Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
电波曲奇
@aicookie_tech
聊聊模型、产品、AI行业
Joined February 2025
102
Following
310
Followers
153
Posts
电波曲奇
@aicookie_tech
8 days ago
我最近特别喜欢看影视飓风讲AI。 我是搞技术的,关注点很聚焦,都在模型能力和论文上,久了容易形成信息茧房。我一直很好奇,做内容、做创意的人,会从什么视角来审视AI。 影视飓风前两天最新的视频就聊到一个问题:现实世界里扔硬币,拿到正面的概率是50%,那如果让AI来扔呢? 于是,他们在各种AI模型里尝试扔了几百次硬币,结果发现有个模型生成正面的概率高达70%的,有的可能60%。 是的,AI扔硬币,不是50%的概率。 这背后其实是一个非常严肃的问题:大模型的本质是给出概率最高的答案,因为互联网上展示硬币"结果"的视频,如果正面出镜率远高于反面(广告、魔术、纪念币展示等等都喜欢拍正面),AI就被这堆数据修正了,认为正面朝上才是硬币的正常状态。模型并不了解物理世界里的概率,它只认识训练数据里的世界。 影视飓风这期做得很好,用内容创作者的视角切进来,把世界模型这个本来很学术的概念拉到了普通观众面前,尤其是他们团队真的去拍了一部250台相机拍摄的4D高斯VR短片,让你切身感受到"如果AI能一句话生成这样的四维动态世界,创作方式会发生什么"。很感性,很有冲击力。 但这里有个遗憾。 作为视频博主,影视飓风的叙事止步于"AI未来会改变创作"。他们没有、也很难在15分钟的视频里解释清楚:世界模型到底跟现在的Seedance、可灵这类视频生成模型有什么本质区别?为什么它不只是"更好的视频生成",而是一个截然不同的东西? 这个问题,我觉得得回到李飞飞去年10月写的那篇论文:From Words to Worlds: Spatial Intelligence is AI's Next Frontier中寻找答案 李飞飞眼中的世界模型 李飞飞在文章里说:现在的LLM是"暗中的文字达人"(wordsmiths in the dark):eloquent(有说服力)但ungrounded,知识渊博但跟物理世界完全脱节。 她举了几个例子,比如:埃拉托斯特尼(古希腊数学家)通过测量两个城市的影子角度算出了地球的周长;沃森和克里克(现代生物学奠基人)搭建金属板和铁丝的3D分子模型,在空间里转来转去,才发现了DNA双螺旋结构等,这些改变历史的时刻,没有一个是靠语言和写作完成的,全都是空间智能在发挥作用:感知、理解物理关系、在三维世界里推理和操作。 而现有的AI,以LLM为架构,把这一块几乎全部外包给了语言描述。 所以李飞飞定义的真正世界模型,需要三个核心能力: 第一,生成性,能创造出符合几何和物理规律的世界,不只是生成一段"看起来真实"的视频 第二,多模态,能处理图像、深度图、动作指令、手势等各种输入,不只是文字prompt 第三,交互性,给定一个动作,能输出下一个世界状态,形成"行动→世界变化→再行动"的完整闭环。 以至于我自己一直有个判断,可能很多人不同意:单纯靠堆LLM参数,走不到AGI。 语言是人类认知的输出层,不是底层。我们用语言表达思想,但我们形成思想的方式,很大程度上依赖对物理世界的感知和空间推理。你让一个从来没离开过文字环境的人去理解"咖啡杯倒掉之后液体会流到哪里",他可以用文字描述得天花乱坠,但他脑子里依然没有那个流体力学的直觉模型。 世界模型这条路,是在逼AI去建立物理“因果模型”(原谅我在科学中沿用了佛教术语),物理不等于"重力加速度约为9.8m/s²"这句话,而是真的在内部构建一套如果我做了X,世界会变成Y的预测机制。某种意义上,世界模型是另一个方向的AGI探索,跟LLM不是同一条路,但可能更接近智能的本质。 中国在世界模型上没有落后 很多人看完了影视飓风的内容后,很想体验世界模型,曲奇也想让大家了解国内最好的世界模型之一:蚂蚁灵波的 LingBot-World 前段时间,一个叫Reactor的公司:你可以可以理解为"AI时代的Unreal引擎",由前苹果 Vision Pro 团队和 Luma AI 核心成员在硅谷创立,上个月刚拿了5900万美元A轮,在他们这个引擎官方首批集成的模型里,直接选了 LingBot-World。 而且Reactor的工程师还用LingBot-World做了GTA!等不到GTA6没关系,自己搓一个! 拿枪、上车、抢劫、开车逃跑:一个完整的、带故事线的 GTA 任务闭环,实时交互,用键盘操作,AI 实时生成画面响应你的每一个动作,就像Tim在视频里说的,世界模型可以在游戏领域进行投影,给出我们不一样的体验,在Reactor+LingBot-World上实现了 benchmark表现上,今年6月,阿里达摩院联合浙江大学等多所高校发布了一个叫 WorldOlympiad 的世界模型评测榜单,评估维度包括物理真实性、几何一致性和交互真实性,正好对应上了李飞飞说的,这些是世界模型的核心。测试场景覆盖游戏、机器人、通用实景三大场景对世界模型有高需求的场景,贴近真实世界的需求。而在这个榜单中,LingBot-World物理真实性0.942排第一,总分0.683,也排第一。 出色效果和高分的背后,LingBot-World的核心技术亮点是什么? 它解决了世界模型第一阶段领域上一个公认的天花板问题:"长时漂移"。大部分世界模型生成时间一长,场景就会开始塌陷:物体变形、人物消失、结构崩坏。LingBot-World 通过多阶段训练实现了近10分钟的连续稳定生成,这对机器人的长程任务训练来说至关重要。。 回到影视飓风那个硬币实验:影像是我们拓印的真实的世界,但是给你再好的算法、再强的算力,也不能用拓印的画面重绘出那个真实的世界,AI抛硬币这件事如果我们依然按照视频生成的方式去推进,而不是真正的理解空间,他就永远不能趋向于50%的真实概率 这就是世界模型和视频生成模型的分水岭:视频生成在问"这个画面看起来真实吗",世界模型在问"如果你做了一件事,物理世界接下来会发生什么"。 也许再过一两年回头看,我们会说:就是从这个时候开始,我们开始逐步脱离单纯的文本、视频的故事,走向了一个让我们更加兴奋的新方向。
See More
电波曲奇
@aicookie_tech
12 days ago
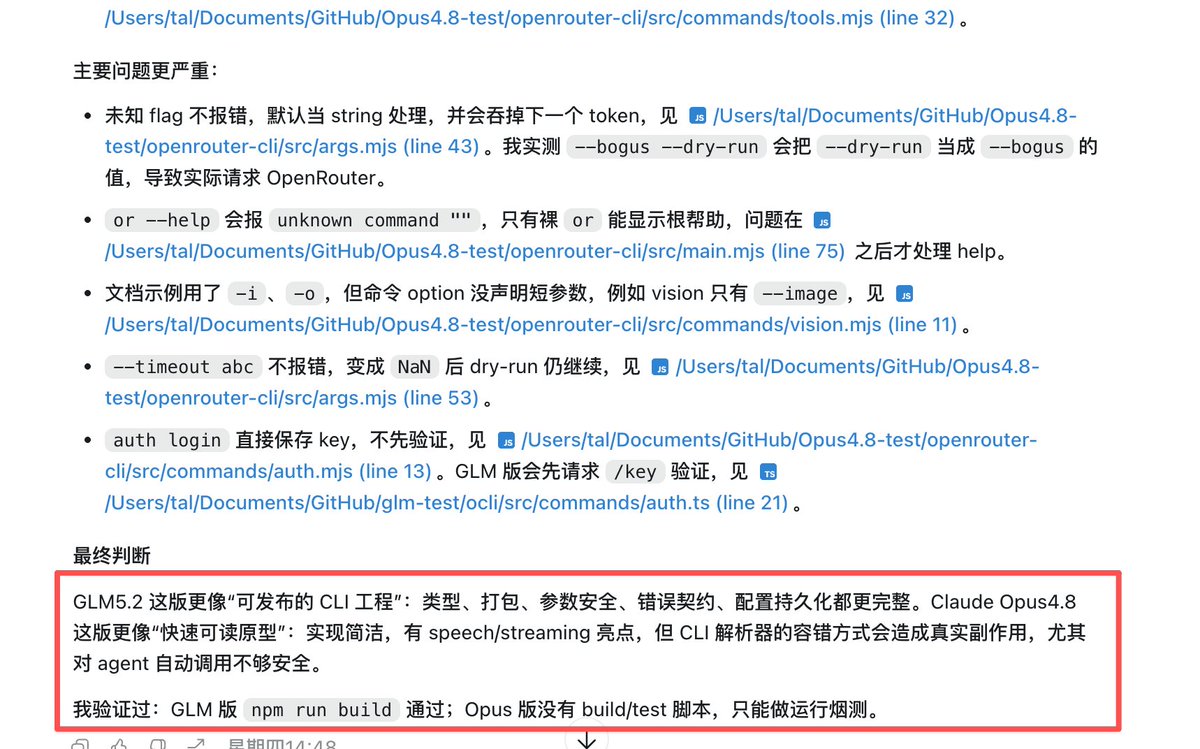
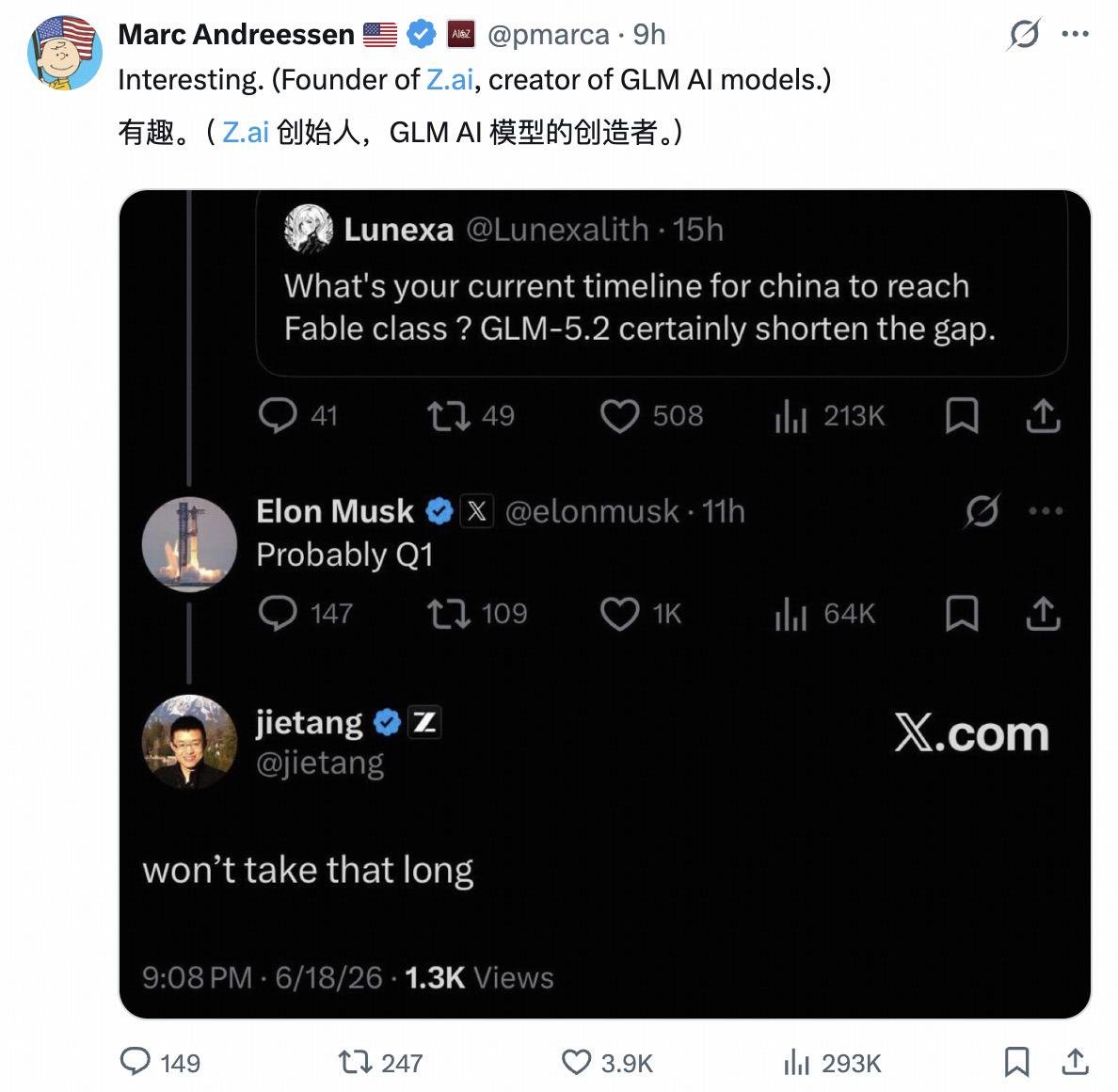
