@keerthanpg It's the end of RAG as we know it, but not the end of RAG.
Today, a lot of effort is put into vector stores, chunking, overlap, etc. Instead, use an agent w/ Google search: search, pull out info from each result, and summarize it into your 10M context for the next plan step.
A big part of my job is extracting technical information from subject matter experts.
While Juno seems tailored to user research, it seems like a similar #GenAI approach would work for technical fact gathering to support #softwarearchitecture
Using a model tuned for task routing will make agents more reliable, but what about tuning a model to break the problem down into individual tool steps to make agents more powerful?
AI just won't stop 🤯
Just this week, 160+ AI models were released from companies like Google, META, Alibaba, more.
Here are the 9 incredible AI models you need to know about:
1/ FMA-Net, a new AI model for video deblurring.
The Self-Operating Computer Framework now supports the OCR-based approach for click decisions, by far surpassing previous methods attempted in the project. It's now the default - just type `operate`.
Discovering the capability shown in the demo is a bit stunning to me. This only recently became possible as far as I am aware.
It is worth considering the implications of these new capabilities. The error rate is still high. It took a few attempts for this to work but as these systems improve we will need to question many of our assumptions about data on the internet.
Demo: The self-operating computer stars its own GitHub repo.
Seems like endless possibilities for an agent with memory, tools, and a planning layer. RAG (or a conversation with another agent) is just another tool.
#softwarearchitecture with #GenAI, becomes an agent that can do Google searches, RAG, planning, and summarized reasoning.
🪜 4 Levels of Agents for RAG 🤖
There’s an entire spectrum of agentic capabilities offering simple-to-advanced reasoning on top of your data.
Here’s a mini-🧵 on the 4 different levels of agents and how they can augment your RAG pipeline 👇
1️⃣ Tool Use: A linear pipeline that can query a set of tools given a user query.
The simplest example is a router: https://t.co/hlwMh4QbDE
2️⃣ Reasoning Loop + Memory: Simple loop around a RAG pipeline. Given a user query and previous conversation history, infer a new query to query the pipeline.
We add a simple retry-layer on top of a text-to-SQL query engine: https://t.co/MRKrhorCVe
3️⃣ Reasoning Loop + Memory + Tool Use: A loop around a pipeline designed to pick a set of tools given a user query.
Here we combine reasoning loops with tool use. A simple example here is a retry layer on top of a router: https://t.co/vyGtpplbSl
4️⃣ Fancy Reasoning Loop + Tool Use + Memory: The reasoning loop can get arbitrarily complicated, from sequential ReAct chain-of-thought to LLMCompiler-style parallel planning and tool use.
ReAct from scratch: https://t.co/eGetiu0qj5
Check out our LLMCompiler implementation here: https://t.co/sp0qfpWo9f
🪜 4 Levels of Agents for RAG 🤖
There’s an entire spectrum of agentic capabilities offering simple-to-advanced reasoning on top of your data.
Here’s a mini-🧵 on the 4 different levels of agents and how they can augment your RAG pipeline 👇
1️⃣ Tool Use: A linear pipeline that can query a set of tools given a user query.
The simplest example is a router: https://t.co/hlwMh4QbDE
2️⃣ Reasoning Loop + Memory: Simple loop around a RAG pipeline. Given a user query and previous conversation history, infer a new query to query the pipeline.
We add a simple retry-layer on top of a text-to-SQL query engine: https://t.co/MRKrhorCVe
3️⃣ Reasoning Loop + Memory + Tool Use: A loop around a pipeline designed to pick a set of tools given a user query.
Here we combine reasoning loops with tool use. A simple example here is a retry layer on top of a router: https://t.co/vyGtpplbSl
4️⃣ Fancy Reasoning Loop + Tool Use + Memory: The reasoning loop can get arbitrarily complicated, from sequential ReAct chain-of-thought to LLMCompiler-style parallel planning and tool use.
ReAct from scratch: https://t.co/eGetiu0qj5
Check out our LLMCompiler implementation here: https://t.co/sp0qfpWo9f
Introducing 'Prompt Engineering with Llama 2' — an interactive guide covering prompt engineering & best practices for developers, researchers & enthusiasts working with large language models.
Access the notebook in the llama-recipes repo ➡️ https://t.co/TbLWc7xlD5
Imagine "untraining" a Large Language Model on specific content.
