These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
🚨 BREAKING: Google Research just dropped the textbook killer.
Its called "Learn Your Way" and it uses LearnLM to transform any PDF into 5 personalized learning formats. Students using it scored 78% vs 67% on retention tests.
The education revolution is here.
As amazing as LLMs are, improving their knowledge today involves a more piecemeal process than is widely appreciated. I’ve written before about how AI is amazing... but not that amazing. Well, it is also true that LLMs are general... but not that general. We shouldn’t buy into the inaccurate hype that LLMs are a path to AGI in just a few years, but we also shouldn’t buy into the opposite, also inaccurate hype that they are only demoware. Instead, I find it helpful to have a more precise understanding of the current path to building more intelligent models.
First, LLMs are indeed a more general form of intelligence than earlier generations of technology. This is why a single LLM can be applied to a wide range of tasks. The first wave of LLM technology accomplished this by training on the public web, which contains a lot of information about a wide range of topics. This made their knowledge far more general than earlier algorithms that were trained to carry out a single task such as predicting housing prices or playing a single game like chess or Go. However, they’re far less general than human abilities. For instance, after pretraining on the entire content of the public web, an LLM still struggles to adapt to write in certain styles that many editors would be able to, or use simple websites reliably.
After leveraging pretty much all the open information on the web, progress got harder. Today, if a frontier lab wants an LLM to do well on a specific task — such as code using a specific programming language, or say sensible things about a specific niche in, say, healthcare or finance — researchers might go through a laborious process of finding or generating lots of data for that domain and then preparing that data (cleaning low-quality text, deduplicating, paraphrasing, etc.) to create data to give an LLM that knowledge.
Or, to get a model to perform certain tasks, such as use a web browser, developers might go through an even more laborious process of creating many RL gyms (simulated environments) to let an algorithm repeatedly practice a narrow set of tasks.
A typical human, despite having seen vastly less text or practiced far less in computer-use training environments than today's frontier models, nonetheless can generalize to a far wider range of tasks than a frontier model. Humans might do this by taking advantage of continuous learning from feedback, or by having superior representations of non-text input (the way LLMs tokenize images still seems like a hack to me), and many other mechanisms that we do not yet understand.
Advancing frontier models today requires making a lot of manual decisions and taking a data-centric AI approach to engineering the data we use to train our models. Future breakthroughs might allow us to advance LLMs in a less piecemeal fashion than I describe here. But even if they don’t, the ongoing piecemeal improvements, coupled with the limited degree to which these models do generalize and exhibit “emergent behaviors,” will continue to drive rapid progress.
Either way, we should plan for many more years of hard work. A long, hard — and fun! — slog remains ahead to build more intelligent models.
[Original text: https://t.co/SHRN5JDvTW ]
Four AI agents increased the net-profit for an e-commerce business I work with by $47,000 in the last 90 days.
I'm not talking about basic automations. I'm talking about AI systems that:
→ Generate professional product photos in seconds (no photographer needed)
→ Steal your competitor's best-performing Facebook ads and recreate them
→ Create unlimited influencer content without shipping a single product
→ Find qualified leads on Twitter 24/7 and convert them automatically
All running while I sleep. No employees. No overhead. Just pure profit.
The problem? Most e-commerce owners are still paying photographers $2-5K/month, burning ad budgets on creative that flops, and spending thousands per influencer post.
I've been testing these agents for 4 months. The numbers are insane:
✅ $10K+ saved annually on product photography alone
✅ Ad creative costs slashed by 50%
✅ 47 influencer ads generated for $3 in API calls (vs $14K traditional cost)
✅ $3K in revenue from completely free Twitter traffic
These four agents handle product photography, ad creative, influencer content, and lead generation - work that used to cost $6K+/month in freelancers and agencies.
The e-commerce stores deploying AI agents like these are about to eat everyone's lunch while others are still manually creating content and bleeding cash on ads.
Want the exact n8n templates for all four agents?
Like & RT this post
Follow me (so I can dm you)
Comment "PROFIT" below
I'll send you the complete systems for free, plus links to my YouTube tutorials showing the step-by-step builds.
Researchers from Meta built a new RAG approach that:
- outperforms LLaMA on 16 RAG benchmarks.
- has 30.85x faster time-to-first-token.
- handles 16x larger context windows.
- and it utilizes 2-4x fewer tokens.
Here's the core problem with a typical RAG setup that Meta solves:
Most of what we retrieve in RAG setups never actually helps the LLM.
In classic RAG, when a query arrives:
- You encode it into a vector.
- Fetch similar chunks from vector DB.
- Dump the retrieved context into the LLM.
It typically works, but at a huge cost:
- Most chunks contain irrelevant text.
- The LLM has to process far more tokens.
- You pay for compute, latency, and context.
That’s the exact problem Meta AI’s new method REFRAG solves.
It fundamentally rethinks retrieval and the diagram below explains how it works.
Essentially, instead of feeding the LLM every chunk and every token, REFRAG compresses and filters context at a vector level:
- Chunk compression: Each chunk is encoded into a single compressed embedding, rather than hundreds of token embeddings.
- Relevance policy: A lightweight RL-trained policy evaluates the compressed embeddings and keeps only the most relevant chunks.
- Selective expansion: Only the chunks chosen by the RL policy are expanded back into their full embeddings and passed to the LLM.
This way, the model processes just what matters and ignores the rest.
