/ Most teams still treat this like something to solve later.
But here's what the companies getting it right figured out early:
Governance isn't the thing that slows agents down.
It's the only thing that makes production deployment survivable.
DevSecOps research proved the same pattern: teams that embed controls early ship faster and roll back less. Not slower. Faster.
Governance is the road. Not the speed bump.
Genuine question for anyone building with agents:
What does your current approval layer for high-risk actions actually look like?
(Slack message to yourself counts. I've seen worse.)
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.