The New York Times doesn't want its content in ChatGPT. OpenAI would have to retrain its models from scratch. Removing any content from their models would cost them millions of dollars.
I just read a new paper from Microsoft Research that tries to fix this. This is the only study I've found so far that's looking into making models forget.
The paper proposes a process that makes a model forget about Harry Potter without retraining it from scratch.
It's a proof of concept. The researchers aren't sure whether their solution generalizes to other topics. It's a first step, but it's cool nonetheless.
What they did is kind of a hack, but I like it:
They fine-tuned the model using a dataset containing the original Harry Potter text as the input tokens and some generic labels as targets. They pre-generate these generic labels. For example, instead of using "Harry," they use "Jack," and instead of using "Hermione," they use "her."
In other words, they don't actually delete knowledge from the model. They overwrite it.
As we start using these models everywhere, the ability to forget information will become critical.
Let's see how much progress we make this year on this.
You'll find a link to the paper in the image ALT.
📢Tasks with > 10k classes (e.g. information extraction) are hard for in-context learning: typically a tuned retriever or many in-context calls per input are used ($$$)
Infer-Retrieve-Rank (IReRa) is a SotA program using 1 frozen retriever with a query predictor and reranker.
📰GPT-Newspaper
This project combines six agents to autonomously build a newspaper - content, outline, everything!
By the same team (@tavilyai) that created GPT-Researcher
Code: https://t.co/5OQDcaFwdN
Merging LLMs Or Better Still - Knowledge Fusion of LLMs!
A couple of weeks ago, Abacus AI open-sourced a merged and stacked LLM. Fundamentally, you are combining multiple pre-trained LLMs to come up with a new model that is more performant!
FuseLLM takes this approach further and explores combining models from a probabilistic distribution perspective. The paper "Knowledge Fusion of LLMs" (link in alt) shows that their approach outperforms the base models, in this case, Llama-2, by as much as 5% on 27 Tasks. This is a fairly significant improvement by combining models!
Merging is having a moment in the LLM world right now, with multiple merged models being released daily! This seems like a pretty inventive approach, and with gains of up to 5%, it will likely get applied by multiple small AI labs.
Our best open-source models are legitimately around 75-76 MMLU, and if we can show a 5% improvement on these models by cleverly merging them, we may hit 80! That puts us with 6 points of GPT-4
Given that these techniques don't need much compute, we will see several approaches in the coming weeks.
A lot of people try to do #softwarearchitecture with #genai. They stuff everything in #ChatGPT and ask a very long and complicated 1-shot question to try to get the #llms to do what they want.
A better approach seems to be agents with reflective reasoning and flow engineering.
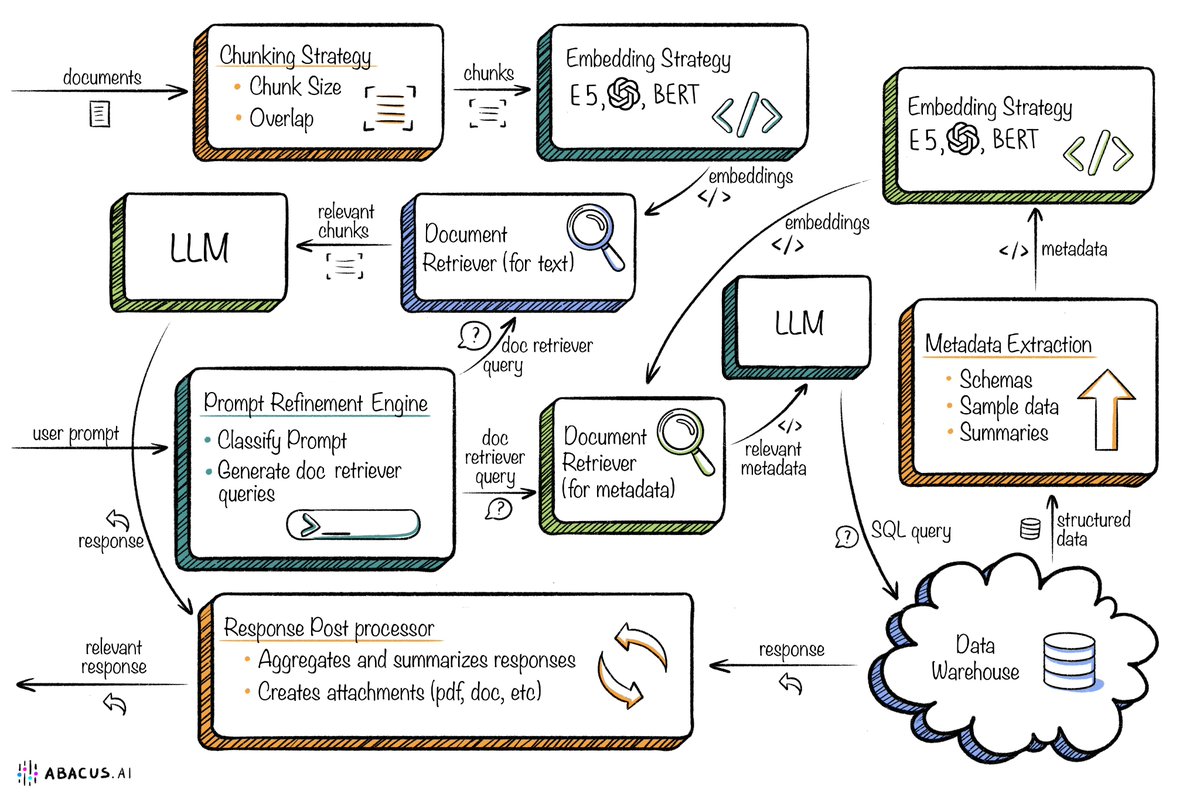
Custom LLM and AI Agents (RAG) On Structured + Unstructured Data - AI Brain For Your Organization