今天大模型科技圈最热的一条对话,发生在 X 上。 有人问马斯克:你觉得中国 AI 什么时候能达到 Fable 级别?GLM-5.2 明显在缩小差距。 马斯克回了两个词:“Probably Q1.” 大概明年一季度。 然后清华教授、智谱创始人唐杰秒回:Won't take that long. 唐老师:我不装了,我摊牌了,后续可能马上就会有比肩Fable的模型出现了!目前看中国的开源已经快成为A➗的斩杀线了! 有不明就里的朋友,这个事情从 Fable 5 被封说起。 6 月 12 日,美国商务部宣布对 Anthropic 的 Fable 5 和 Mythos 5 实施出口管制,非美籍用户,直接断供。 然后,仅仅 24 小时后,智谱发布了 GLM-5.2。 时间点巧合到我一度以为是刻意的。而且智谱官方在发布前还专门写了一段话:在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路,前沿智能不应只属于少数人,不应被少数规则随时收回。 说真的,这段话写得比大多数科技公司的品牌文案都有力量。 反观 Anthropic,满嘴安全、满嘴蒸馏、天天喊我们的模型太危险了不能给所有人用,结果求锤得锤,直接被自己政府封了出口,这帮人是真的很擅长一件把我在保护你和我在垄断你说成同一句话。 而且国内这边就不一样了,GLM5.2 直接 MIT 协议,无地域限制,全权重开放,全球任意下载,成本是美国前沿模型的约 1/10。Hugging Face 这次还破天荒地自掏腰包,给 GLM-5.2 提供了 6 小时全球免费算力,这也是第一次为国产模型开这种待遇。 为什么我也觉得Fable没有那么遥不可及 之前 Anthropic 指责国产模型蒸馏,我当时就觉得A➗有点气急败坏的味道,现在的推测是 Claude 系列的参数规模在 3T 到 5T 区间,结合 DeepSeek V4 以约 1.6T 参数量追到只差 3 到 5 个月代差来看,美国模型可能真的更多是力大飞砖,护城河没那么深,否则怎么解释那么焦虑? 但我也没预料到 GLM-5.2 会以 0.8T 参数量直接追上可能是它 4 到 6 倍参数规模的 Opus,而且GLM-5.2原有的架构还是V3的那一套,能达到现在这个效果,我愿意称之为后训练的工程学奇迹,所以一旦GLM新版的基座架构、预训练的方式有调整,可能我们又会迎来coding能力的新跃迁 实测:直接对比GLM5.2 和 Claude Opus4.8 第一组:让 GLM-5.2 和 Claude Opus4.8 分别写一个 OpenRouter CLI 工具,因为是纯后端的服务,我让GPT5.5给我做裁判,做对比和Review GLM-5.2 的版本更像一个准备发布的工程:使用TypeScript 构建、严格参数校验、结构化错误处理、完整的鉴权流程,功能覆盖包括文本、视觉、图片、视频、模型查询。额外的问题是一些工程接线细节没有完全收口,比如超时参数声明了但部分请求没真正用上。 而Claude 4.8 的版本更像快速原型:代码短、可读性好,流式输出处理得很利落。但基础设施弱很多,比如未知参数不会报错、甚至可能吞掉后面的参数,导致本该 dry-run 的命令真实发起请求。 这种 bug 在生产环境里大概率都是坑。 因为我的Prompt是一样的,所以在这个Case上看:GLM-5.2 在工程完整度和稳定性上明显领先,Claude Opus4.8 更简洁但离可靠发布还差一轮打磨。 第二组:让两个模型分别设计一个 Agent 时代的 CRM 系统原型。 这组对比更有意思。 Claude 4.8 做出来的更像"CRM 加了一个 AI 助手":结构清晰,模块完整,用户好理解,但对 Agent 时代的想象力偏保守。 GLM-5.2 做出来的则更像"以 Agent 重构了整个 CRM":任务中心、Agent 编排台、多 Agent 协同推进商机,不仅仅展示数据,也让模型成为业务流程的参与者和执行者。当然,功能加得多,不稳定感也随之上升,有些入口和交互链路没有Claude跑出来的稳定 (因为我手里没有4.6的服务了,所以有兴趣的朋友可以说说跟4.6的差距) 说到底,GLM-5.2 现在到底跟 Claude 4.8 差多少? 从我的实测来看,基本上是有来有回的水平,在中文指令理解和功能扩展性上,国产这边甚至还略胜一筹。我已经可以不用再看 Anthropic 的脸色了,这种感觉,真的很好。 当前Artificial Analysis 综合榜单上 GLM5.2 拿到 51 分,全球前三,开源 SOTA;FrontierSWE 上与 Claude Opus 4.8 差距收窄到 1%,目前看现在的编程御三家已经彻底从OAG,直接变为OAZ了! 马斯克说"Probably Q1",唐杰说"Won't take that long",现在看来,后者更接近事实。 开源,正在赢。
See More
电波曲奇
@aicookie_tech
15 days ago
@x_chenyuanqi
是这个道理
电波曲奇
@aicookie_tech
15 days ago
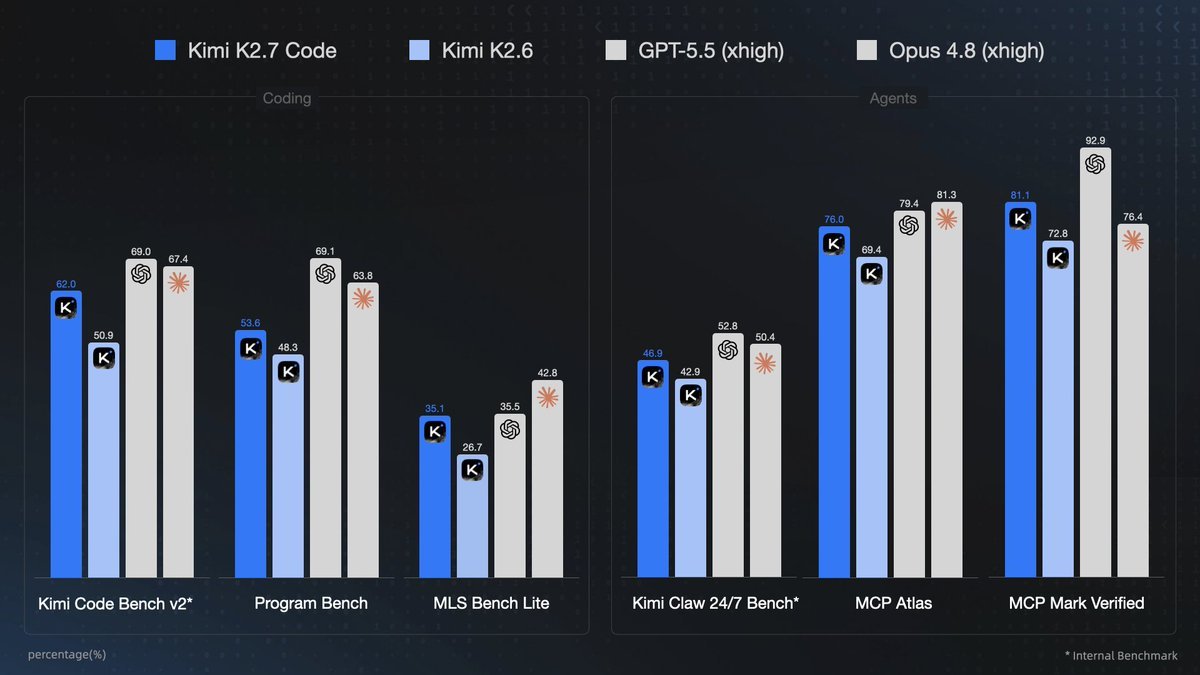
上次写了那篇文科生转AI之后,评论区好多人问我同一个问题:怎么开始自己的第一个AI项目? 其实上一篇我推荐大家用桌面端的Agent,比如Kimi Work,Claude Cowork这些。但后来我想了想,对于学习能力比较强、想一步到位转行AI PM的人,我更建议大家直接上Coding Agent。 为什么?你去看现在AI产品经理的JD,基本都要求具备Vibe Coding能力,能自己产出原型。在这个要求下,桌面端Agent就不太够用了。所以想走AI PM这条路的同学,我还是建议一步到位,直接用Coding Agent。当然如果你时间比较充裕,从桌面端慢慢过渡也完全可以,不着急。 那Coding Agent选哪个? 我建议国内的同学从Kimi Code开始,原因有四个: 1. 不用魔法。这个在国内太重要了,不展开。懂的都懂。特别是费劲千辛万苦用上Claude Code却反被封号后,我想还是应该有咱们自己靠谱的国产Coding Agent。 2. 安装简单,是真的简单。 Mac或Linux用户,打开终端,粘贴这一行: curl -fsSL https://t.co/uVjAsHW8xb | bash Windows用户,打开PowerShell: irm https://t.co/LFLEb1wMDT | iex 装完输入kimi --version能看到版本号就OK了。第一次用输入/login,选Kimi Code平台,浏览器弹出来微信扫个码就完事。整个过程不超过五分钟。 遇到什么报错不懂的,直接复制去Kimi官网问Kimi就行。 3. 模型速度快,这点很重要但一直被严重低估 Kimi刚上线了最新的模型Kimi K2.7 Code,它本身就很快,还有一个高速模式,输出速度是之前的5到6倍,常规编程场景下大概180 Token/s,短上下文能到260 Token/s,大家可以看live图感受一下。 你可能觉得快一点慢一点无所谓。但我觉得关系特别大。 我自己用各种AI Coding工具一年多了,有一个非常真实的体验:人的专注度是有限的。 当AI的思考时间超过某个阈值,你的注意力就飘了。去刷手机、看微信、打开小红书"就瞄一眼"。等你回来的时候,重新投入注意力又要花很长时间。 这是人脑的工作方式。就像你在不同App之间切换,每次回来都要重新"加载"一下。但注意力的切换是有成本的,而且这个成本比你以为的高得多。所以速度快直接决定了你能不能保持在状态里。 而且对于小白来说更重要,本来就在跟不熟悉的东西搏斗,如果还要花大量时间等AI思考,放弃几乎是必然的。 4. 产品有温度 这点是我个人的偏好,我比较喜欢有个人特质的产品。Claude Code思考的时候会显示"Boiling…""Smooshing…"这些可爱的状态词,我就很喜欢,每次看到都笑笑挺开心的。Kimi Code也给了我这种感觉。输入prompt前有小星星,模型回复时有转动的小月亮。一个人对着终端写代码的时候,这些小细节真的会让你觉得不那么无聊孤单。 聊完了原因,我们再直接上Case。我知道很多人卡在"不知道怎么用Coding agent做一个东西出来"。