when a human searches for something, they visit maybe 5 websites. when an AI agent does it on your behalf, it visits 5,000.
you asked ChatGPT what camera to buy. It read the entire internet.
so now the web is majority bots, visiting pages written for humans, increasingly written by AI, to be read by more bots.
Cloudflare itself just cut 20% of its staff because of AI.
the company measuring the bot takeover is also a victim of the bot takeover.
Humans are now a minority on the internet built for them. and the bots can't even buy anything.
We’ve been researching new ways for ChatGPT memory to carry context across conversations and keep it useful over time.
Today, that work is rolling out as a more capable memory system in ChatGPT. https://t.co/0MyFKCe2Mu
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
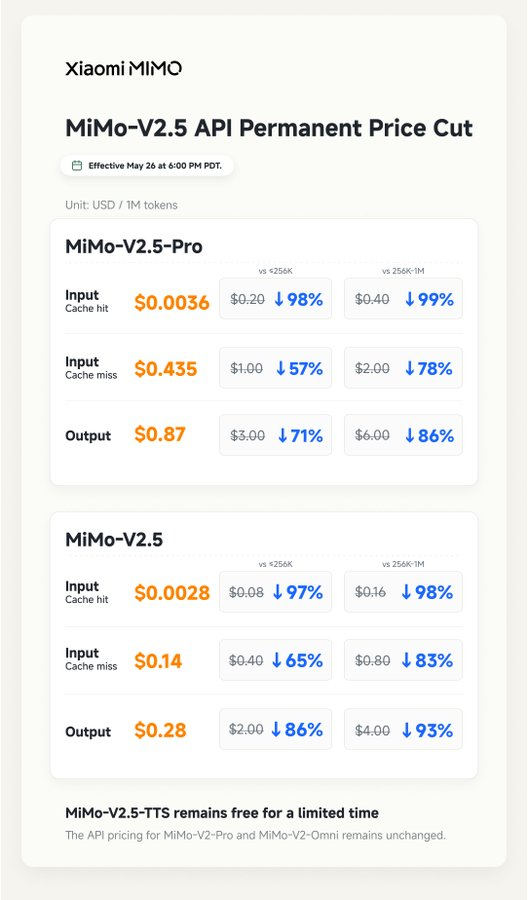
DeepSeek just made its 75% price cut on V4-Pro permanent. Xiaomi's MiMo slashed V2.5 pricing by up to 99%, effective today. Most coverage frames this as a price war. The more interesting part is the engineering that makes these numbers sustainable.
DeepSeek's V4 paper describes a *hybrid attention architecture* that attacks the core bottleneck of long-context inference: the KV cache. Traditional transformers store key-value pairs for every token in the context. At 1 million tokens, this cache alone can fill an entire GPU's memory. V4 introduces two interleaved attention types.
Compressed Sparse Attention (CSA) compresses every 4 tokens into a single KV entry, then selects only the top-k most relevant compressed blocks per query. Heavily Compressed Attention (HCA) goes further, compressing 128 tokens into one entry and running dense attention over the result. The compressed sequence is short enough that dense attention stays cheap.
V4-Pro's KV cache at 1M tokens is 10% (!!) of V3.2's. Single-token inference FLOPs drop to 27% (!!). The model has 1.6 trillion total parameters but only activates 49 billion per token through Mixture-of-Experts routing, the knowledge capacity of a massive model at the compute cost of one thirty times smaller.
MiMo's approach is different but lands in the same place. Xiaomi's team implemented Sliding Window Attention via SGLang HiCache, reducing KV cache data transfer across GPU memory, CPU memory, and SSD to roughly 1/7 (!!) of previous volume. Cacheable tokens expanded by 5x (!!). Combined with expert parallelism optimization and input length bucketing, per-token serving cost dropped enough to make permanent pricing at these levels viable.
V4-Pro now sits at $0.87 per million output tokens. MiMo V2.5-Pro at roughly $3/M output, with Flash variants far below that. A year ago, sub-dollar output pricing meant you were using a small distilled model with real capability tradeoffs. These are frontier-class reasoners with million-token context windows.
Both companies can commit to permanent cuts because the reductions come from the architecture itself. When your attention mechanism physically processes fewer FLOPs per token and your cache occupies a fraction of the memory, the cost to serve is structurally lower. The price follows the cost curve.