Imagine a ChatGPT-like interface over all your structured (database) and unstructured data. Ideally, you want to ask a question to an AI bot, and it should be able to run multiple parallel queries on your database, look up relevant information from your docs, collate all the relevant information, and create a coherent response.
As an example - it should be able to respond intelligently to the request - Pull the top 10 customers by usage, closed by the sales rep John Doe, and draft a "thank you" email to each of them.
Your AI agent/ Custom LLM must do multiple things to satisfy this request.
- pull all the customers closed by sales rep John Doe from Salesforce
- run a query on Snowflake to get the usage data per customer
- find the thank you email template from your Google Docs folder
- draft emails to all of these customers
Systems that are capable of tasks that are moderately complex, like this one, really improve employee productivity significantly. Organizations that embrace AI in this way will easily outperform their competition.
So here is how you would build this
Data pipelines and connectors - You need connectors to systems like Salesforce, snowflake, and folders.
Chat query orchestrator - you need to be able to parse incoming chat queries, fire multiple calls to an LLM, generate SQL queries, or craft API requests to your vector databases (doc retrievers)
Doc retrievers/vector stores - You must embed and create a vector store for all your shared docs.
Final response creator - A final LLM that will generate the final response based on all the data. In the example above, it would generate the final emails from the email template and the data generated by the SQL queries.
Building these systems from scratch is doable, and there are several open-source libraries you can use to do so. However, the challenge will be iterating on the solution to make sure that the accuracy is high enough to be usable in production.
Several systems have to be tuned, and multiple iterations need to evaluate the system before putting this in production.
Our platform, Abacus AI, can help build, test, and launch a system like this in a matter of days. You can set up the various components quickly and then create multiple iterations and evaluate them across multiple LLMs and configurations.
Finally, you can set up all the pipelines and push the system to production in a matter of days. We offer several open-source fine tunes, which means you won't be paying for an expensive LLM if you don't have to!
More information on our website (link in bio)
First Post.
I'm a software architect who believes most of my job _should_ be replaced by #GenAI.
I've spent the last few days search posts and looking for thought leaders in this space, but it seems like most people are focusing on generating code, not architectures.













![ma_chang_nlp's tweet photo. Introducing ''AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents''
📈Fine-grained Metrics: 🔍 Spotting incremental progress
📊Systematic Board: 🤔 What makes a LLM ace the agent game?
Leaderboard: https://t.co/M5agbiC8cG
Repo: https://t.co/QNQQjluSAh
🧵[1/4] https://t.co/F1OIDDznlw](https://pbs.twimg.com/media/GEqOX3DbMAAKI1J.jpg)