其实核心问题不是不会用工具,而是觉得自己有点想法但没有一个明确的Plan。这个很好解决,你不需要Plan,你只需要一个Idea。 Plan不是你自己想出来的,是讨论出来的。怎么讨论?我强烈建议安装Superpower-Brainstorming。它会通过多轮追问帮你把模糊的想法变清晰:你想要的场景是什么?目标用户是谁?核心功能有哪些?具体功能里你prefer方案A、B还是C所有问题聊完之后,它才会形成一个明确的方案,然后开始帮你做。 你要做的就是回答问题,剩下的事情AI来。 举个例子。我用Kimi K2.7 Code做了一个网页版的Minecraft。给的prompt非常简单:"我想做一个网页版的小游戏,类似Minecraft那种,越简单越好,一个HTML文件打开就能玩。" 然后Kimi就开始多轮问我:地形要什么样?操作方式呢?要不要存档?我就像聊天一样一个个回答,甚至大部分时候直接选ABCD就行。问完之后,大概二十几分钟(还是没开高速的情况下),Kimi K2.7 Code自己就做完了。 最终跑出来的效果:Minecraft初始地形,在浪漫日落下缓缓降落,第一人称WASD移动、鼠标环视,左键挖方块右键放方块,3D物品快捷栏,Ctrl+S存档。一个HTML文件,打开就能玩。 你可能在X上也看到了Claude Fable 5做的类似demo。结果其实跟Kimi K2.7 Code的效果基本没区别了,核心玩法、操作体验都在同一个水准。Fable 5的优势主要体现在基础地形的完整度和结构性上更强一些,但就"做出一个能玩的Minecraft"这件事来说,两者的差距已经非常小了。但价格差距不小。 Fable 5的API输出价格大概是Kimi K2.7 Code的13倍。就算你用Kimi的高速模式,Fable 5也贵了快7倍。你用Kimi做一个项目的花费,用Fable 5得至少乘个十,还要慢上个几倍(哈哈,铺垫几个月结果上线三天就下架,claude你伤我第二次)。 在Coding类benchmark上,我们也能看到K2.7 Code的进步,和上一代K2.6相比大幅提升,Kimi Code Bench提升了21.8%,MLS Bench Lite提升了31.5%。虽然跟GPT-5.5和Opus 4.8还有一些差距,但差距在快速缩小。 对于想用AI开始做点什么的人来说,真正的障碍从来不是"哪个模型最强",而是你到底能不能迈出第一步。安装要不要折腾半天?用起来卡不卡?遇到问题有没有地方问?等AI写代码的时候你会不会等到失去耐心? 这些"小事"加在一起,就是你做完第一个项目和放弃第一个项目之间的全部距离。Kimi Code和Kimi K2.7 Code把这个距离缩得很短。 我觉得这就够了。 剩下的事情,等你做出第一个项目之后再说。那时候你会发现,原来"我也能做出东西来"。原来我和那些每天在X上秀demo的人之间,就差一个打开终端的距离。
See More
aicookie_tech's tweet video.
aicookie_tech's tweet video.
电波曲奇
@aicookie_tech
28 days ago
一个很多人还没意识到的事实:能拿来训练AI的互联网文本数据,快被薅完了。 26年开始你们能感觉到,在AI训练上,数据的核心程度又上了一个级别。姚顺宇前段时间在一场访谈里说了句话,我印象很深:"在相对清晰的范式内,主驱动是数据和算力。自然语言生成已经不是科学问题,只剩工程问题。" 他之前在Anthropic训过Claude,后来去了Gemini,算是同时摸过两家顶级模型的人。简单总结下他的观点就是:算法的大跃迁是阶段性的(比如Transformer),之后就是渐进提效,这种背景下真正决定谁跑得快的,是数据和算力。 算力这头,大家都在砸钱建数据中心,拼的是资本。但数据这头,很明显:互联网上高质量的训练数据不够用了。网上的东西要么质量参差不齐,要么早就被各家扫过好几轮了。模型之间互相“蒸馏”的现象最能说明“不够用、不够好”这个问题,前几天Claude Opus 4.8刚上线就被扒出在API测试里自称"我是千问"。 于是AI公司开始把手伸向现实世界,去采集经过作者构思、编辑校对、时间验证的高质量纸质数据。最近发生的两件事,把这个趋势说得很清楚。 第一件。Anthropic,被扒出来搞了个代号"巴拿马计划"的项目。从图书馆、二手书店大批量买书,用液压切割机把书脊切开,高速扫描仪扫完,然后叫回收公司把拆碎的书拉走。半年,销毁了50万到200万册。内部文件里还写了一句:"我们不希望外界知道我们在做这件事。"最后赔了15亿美金和解。 第二件事更有意思。GPT之父Alec Radford最近发了一个叫talkie的模型,130亿参数,训练数据只有1931年之前的文献,比如书籍、报纸、期刊、科学论文、专利、判例法。没有任何现代互联网内容,没见过一行代码,连"计算机"这个概念都不存在于它的知识库里。然后这个模型通过少样本学习,写出了正确的Python程序。一个只读过蒸汽机时代文献的AI,用19世纪的逻辑推导出了21世纪的编程语言。这说明语言模型学到的不只是"事实记忆",而是某种底层的推理结构。知识真的可以跨越100年泛化。 而这两件事共同指向一个问题:不管是Anthropic拆书扫描,还是Radford手动OCR百年前的旧文献,第一步都是同一件事:怎么把物理世界的文字变成机器能理解的数据? OCR,这个听起来很"古早"的技术,突然变得极其关键了。 Anthropic的解法不太文明甚至很粗暴:液压切割机拆开→压平→标准化扫描。因为传统OCR需要理想条件:页面要平整、光线要均匀、排版要规范。现实世界不满足这些条件?那就改造现实世界,书必须被拆开。 但这不是唯一的路线。百度文心最近发布的PaddleOCR-VL-1.6走了另一个方向:一个只有0.9B参数的小模型,在权威评测OmniDocBench v1.6上达到96.33%,超过Gemini、GPT这些参数大它几百倍的通用大模型,综合性能全球第一。弯折的书页、倾斜的文档、手机随手拍的照片、光线乱七八糟的场景,它都能直接识别。不需要拆书,不需要压平,不需要工业级扫描仪。 PaddleOCR这两年一直很活跃,作为文心大模型体系的一部分,发布了大批创新的论文,GitHub star数已经超过谷歌的Tesseract OCR,成了全球最受欢迎的开源OCR项目。一个不到1B参数的模型做到这个程度,确实有点东西。 当然我也不想搞什么"两种路线之争"的叙事。Anthropic拆书是为了拿训练数据,PaddleOCR是推理端的识别工具,不是一回事。但它们共同指向的趋势是一样的:AI正在从"读互联网"走向"读真实世界",OCR就是这扇门。 说到底,模型要继续进步,终归要去理解更多现实世界的数据。文字上,书是人类知识密度最高的载体,每一本都经过作者构思、编辑校对、出版筛选,大家都说能读书就不要刷手机,对人是这样,对AI也是。talkie已经证明了,哪怕是100年前的书,里面的知识结构依然能教会模型推理。而像书本、档案、古籍这些沉睡在物理世界里的知识,OCR目前来看就是最快、最便宜的路径,这一块百度确实提供了很好的解决方案。 而除了文字,你会发现今年还有很多热点也在指向同一个方向:世界模型、具身智能、原生多模态、全模态……AI正在全方位地学习理解真实世界。文字只是第一步,但这第一步,得先走稳。
See More
电波曲奇
@aicookie_tech
29 days ago
