Currently in FirstView: “Synthetically generated text for supervised text analysis.” @ahalterman proposes a method for using LLMs to generate synthetic training data for training smaller, traditional supervised text models.
@arthur_spirling@cbarrie@brendan642 Unfortunately pretty much none of them do, because of licensing/copyright issues. The best I've seen is a news source + headlines, which you can (sometimes, painfully) use to get the original text, but it's not easy.
Reminder - for the terrific interdisciplinary Text as Data conference, abstract submissions coming up - due Aug 4!
https://t.co/BjegNt4qpv
It's a great, small, non-archival conference to discuss emerging work with folks across social sciences, humanities, and computer science.
How can we categorize political actors extracted from text without or dictionaries or lots of hand labeling? We can use a "soft dictionary" approach with a small set of hand-written patterns and a transformer model.
OK, here it is: a line in the sand (in @Nature). I am very wary about scientists---including political scientists---embracing/pushing proprietary LLMs. Let's try an open science approach. Hope this take is a useful one.
https://t.co/jvb4tK8lE2
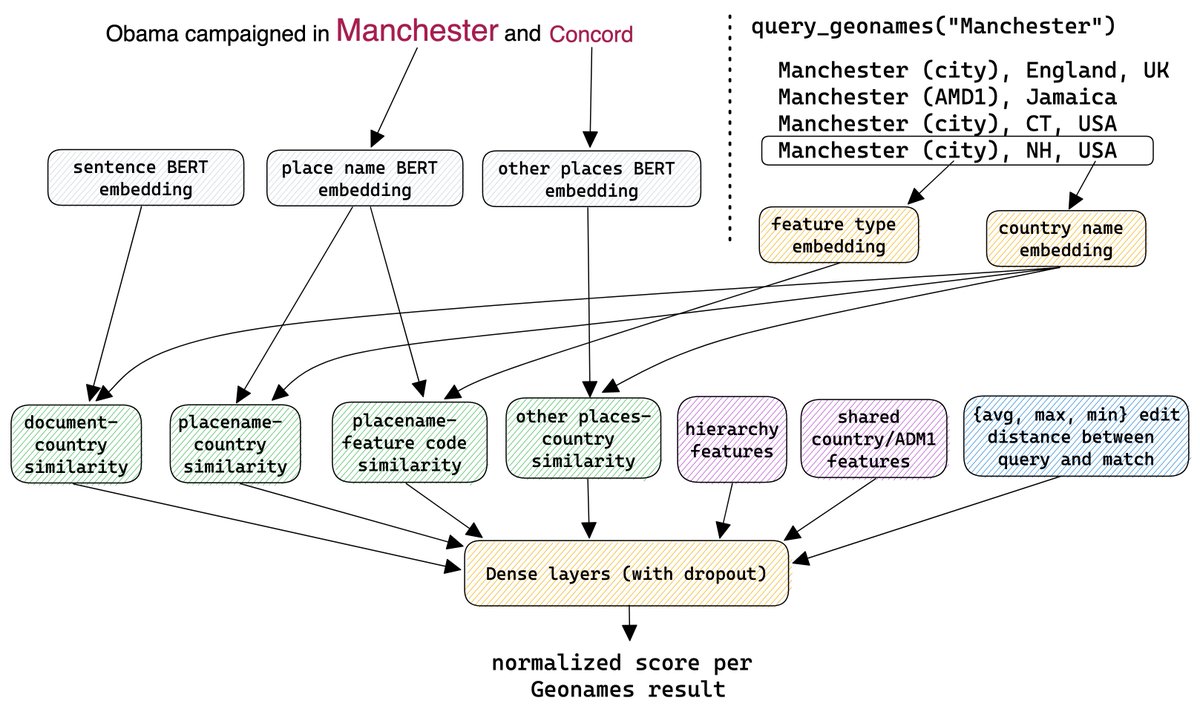
I've (finally) released an update to my text geoparsing library. Mordecai 3 lets you pass in a document, and returns the place names from the text and their geographic coordinates. It's built on #spacy and Geonames and uses a new neural similarity model.
Mordecai 3 is open source, runs offline, and is available via pip or on GitHub: https://t.co/RVPnCux6vT. Check out the paper for more details and performance comparisons with other geoparsers: https://t.co/zLhn2IjUfj
@emollick Not a special issue, but I have a working paper on using synthetically generated text to train supervised classifiers (with poli sci applications). Paper: https://t.co/YWcMpuuh8k Poster: https://t.co/qWIvb3HSIa
@emollick The main guidance is on how to guide the text generation (when to prompt vs. when to fine tune) and how to handle the output (hand label or zero shot). ChatGPT is definitely moving things toward prompt+zero shot.
@emollick Not a special issue, but I have a working paper on using synthetically generated text to train supervised classifiers (with poli sci applications). Paper: https://t.co/YWcMpuuh8k Poster: https://t.co/qWIvb3HSIa
Much of IR is concerned with understanding the behavior of elites. That’s nice from a natural language processing perspective, as elite decision-making tend to get written down.
— SSP alum @ahalterman on natural language processing in IR research.
https://t.co/4saIhRmpiA
@arnicas Every time I sit down to make a Streamlit demo, I think “this will probably take a couple hours”, and then it takes like 20 minutes. It’s a really nice tool!