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
New Model to test!
Xiaomi MiMo-V2.5 API pricing NOW is same as Deepseek v4.
Input (cache): $0.0036 (55.5× cheaper now)
Output: $0.87 (dropped from $6)
MiMo's latency: ~57 tok/s (deepseek is at ~30 tok/s)
If you're using hermes/openclaw or using deepseek v4 as executor (like me) then give MiMo-V2.5 a try.
It's tool calling and agentic capabilities are great.
According to my testing it burns 25% less tokens then deepseek v4 (less verbose).
Don't use MiMo-V2.5 for planning. Only use it for execution.
(I use Codex 5.5 as Orchestrator/Planner.)
🚀 Better inference efficiency, lower costs, broader access.
MiMo-V2.5 Series API pricing is now permanently reduced — by up to 99% compared to previous pricing.
✨ Unified pricing across all context lengths.
MiMo Token Plans have also been upgraded:
• 5–8× more usable tokens at the same price
• Simpler and more transparent billing rules
🎁 As a thank-you to current users, all current Token Plan credits will be fully reset.
🎧 MiMo-V2.5-TTS remains free for a limited time.
⏰ Effective May 26 at 6:00 PM PDT.
These improvements are powered by continued inference optimization and serving efficiency upgrades across the MiMo stack.
🛠️ We’ll also publish a detailed technical blog on the inference optimizations later — stay tuned.
MiMo 2.5 Pro now costs the same as DeepSeek V4 Pro.
The cost of good models is falling at breakneck speed. Intelligence is becoming truly too fast to measure.
Up to -99%
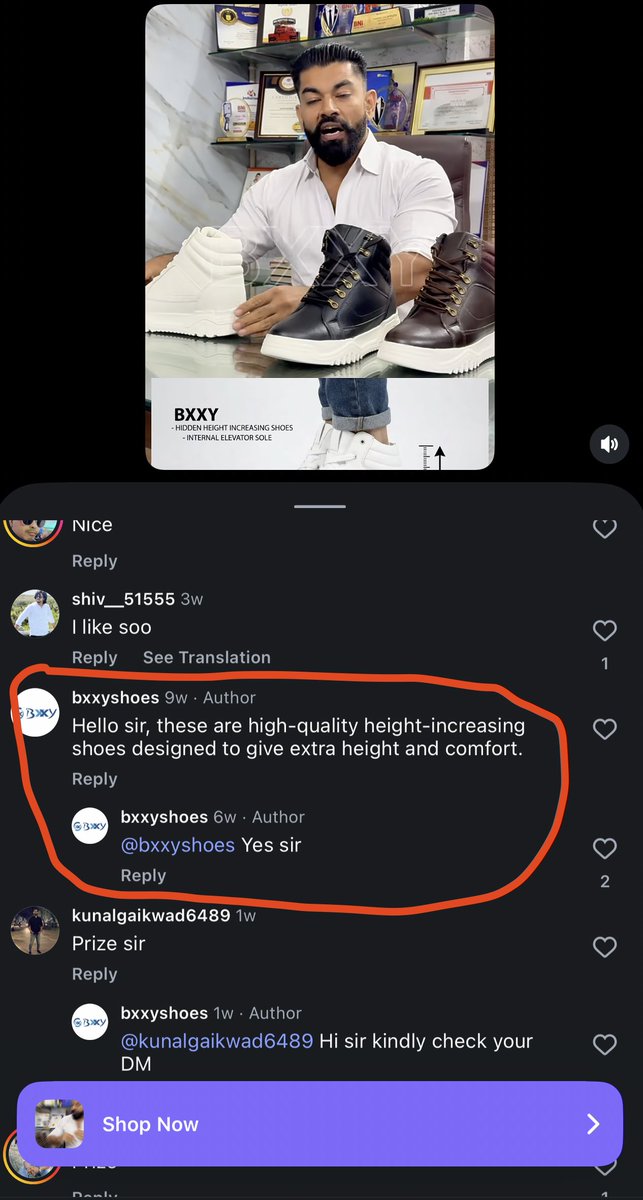
Instagram is full of fake reviews/comments. I think they mistakenly commented from their own profile and then responded back too lmao. How dumb you have to be to do something like this? Instagram should not allow these business pages to delete the comments on their reels.