昨天MiniMax的新M3模型发布了 先说结论:MiniMaxM3是我用得最爽的一个模型,但我不想用官方那套话术来夸它。这次我更愿意叫它“水桶模型”。 一、“水桶模型”,是个褒义词 熟悉手机的人都懂,水桶机当年是个褒义词,代表着没有短板,每一项配置都拉满,M3给我的感觉就是这样。 你看现在市面上的国产模型,其实都在偏科: - 同样能上1M超长上下文的DeepSeek V4,没有多模态; - 同样有原生多模态的、Coding能力又强的Kimi 2.6,上下文又没这么长; - 而M3把1M长上下文、原生多模态(图片+视频输入)、顶级Coding能力这三样全凑齐了。 这三件事,恰好是海外那些闭源前沿模型的标配,M3是国内第一个把这套配置集齐的,并且SWE-Bench Pro上它59.0%,超过了GPT-5.5和Gemini 3.1 Pro;SVG-Bench直接反超Opus 4.7;多模态的OmniDocBench也压过Gemini 3.1 Pro。这就不是一般的水桶了,这是个桶壁还特别厚的水桶。 二、能塞进1M,靠的是MSA 这里得插一段技术内容,不然无法解释水桶能力的来源。 长上下文这事,最大的拦路虎是全注意力机制那个平方级增长的先天缺陷,即上下文越长,算力消耗指数级膨胀,硬扛是扛不住的。 Deepseek搞了DSA,而M3的解法是一套全新的稀疏注意力架构MSA(MiniMax Sparse Attention)。简单说,它在算注意力之前先做一轮初筛,但比DSA、MoBA那些方案能更精准地给KV分块,覆盖率更高。再加上算子层面的优化(每块只读一次、访存连续),实测比开源的Flash-Sparse-Attention、FlashMoBA快4倍以上。 在这个架构下,100万上下文,每token的计算量只有上一代的1/20,Prefilling阶段9倍加速,decoding阶段15倍加速。更难得的是,对照实验里MSA的能力跟全注意力基本打平,算力省了,但是模型的整体智商没有下降。 Context从此成了一个可以继续scale的维度。 三、1M上下文+Agentic Coding的能力提升 为了验证它的Agent协同+多模态+编程能力能不能行,结合之前做过的霉霉的应援网站,我让MiniMax M3给20位顶级歌手每个人都做一个应援站。要求只有一个:每个站的风格必须贴合歌手本人。 在MiniMax Code上(Minimax新的编程平台),多Agent协同的稳定性超出预期,整个任务从创建到完成跑了5-6个小时,期间是一整个Agent团队在协作: - 核心Agent:负责规划任务、收集下面子Agent返回的所有结果,掌控整个任务流程 - Coder Agent负责搭网页结构、写代码; - General Agent负责搜集每位歌手的资料、填充内容; - Verifier Agent是点睛之笔,它靠M3的多模态能力直接截图,像个真人设计师一样审视整体排版和视觉效果,发现别扭再打回去调整和修改。 在这套循环里,因为有了更长的1M的上下文,所以Agent在Plan设计、任务追踪、跨文件校验上都有很好的指令跟随能力。而且这次并不是简简单单的做一个明星的主页,里面即包含了对歌手风格的定义、主打歌曲的试听和链接、相关歌手的介绍内容与总结、专辑的时间线和封面等等等等,每个任务都包含了信息收集分析以及和设计挂钩,并且任务量还要✖️20,幸运的是中间并没有出现任何运行的差错!(反正我是从夜里12点跑的,早上5点收的菜,一把成功) 而且Verifier Agent的多模态能力是真正的胜负手,通过视觉能力直接对网页进行审核,避免了以前的Agent写完代码基本是盲交的问题,以至于根本不知道渲染出来好不好看;现在它能自己看、自己嫌弃、自己返工。 而输出的结果就是:M3有着非常优秀的前端审美能力,给出了超出了我的想象的结果! 四、非常优秀的前端审美能力 Bruno Mars、Beyoncé、Ariana Grande、Lady Gaga…… 其实给这些明星每个都做个网站,其实并没有什么难度,但是M3真正做到了每个明星的页面风格全然不同,但又都精准踩在他们各自的气质上。 比如Bruno Mars,整体是深邃皇家紫+黑底+金色的配色,整个调性沉稳、奢华、复古,跟他那种老派Showman的舞台感严丝合缝;但LadyGaga完全反着来:纯黑底配霓虹荧光的洋红、青、黄、紫,前卫、攻击性、不好惹(而且还有点击专辑切换主体色的小Trick);A妹整个都是粉粉嫩,圆角卡片,大量留白,整页都飘着soft girl的奶气。 盆栽的黑暗、碧梨的神经色、Beyoncé的深沉稳重,都被M3在前端实现上运用的很好,能够将颜色、版式、风格融合在一起,并且也看不出来前端设计的AI味,固定模版味。今天我们算是终于摆脱了居中大标题、紫蓝渐变、圆角卡片配emoji的AI前端设计N件套,有需要的朋友可以重构一下之前claude code写的前端页面试一试... 五、最后 聊点实在的,M3现在能在MiniMax Code、Token Plan和API里第一时间用上。个人开发者我建议直接上Token Plan,性价比挺高的、年包还有优惠,趁着这次还没有售罄赶紧屯一波 现在模型迭代快得让人麻木,几乎每周都有屠榜、碾压的标题。但抛开营销噪音,M3给我的体感是扎实的:它不靠某一项极端长板出圈,而是把长上下文、多模态、Coding、长程Agent这几件事同时做到了水准线之上,还顺手点亮了审美这个大多数模型的盲区,我会将很多前端相关的业务迁移到M3上,希望后续能持续给我带来惊喜。 这两月模型发的太多,都测麻木了,但是今天的我就像当年拿到的第一台水桶手机一样,还是有那么一点快乐、还有那么一点兴奋的。
See More
电波曲奇
@aicookie_tech
about 1 month ago
广告界有一句流传了一百多年的老话:"我知道我的广告费有一半浪费了,但我不知道是哪一半。" 说这话的人叫约翰·沃纳梅克,美国百货业的祖师爷。第一个给商品明码标价、第一个大规模做报纸广告、第一个喊出“不满意就退款”的人。基本上今天零售业和品牌营销的那套玩法,是他一百多年前打的样。 但就是这么一个把广告玩到极致的人,到头来也认了:钱花出去了,但不知道花对了没有。一个顾客走进他的百货商店买了件大衣,他没有任何办法知道这个人是因为看了报纸广告来的,还是朋友推荐的,还是路过橱窗进来的,还是人家本来就打算买大衣、有没有广告都会来。他能看到这个月花了多少广告费、总销售额是多少,但这两个数字之间的因果关系,是一个黑盒。 这个问题有一个专业名字,叫归因问题。你没办法把"结果"准确地归因到"原因"上去。 而且"有一半浪费了"甚至是乐观的。2006年,Rex Briggs和Greg Stuart两位研究者审计了30家跨国公司超过10亿美元的营销支出,发现有效比例不超过37%。也就是说,浪费的不是一半,接近三分之二。 一百多年过去了,媒介从报纸变成了信息流和短视频,品牌的预算疯狂加加加,但你问问任何一个品牌操盘手、业务线的PR,这个问题解决了吗? 说实话,有进步,但没解决。随着互联网的发展和营销数字化转型,我们有了数据和技术手段,能看清用户从哪来的、点了什么、在哪下的单。比如Cookie追踪、数据中台、多触点归因模型。但它们本质上都是在给已经发生的事做总结。事后总结做得再好,也改变不了钱已经花出去的事实。 真正让品牌头疼的问题是:钱花出去之前,能不能先知道哪个方案更好? 假如现在有4套创意、3组达人、2档预算,24种组合。现实中你只能拍脑袋先挑两三个跑两周,烧几十万看数据,不行再调。剩下那些没试过的方案里,可能就藏着最优解。