Here's the step-by-step walkthrough:
- Step 1-2) Encode the docs and store them in a vector database.
- Step 3-5) Encode the full user query and find relevant chunks. Also, compute the token-level embeddings for both the query (step 7) and matching chunks.
- Step 6) Use a relevance policy (trained via RL) to select chunks to keep.
- Step 8) Concatenate the token-level representations of the input query with the token-level embedding of selected chunks and a compressed single-vector representation of the rejected chunks.
- Step 9-10) Send all that to the LLM.
The RL step makes REFRAG a more relevance-aware RAG pipeline.
Based on the research paper, this approach:
- has 30.85x faster time-to-first-token (3.75x better than previous SOTA)
- provides 16x larger context windows
- outperforms LLaMA on 16 RAG benchmarks while using 2–4x fewer decoder tokens.
- leads to no accuracy loss across RAG, summarization, and multi-turn conversation tasks
That means you can process 16x more context at 30x the speed, with the same accuracy.
The code has not been released yet by Meta. They intend to do that soon.
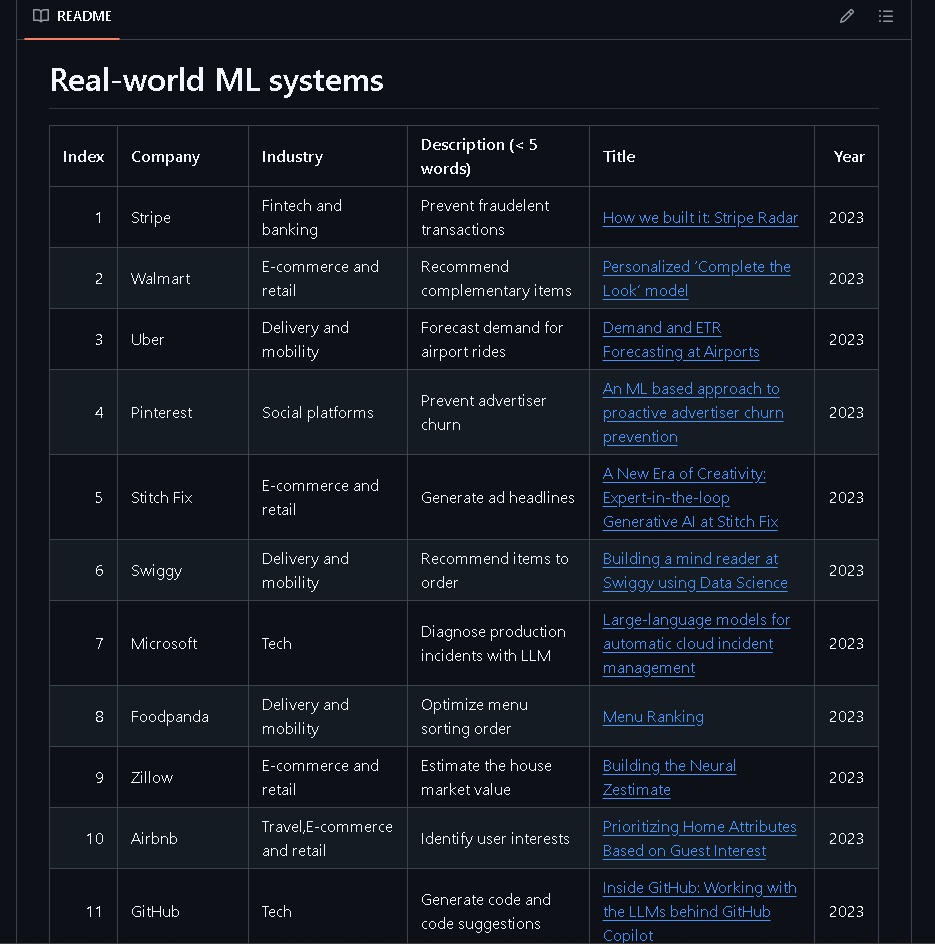
found a repo that has a massive collection of Machine Learning system design case studies used in the real world, from Stripe, Spotify, Netflix, Meta, GitHub, Twitter/X, and much more
link in replies
Altcoins are back on BTC's path! September brought significant volatility to the crypto market, and many altcoins briefly outperformed Bitcoin, causing their correlation with BTC to drop—a historical sign of risk and imminent volatility. But now, most altcoins are following BTC again. In other words, if BTC goes up, they rise; if BTC goes down, they fall! Stay alert to crypto market dynamics, as altcoins rarely stay off BTC’s trail for long.
Check it out now and enjoy our 3-day trial at https://t.co/1cjMJtIoAw!
👨🔧 Github: PDF-Extract-Kit, A Toolkit for High-Quality PDF Content Extraction.
Stars ⭐️
- Integrates leading document parsing models for layout detection, formula detection, formula recognition, OCR, and table recognition.
- high-quality parsing across diverse document types due to fine-tuning on varied document annotation data.
- Includes pre-trained models for layout detection, formula detection, formula recognition, OCR, and table recognition.
github. com/opendatalab/PDF-Extract-Kit
DeepMind built a simple RAG technique that:
- reduces hallucinations by 40%
- improves answer relevancy by 50%
Let's understand how to use it in RAG systems (with code):
Here's an overview of what the app does:
- First search the docs with user query
- Evaluate if the retrieved context is relevant using LLM
- Only keep the relevant context
- Do a web search if needed
- Aggregate the context & generate response
Now let's jump into code!