但你永远不会知道,因为预算和推广周期是有限的。 其实"用数据做预测"这件事在其他领域早就跑通了。大模型在做天气预报、时序预测甚至股市趋势分析,准确度早就开始超过传统方法。但营销这个每年全球万亿美元级别的市场,在"花钱之前先预测效果"这件事上,还在初期。 最近看到一个来自深圳的AI营销公司橙果视界做的产品,叫OranSim。这家公司服务过70多个品牌客户,去年营收过了两千万,是懂营销的。他们做的事情说起来很简单:在花真金白银之前,先在虚拟世界里把你的广告"投"一遍。服务过70多个品牌客户,年营收过了两千万 它建了一个100万人规模的虚拟消费者社会,每个人都有AI驱动的消费人格,各自有各自的内容偏好、消费习惯、对不同类型内容的反应模式。后面跑着430万+小红书帖子、210万+达人档案、10万+真实消费者样本,而且每天在更新。你把真实的广告素材丢进去,选好达人组合和预算分配,它在几分钟内模拟这条内容发出去之后的全过程:谁会点、谁会划走、谁被种草了、情绪在人群里怎么扩散。24种组合?全跑一遍,按预测ROI排序。 具体能干嘛?我们可以想下这几个场景: 1️⃣投放前选方案。咱们有的所有创意×KOL×预算组合,全丢进去跑,按预测ROI排序。花费基本为零。挑排名前几的再拿真预算去实测,相当于用0成本先帮你淘汰掉大部分差方案。 2️⃣投放中调整策略。 投了三天发现CTR不达标,想换掉两个达人、预算重新分配。换了之后14天的效果会怎么变?不用等两周看数据,30秒就能跑出一条对比曲线,当天就能做决策。 3️⃣投后复盘搞清楚。 这轮ROI不理想,老板问"当初为什么不把预算押小红书??"。以前只能糊弄下说"下次注意",现在把实际数据导进去,跑一个"全押小红书"的反事实模拟,用数据说清楚。 这三件事,以前分别需要不同的工具、不同的方法论、不同的数据源,而且大多只能事后分析。OranSim把它们放在了同一套引擎里,而且是事前预测。 回到沃纳梅克那个问题"浪费的那一半到底是哪一半"。OranSim的思路是:你还没花出去,就能先看见。不是等花完了再归因,而是花之前就把大概率不行的方案排除掉。 当然得说清楚:任何预测都是模型,模型就有边界。100万虚拟消费者不等于真实世界,不可能100%预测准。但问题从来不是要预测得多精确,天气预报也不是百分百准,照样每天有几亿人在用。关键是:在你把真金白银砸出去之前,能不能先花零成本排除掉明显不行的方案?如果24个组合里能先筛掉20个,只花钱测4个,就已经够值当了。 沃纳梅克活在一个没有数据的时代,他只能认命。我们有数据、有算力、有AI。"浪费的那一半",也许终于可以在花出去之前就被看见了。
See More
电波曲奇
@aicookie_tech
about 1 month ago
训练一个AI需要三样东西:算力、算法、数据。 关于数据,明面上都知道的是:要干净、要多样、要大规模。于是所有人都在卷数据清洗、去重、质量过滤,卷了好几年。 但有一个维度,几乎没人认真谈过:频率均衡。 你的数据可以很干净,很多样,体量巨大。但如果某些词在训练数据里出现了几百万次,另一些只出现了几十次,模型对后者的掌握程度和前者完全不在一个量级上。 5月,MiniMax翻了个很出圈的车。模型无法输出任何和马嘉祺有关的信息。问它时代少年团有谁,其他人的名字都说得清清楚楚,问到马嘉祺,就卡壳乱编了,说有"佳琪"、"马琪琪",反正不说马嘉祺。诡异的是,MiniMax口碑不错,跑agent任务也稳得很。训练数据量够,数据也干净。 问题出在哪?分词器把"嘉祺"切成了一个独立token,而这个token在后训练数据里,几乎没出现过。高频token每轮训练都在刷新参数、膨胀空间,把"嘉祺"这种低频选手挤得越来越边缘,挤到最后模型想说这个名字的时候,已经找不到它了。 所以不是智商问题,是单个token的练习量问题。 MiniMax后来做了件事来复盘整体token的健康度:扫描了模型全部约20万个token,发现4.9%的token在后训练后明显退化。按语言看更夸张:英语3.5%,中文3.9%,日语29.7%。将近三分之一的日语表达能力,训练完就废了。直接后果是模型说着日语突然蹦出俄语,在修复前这个比例高达47%。 数据够大,也够干净。但频率分布上有洞,模型就有盲区。这件事5月借着“马嘉祺”的名字传遍全网。 但有个团队,一年前就把这个问题回答了。国内一家AI公司脸谱心智和香港中文大学林伟教授课题组合作,2025年就在NLP顶级会议EMNLP上发了一篇论文叫SLoW。他们在100种语言上系统性地证明了一件事:低频词就是大模型的软肋。 有趣的是,这个灵感来的也突然,据说是脸谱心智的CEO洗澡时候想到的。 研究的场景是AI翻译外语。常规翻译是把整本字典塞进prompt,相当于考试时把教材给学生参考。但脸谱心智他们反着来:只给低频词,高频词一律不给。 结果:token省了近一半,翻译质量反超提供全量字典的场景。并且在100种不同语言的场景上,表现几乎一致。 为什么给全量字典反而更差?信息过载。模型本来就认识高频词,你再告诉它一遍等于添加噪音,反而分散了注意力。就像考试时抱着整本教材翻来翻去的同学,不如只带一张cheating paper的人考得好。 还有个发现很关键:你不需要知道AI到底读过什么训练数据。 用公开的词频数据库估计一下哪些词出现频率低就够了。公开数据和真实训练数据的词频分布足够接近。这意味着任何人都能用这个方法改善AI翻译,不需要任何内部权限。 SLoW解决的是单词层面的问题,找到模型不认识的词,给它补课。但一个自然的问题浮出来了:如果低频是弱点,那反过来,主动使用高频表达,能不能直接增强模型的表现? 2026年4月,同一个团队的第一作者陆弘远在ACL主会上给了回答,提出了 "文本频率定律"(Adam's Law):大模型对高频文本天生理解更好、生成更准,这是所有大模型的结构性特征。 这篇论文把频率研究从单词拉到了句子层面。他们构建了一个数据集:同一句话,用GPT生成20种不同说法,选出"最高频"和"最低频"的版本,再由三位语言学背景的标注员确认语义完全一致。然后用这些"同义不同频"的句子对去测模型。 结果是用高频版的句子时,模型能力大幅增长:数学推理上DeepSeek-V3准确率从63.55%升到71.54%。翻译场景里,100种语言里99种有提升。最贴近生活的常识推理上,所有测试模型一致提升 这里有个很容易误解的点:"高频"不等于"简单"。论文专门测了文本复杂度和频率的相关性,结论是几乎为零。一句话用词高频,不代表它就更口语化或者更小白;一句话用词低频,也不代表它就更专业或者更高级。频率是一个独立于复杂度的维度,衡量的是"这些词在互联网上被写出来过多少次",而不是"这些词是高级还是简单"。但大家直觉上普遍认为常见的说法=不复杂,这也是为什么这个维度之前一直被整个行业忽视。 除了推理侧,训练侧也有发现:把训练数据按频率从低到高排列,如果模型先学罕见表达,再学常见表达,翻译Pangasinan(一种极少人关注的菲律宾语言)的分数提升了29.96%。 两篇论文,一年之内,从单词到句子,从补短板到扬长板,从推理到训练,脸谱心智的两篇论文都指向了一点:频率均衡是数据质量被忽视的第四个维度。 他们补上的,正是数据三要素之外那个长期缺失的维度。数据不仅要干净、要多样、要大规模,还要频率分布均衡。 一家公司能比行业早一年看到这个洞,往往不是运气。眼下大部分新兴AI公司都在抢高频赛道:做产品、卷应用、追风口,高频能更快地被大众看见、被市场定价。脸谱心智走的是另一条低频的路:研究导向,去啃模型行为背后的原理,去做世界模型这种十年尺度的方向。 真正懂行的人已经看见了。有头部资本在关注这家公司。最近他们官宣了,一位千亿市值上市公司的联合创始人,作为商业化合伙人,并拟邀一位发表过上千篇论文的知名教授,出任首席科学家。一个负责让研究做得够深,一个负责让研究活得够久。公司主营业务为世界模型,对标国外LeCun、李飞飞等创办的World Labs,估值已达数百亿元人民币。 研究"模型会忘记谁"的团队,自己选的也是那个不够高频、却更长期的位置。 而频率分布本身不是一个技术参数。它是人类社会注意力分配的倒影。 互联网上被谈论最多的语言、话题、名字,自然成了高频;那些小语种、冷门知识、少数群体的表达,就沉入了低频区。MiniMax的日语退化率是英文的八倍多。不是因为日语更难,而是因为训练数据里日语更少。AI的盲区不是随机的,它精确地映射着我们这个世界选择让谁被看见、让谁被遗忘。 一个人的名字在算法眼里只是一个频率不够高的向量。技术上叫"低频token退化",更直白一些说就是:如果你不够"主流",机器就可能记不住你。 我们喂它什么,它就变成什么。而我们喂它的,不是世界本身,只是世界被记录下来的那一部分。
See More
电波曲奇
@aicookie_tech
about 1 month ago
我刚入行的时候,就被老板们教育过一句话:“一图胜千言。” 当时我还挺信这句话的,后来也确实变成了Visio、ProcessOn的重度用户。流程图、架构图、XML结构、甘特图、系统调用链,能画尽画。毕竟很多东西你用文字讲半天,别人还是一脸懵,也没人愿意看2000字以上的长篇大论;但你把图往那一放,哪怕画得丑一点,大家也能瞬间理解你想表达的事情,沟通就容易很多。 但问题也在这里:所有人都喜欢看图,没人喜欢画图。 尤其是复杂图表这件事,在我看来本质上就是反人性的。你得先把业务或者代码理解一遍,然后抽象出模块关系,再考虑层级、布局、配色、箭头、泳道、备注、异常分支。好不容易画完了,会议上有人提出质疑,又要涂涂改改,麻烦的要死! 性价比太低,所以这些年我画图的频率是越来越低了。直到最近,飞书CLI的画板能力把画图这件事变得非常简单,所有人都可以无痛画图。 再说下背景(其实已经说了很多次了),飞书的开源CLI项目在GitHub上已经10000+Stars了,今年3月底发布首日就破千,一个多月翻了十倍。这次更新的内容是:新开放了画板(Whiteboard)的写入能力,可以直接让Agent生成画板图表并写入飞书文档。 并且关键是飞书画板可以把SVG、Mermaid、PlantUML,甚至更底层的OpenAPIJSON都写进文档画板里,而且SVG还会被解析成飞书原生的可编辑节点。也就是说,图里的矩形、圆形、文字、连线,进到飞书之后还能单独选中、移动、改字、改颜色。 这就很不一样了。 它更像是把画图这件事拆成两段:让Agent负责生成初稿,让人负责最后判断和微调。这才是符合人性的工作流。人类不应该从0开始拖框拉线,而且需要借助Agent本身的能力完成图画构建的这个任务! 我最近拓展出来的第一个场景,是代码库架构分析。 现在DeepSeek这类模型已经有超长上下文,1M上下文一上来,很多中大型代码库已经可以被Agent相当完整地理解。以前的问题是,Agent看懂之后,给你吐一篇Markdown文档。文档当然有用,但对于复杂项目来说,模块和模块之间的依赖、数据流、调用链、层级关系,用文字表达总是难以理解和总结之间的关系 这次飞书画板基本补上了输出的“最后一公里”。 我拿之前ClaudeCode泄漏的源码做了个实验。直接把整个代码库喂给Agent做架构分析,然后让它输出为SVG,通过飞书CLI写入画板。出来的效果就是你们看到的这张图:ClaudeCode代码架构全景图,从入口层、UI层、核心引擎层、工具层、服务层到支撑层,六层架构一览无余,每一层里的核心文件、职责说明全部标注清楚。 这要是让人手画?我保守估计,一个熟练的架构师也得画小半天。Agent+飞书画板,几分钟。 更厉害的是,如果你需要更细粒度的拆解,比如你想知道ClaudeCode到底是怎么做上下文管理的,系统提示词怎么组装、压缩策略有哪几种、Token预算怎么决策,同样的方式,直接输出一张完整的流程图。八步上下文组装流水线、六种压缩策略、记忆系统加载顺序、Hook注入点……全部可视化地铺在一张图上。这种信息密度,你用纯文本文档写,读者大概率看三段就走神了,但一张结构图扫一眼就能建立全局认知。 照这个思路推演下去,我们日常工作中所有的业务流程、接口数据流转,都可以用同样的方式生产。 举个例子,微信支付的JSAPI合单支付业务流程,这个东西微信官方文档里也有图,但说句得罪人的话:手画的就是不好看,信息层次也不够清晰。而你看通过飞书画板输出的版本,商户前端、商户后端、微信支付系统、用户四个角色分列清楚,六个步骤从下单到退款完整串联,连合单支付订单状态流转图都附在下面,整个流程模块清晰完整了不止一个档次。 这类图的价值,其实不只在研发内部。对外接口文档、售前方案、客户培训、业务SOP,都可以这么干。以前这些东西要么靠产品经理手搓,要么靠设计同学友情支持,要么干脆直接截图凑合。现在至少有了一个更轻的路径:先让Agent生成,再让人审核和修。 而且因为本质上是SVG生成,飞书画板的应用场景远不止开发领域。 比如教育场景,我做了一张水循环的卡通示意图,蒸发、凝结、降水、径流、地下水流,全是SVG路径画出来的,带卡通风格的山、云、太阳,写入飞书画板后每个元素都可以编辑。给小朋友做科普、给学生做课件,这个效率和效果都是PPT手搓没法比的。 再延伸一下,文档的前置总结图、产品功能脑图、甚至简单的海报设计,只要是SVG能表达的视觉内容,理论上都能走这条路。 这点我反而觉得更重要。 过去图表是文档里的静态附件,谁画的、怎么画的、后来改了什么,基本不可追踪。以后图表可能会变成一种代码资产:由脚本生成,由Agent更新,由CLI检查,再写入文档。架构图可以随着代码库变化重新生成,业务流程图可以随着接口定义自动更新,学习路线图可以根据课程内容自动重排。 飞书画板CLI做的事情,本质上是把"画图"这个反人性的工作,变成了"描述图"这个顺人性的工作。你不再需要关心框多宽、线怎么连、对齐差几个像素。你只需要告诉Agent你要表达什么,剩下的生成、渲染、质量检查、写入文档,全链路自动化。 我很喜欢这样:代码即图表,图表即文档,文档即交付,Over!
See More
电波曲奇
@aicookie_tech
about 2 months ago
这几年大家都在追捧一件事:做AI产品。不管是AI搜索、AI助手还是各种Agent。但我一直觉得还有一个同样重要甚至被低估的方向:对已有产品做AI化。 道理其实很简单。一个是做App早就是存量市场了,你做一个AI产品,竞争对手不是另一个AI产品,而是小红书、淘宝这些已经占据用户时间的巨头,抢注意力太难了。二是你从零做一个AI新物种,DAU能跑到多少?几十万?几百万?AI融入的程度还是很低。但如果是淘宝这种量级的产品被AI重塑,影响的是数亿人的使用习惯。做AI产品是从0到1,产品AI化是从1亿到下一个1亿。 杠杆效应完全不在一个量级。 突然聊这个,因为昨天看到了淘天金码奖团队赛命题《AI原生淘宝》,让你重新想象:如果今天从头发明淘宝,它应该是什么形态?这就是"产品AI化"的终极命题。 简单介绍一下背景。这个比赛的前身是2014年的淘宝技术金编码奖,早年就是个代码评优比赛,但这几年已经完全变成AI时代的技术文化赛事了,比看代码有意思多了,咱们也都能看懂。今年吸引了1000多名技术员工报名,最短司龄才3个月(也就是刚入职就冲进来参赛了,小伙子有拼劲) 那这1000多个工程师拿到"重新发明淘宝"这个命题,会怎么做?我本来以为大家会疯狂堆AI能力,就像很多团队目前在业务场景里做的那样,比如更智能的搜索、更精准的推荐、更强的多模态理解之类的。但看完方案我发现,当大家真正拥有从头重构的自由时,思考的不是"怎么让AI更强",而是"人和商品之间的关系到底应该是什么样的"。 冠军团队"达拉然"(对,就是魔兽世界的达拉然)把整个购物体验拆开重组,核心设计理念是:所有关键决策都是一次滑动:左滑拒绝,右滑接受。 对,你没看错,像Tinder一样买东西。让你在有限信息下快速做出直觉判断。 其他团队的脑洞也很有意思:有团队想把淘宝变成一只专属性格的"电子宠物",有团队做奇迹暖暖式的养成系AI淘宝,甚至带有情感养成和成就系统。还有团队做的是4只有记忆、有判断力的购物搭子精灵,越用越懂你。所以你会发现,这帮工程师在想AI的时候,脑子里想的不只是"更快""更准",他们想的是"更懂我""更像一个活的东西"。 其实从这个比赛能看出淘天内部的AI氛围确实挺浓的,内部的AI投入是多维度且自上而下的。往技术底层看,过去5年淘天在ICLR、ICML、NeurIPS这些国际顶会上发了300多篇论文,往应用落地层看,面向商家的"生意管家"已经升级成电商首个Agent工作台,1个AI店长带6个AI员工帮商家经营,双11期间生成了500万条经营策略,帮商家平均省了30%工作量。甚至连实习生都能拿到和正式员工一样的Token额度和AI工具权限,购买外部AI开发工具还能报销(让我去!!!) 回到开头我们讲的:AI时代,可能不只要关注最新的AI产品,主力产品的AI化,同样是一条充满想象力的路。淘天金码奖某种程度上就是这个逻辑的缩影,不是另起炉灶做一个AI电商,而是让1000多个工程师去思考:淘宝这个已经服务了数亿人的产品,在AI时代应该被重新发明成什么样子。 这个问题的答案还在路上,但光是看这些参赛方案里涌现出的想象力,你会发现,任何一个你以为已经定型的产品,在AI面前都还远没到终局。
See More
电波曲奇
@aicookie_tech
about 2 months ago
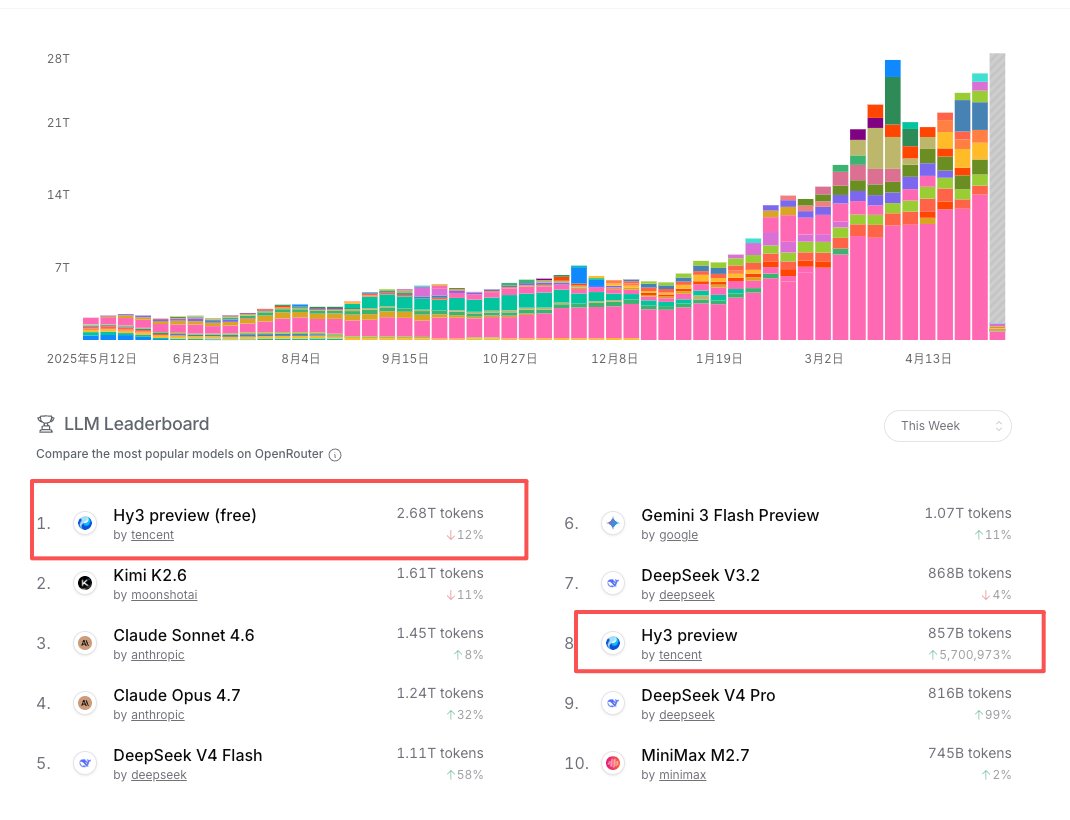
节前曲奇就跟大家聊过,混元3 Preview这次画风变了:不打榜,不卷分数,好好紧盯落地场景,但当时评论区质疑声一片,大致还是不相信腾讯会在AI领域有很大的转变。 好,现在数据替我说话了。 截至5月11号,Hy3 Preview在OpenRouter周榜上稳坐第一,并且高达2.68T tokens的周用量,占整个平台12%的流量。对的,一个腾讯的模型,在一个海外开发者为主的路由平台上,吃掉了八分之一的流量,并且收费后依然没有看到猛烈下降的趋势,看这个样式还要在榜一数周。 "曲奇你又在尬吹,不就是因为免费吗?某米登顶不也是因为免费!" 来,我帮你们查过了。Hy3 Preview free版的到期提示是5月8号,我看榜的时候已经是5月11号了,免费结束整整三天,它依然是第一,并且在5月11号的日榜上Hy3 Preview的收费版也登顶第一了。如果只是薅完羊毛就跑的流量模型,三天前就该断崖式下跌了对吧?没有,这说明用户跑通了工作流之后,压根没打算换模型。 而在使用场景的分布,大部分都落在了主流Agent和Coding的场景上: -Hermes Agent:5.82B tokens -OpenClaw:1.44B tokens -Kilo Code:1.12B tokens 这已经不是那种用户随便聊两句,或者"帮我写个周报"的chat流量,这是大量的开发者把混元3 Preview塞进自动化工作流里当LLM引擎来用。说实话,混元之前的版本完全不会出现这种现象,以前谁搞agent会第一时间想到腾讯的模型? 而且价格上:混元3 Preview的输入$0.066/百万tokens,输出$0.26/百万tokens。DeepSeek V4 Flash呢?加权均价输入$0.073,输出$0.281,几乎是同一档位的价格,但是在这个价格区间驱动Agent上,混元3 Preview的效能甚至好于DeepSeek V4 Flash一截! 混元这次到底做对了什么?我总结就三点: 第一,不打榜了,把精力从刷分转向了agentic workflow的实际优化,OpenRouter官方描述里直接写的就是"面向agent工作流和生产场景",定位清晰 第二,价格诚意够, 跟DeepSeek V4 Flash几乎平价,开发者没有成本顾虑。 第三,踩中了/紧随Agent风口, 2026年上半年整个行业都在往agent方向冲,混元3 Preview恰好在这个节点拿出了一个agent场景下真正可用的模型! 说实话曲奇关注国产大模型这么久,混元3 Preview这次是我见到的第一次在海外开发者社区里靠实际用量站稳脚跟,不是靠发论文,不是靠刷排行榜截图发推,也不是靠,而是开发者真的把它塞进了自己的agent里跑起来了。 这才叫翻身,不是翻给媒体和热搜看的,是翻给用户看的。
See More
电波曲奇
@aicookie_tech
about 2 months ago
前阵子我测 qwen3.5-omni 的时候,顺手给自己搓了一个 Mac 上的语音输入法demo版,因为对于一个每天都跟Agent打交道的我来说,快速的、有大量内容输入的场景是刚需。一个复杂的任务描述,用嘴说然后让模型来理解,要比你冥思苦想kuku打字憋半天要强多了! 这件事让我越来越确信一个判断:语音输入一定是未来的核心交互趋势。 打字这个事情,本质上太依赖人类的后天训练了,你得学拼音、学键位、练肌肉记忆,才能真正做到"想什么打什么",但说话不用。说话是人类最自然的输出方式,中间不该有这么重的转译成本。 所以这几年我一直在关注这个赛道的产品。之前用过 Typeless,体验确实不错,但是它的订阅我之前就吐槽过,对于一个输入法品类的产品,一个月20刀还是太贵了。我自己也尝试用开源模型搓 Demo,核心功能能跑通,但很多细节的打磨一个人完成太累了。 现在我急需一个免费的、好用的、不影响我Mac原生输入法的产品,也恰恰好今天千问App电脑端自带的语音输入法发布了,切中了我的所有需求,而且免费。 第一个是语音输入的"净化"能力。 它能自动去掉"那个""额""嗯"这些语气词,同时对内容做纠错和格式化整理。这个听起来简单,但真正做过的人知道,光是这部分的模型调优就够折腾很久的。它不只是做 ASR 转写然后删几个词,而是基于上下文去理解你到底在说什么,然后重新组织成干净的书面表达。 第二个是我最喜欢的:口误实时纠正,这个能力之前一直是Typess主打,非常上瘾。比如你说"帮我订一个五点...不对好像是六点的会议室",它不会傻乎乎地把"五点不对六点"全打出来,而是直接理解你的意思,输出"会议定在下午六点"。就这一个功能,就能让语音输入的可用性直接上一个台阶,因为人说话就是会改口的,能处理改口的输入法才是真正懂人话的输入法。 但如果只有以上这些,它也就是个还不错的语音输入工具而已。真正让它和那些纯输入法产品拉开差距的是它支持在语音输入的同时,可以直接调用千问的全部ai能力。 比如你正在写文档,想插入一个数据,直接说"帮我查一下英伟达2025的年的股价涨幅",它就给你查了然后插进去。浏览英文论文看不懂一段话,划选之后说"帮我翻译一下",翻译直接出来。不用切窗口,不用复制粘贴,不用打开浏览器,嘴一张就完事了。 搜索、翻译、解释、总结,全都是语音一句话的事。 更进一步的是,它还能感知屏幕上的内容。别忘了千问还有一个很强的全模态基座。这次真正超出我预期的,是它能感知屏幕上的内容,然后根据上下文执行指令。举个最实际的例子:你收到一封客户的小语种(比如西班牙文)邮件,不用自己组织,对着麦克风用中文说一下大概意思,它直接在输入框里生成格式规范的西班牙文回复。在微信群里有客户突然@你,你说"帮我生成一段高情商回复",它读完对话上下文,直接给你写好。这已经不是输入法了,这是一个能看懂你屏幕的 AI 助手,只不过入口恰好是语音。 简单总结一下:市面上做 AI 语音输入的产品不少,但要么收费不低,要么只解决了"语音转文字"这一层。千问这次做的事情是,把语音输入、语义理解、屏幕感知和AI 能力调用全串在一起,然后免费塞进了自己的 App 里,作为一个产品的完成度是到位的,感兴趣的朋友可以自己去试试,尝试一下口喷驱动Agent的快乐!
See More
电波曲奇
@aicookie_tech
2 months ago
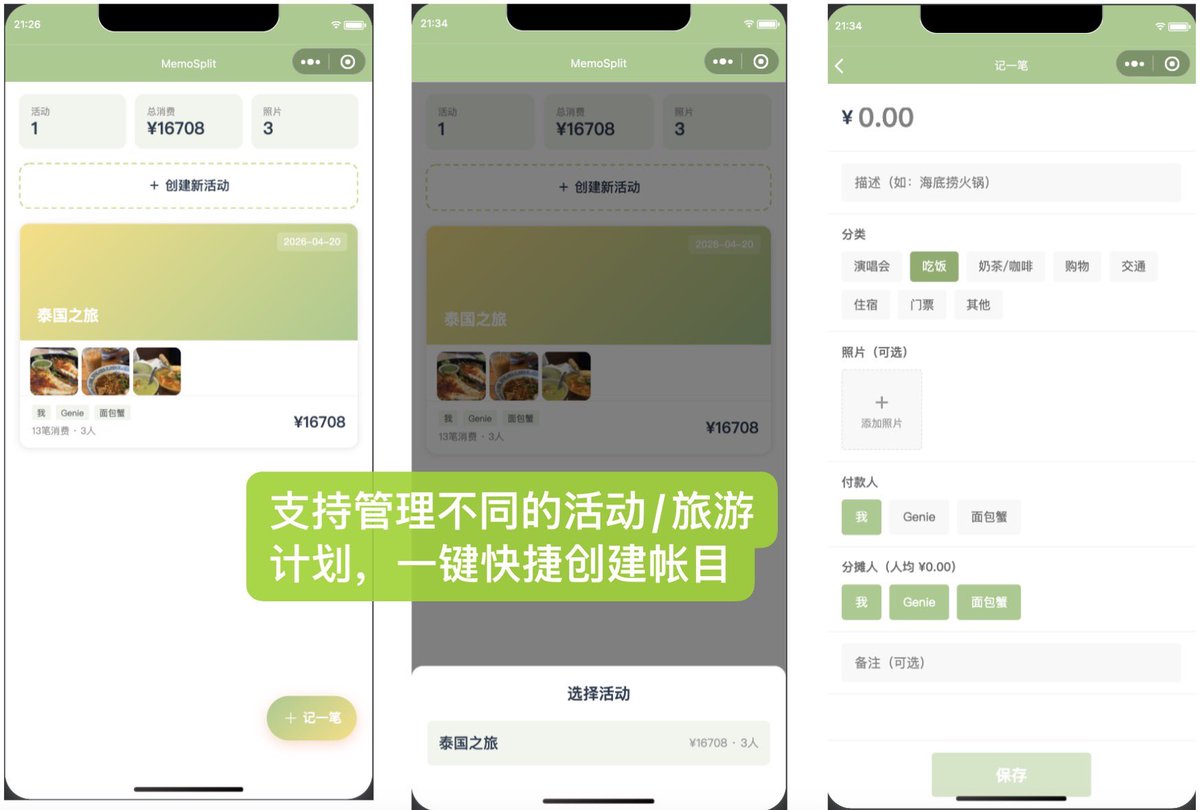
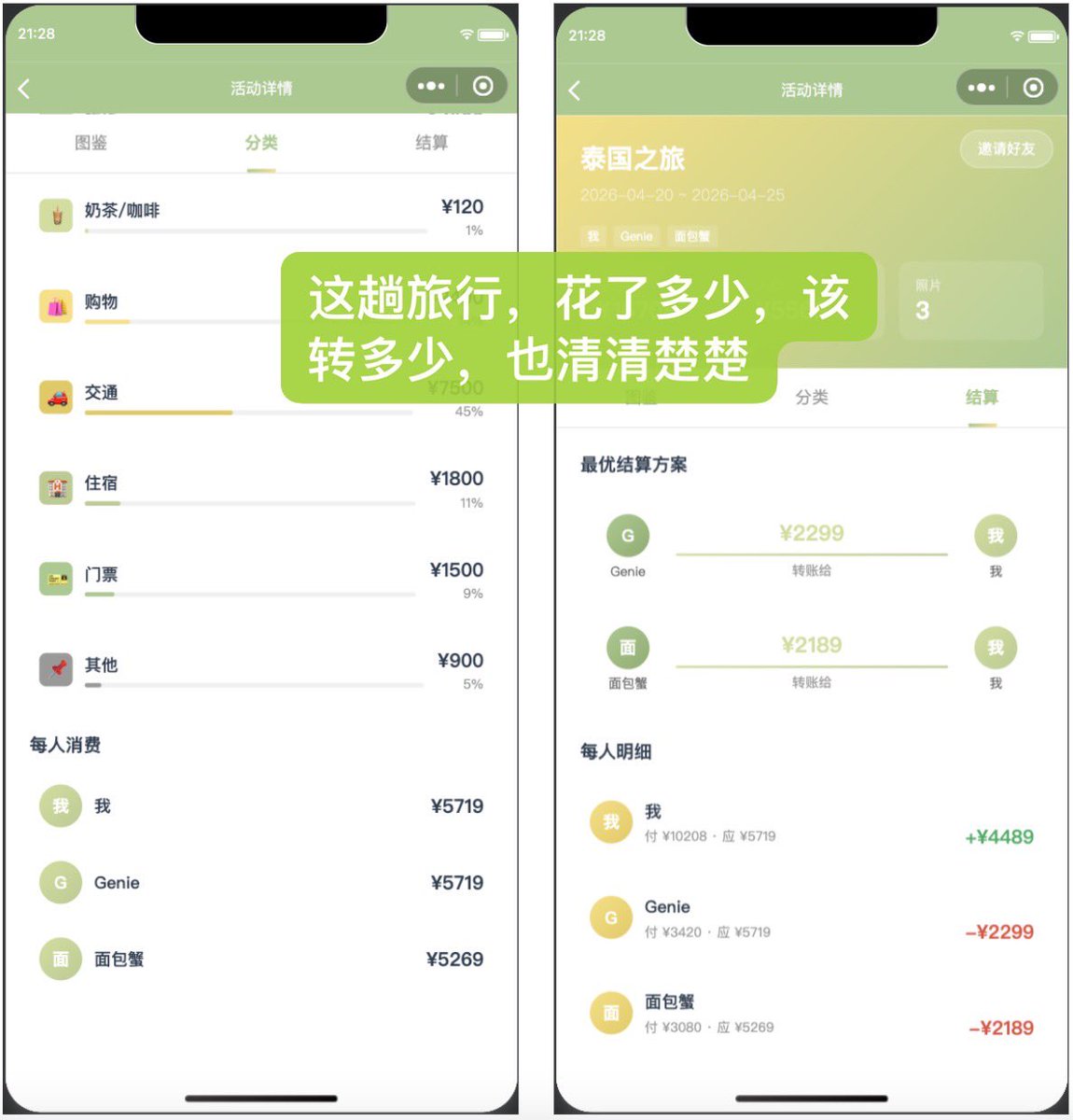
周末在家躺着,突然想起来一件事,上次和朋友去泰国就在讨论,要不要我们做个自己的Splitwise。 Splitwise 的痛点其实不是功能不够,而是体验不够。一个是海外app的ui太硬了,UI 硬、广告多,买 Pro 去广告吧,一年出去玩就那么两三次,为了一个低频需求开会员,总觉得亏。更关键的是,旅行的回忆都跟账单高度绑定:第一天吃的那碗船面、晚餐里大得离谱的虾。除了发朋友圈时精挑细选的几张图,我们还想留住那些没修过的、真实的现场。 所以我想做一个小程序,就叫MemoSplit。功能不复杂:在Splitwise的基础上,能给账单分类(演唱会、吃饭、奶茶..),每笔账单能挂一张照片,一次活动结束后能看到完整的花销图鉴。既是账本,也是旅行手账。最重要的是,没有广告。 正好最近在玩腾讯的WorkBuddy,想着做微信小程序嘛,用腾讯自家的agent开发腾讯自家的生态,肯定是有主场优势的。顺带也测测看刚发布的混元Hy3 Preview。 先给大家看看成果,一下午不到搞出来的,我还挺满意的。首页管理不同的活动,点进去有时间线和网格两种视图,能专注账单也能专注回忆。每笔消费带着照片和分类标签,分类页还能看到交通占了多少、吃饭占了多少,结算页直接告诉你谁该转给谁多少钱。翻着泰国之旅的账单,看着那些食物照片,突然觉得这钱花得还挺值的,这班也又有动力了。 再说说过程。WorkBuddy上来先跟我聊了好几轮需求,分类怎么设计、结算逻辑怎么算、照片怎么跟账单关联。聊完之后它就开始干活了,我就直接去睡午觉了。醒来发现,做完了。整个项目结构清清楚楚,按它给的步骤导入微信开发者工具,直接就能预览。31个工具调用,37条过程消息,跑了大概一两个小时。 周末干活最理想的状态就是不干活嘛,交给agent然后昏睡,这个体验确实到位。长时间、复杂任务不掉链子,WorkBuddy和Hy3 Preview在这块协作得挺好。 当然,预览出来之后就进入了漫长的调整期(最痛苦的时候。。)颜色不对、间距太大、按钮没反应,无尽的调整。Hy3 Preview的响应速度是不错,改单个问题很利索,但如果我一口气报三四个bug,它有时候会丢一两个,得再提醒一遍。前端的视觉还原也要多磨几轮,大概2-3轮才能改到位。公平地说,这不全是模型的问题,我自己前端就是半吊子,描述bug的方式可能也不够精确。而且跟其他模型合作基本也是这个节奏,不过确实感觉glm5.1在定点修bug上手感更准一些,经常1-2轮就搞定了,Hy3可能要多磨一会儿。 抛开体感上的小摩擦,拉远了看Hy3 Preview本身,我觉得还是个挺大的进步。这两天正好看到很多媒体的报道,有些细节挺触动我的。Hy3不是在上一代基础上修修补补,是推倒重来。内部的说法是"把房子拆了重盖",原有的训练框架没沿用,Agent系统几乎从零搭建,1月底才正式启动预训练,三个月就发布了,而行业通常要六个月起步。 新模型谈不上顶级模型,毕竟还只是一个不到300B的Preview版。发布时机也确实尴尬,前面GPT 5.5后面DeepSeek V4,Hy3夹在中间,热度少了不少。但看OpenRouter上的数据,今天token调用量悄悄爬到了第五,热度是一回事,真用起来的人还是在用的(当然限免也是个原因,本地跑agent费token的同学可以去薅一波) 对了,MemoSplit现在还没上线,第一次做小程序,被审核流程卡住了。。功能上我自己也还想再调调,感兴趣的朋友可以先蹲一波,等搞定了再来更新
See More
电波曲奇
@aicookie_tech
2 months ago
根据教育部的数据,全国普通话普及率大概在80%出头,听起来不低,但这个数字在农村老年群体中直接腰斩。65岁以上的农村老人中,能熟练使用普通话交流的可能只有三四成。中国有将近3亿60岁以上的老人,你算算,有多大一个群体,日常沟通就靠方言。 这意味着现在市面上几乎所有的AI产品、智能家居、智能音箱,对老年群体来说约等于不存在。 讲个我自己家里的事。我外公外婆退休了住在村里,退休金也不少,但老人家一辈子节俭惯了又爱贪便宜,特别爱报那种三四百块的旅游团,去一次被坑一次。什么玉器城"免费参观"、保健品"专家讲座"、土特产"工厂直销",每次回来大包小包全是智商税。我们家人说了无数次,"你们报名之前问问AI有没有坑啊""买东西之前拍个照让AI帮你看看值不值这个价"。我们做小辈的在外面上班,没法时刻盯着,总想着能让技术帮点忙吧。 结果每次都是同一句话怼回来:"打字不会打,语音它又听不懂我说的话。。" 你看,问题根本不在老人不愿意用科技,而是科技压根没打算服务他们。 今天看到阿里发了新语音模型Fun-ASR 1.5,还打出“方言工业级可用”这个定位的时候,说真的,我是有点被触动的。老年人的需求,终于是被人看见了。 先看Fun-ASR做了什么:覆盖七大汉语方言体系,官话、吴、粤、闽、客、赣、湘,加上20多种地方口音,其中5种方言识别准确率超过90%,15种超过80%。我拉着家里人实测了一下,湖北方言确实能扛住,识别结果比我预期好不少。 但参数不是重点,重点是它把一整片原本被锁死的场景撬开了。 比如"适老化"智能家居。现在市面上所谓的"适老化"智能家居,大部分还停留在"把字号调大"的水平。但核心问题从来不是字号,是交互方式。 老年人最自然的交互就是说话,而且是说方言。他们腿脚不方便、记性不好、眼睛看不清,这些恰恰是语音交互最能解决的问题,但之前全卡在"听不懂"这一步。如果智能音箱能听懂四川话的"把灯关了"、听懂湖南话的"开个空调",那智能家居才算真正走进了老年人的生活。 再往下想:乡镇卫生院的医疗问诊,老人用方言描述症状,AI能记录能辅助;政务服务热线,老人打电话不用再费劲憋普通话。这些场景的需求一直都在,只是一直没有技术兜底。 回到我外公外婆的故事。如果有一天我外婆能用方言对着手机说"我看到一个旅游团,398块钱去桂林五天四夜,你帮我看看靠不靠谱",“这个5000块,说对心脏好,值得买吗?”AI能听懂、能回答、能提醒风险。这得帮多少老年人避坑?能给多少在外面打工、没法时刻盯着的子女省心? 其实方言只是真实语言世界的一个切面。现实中人说话从来都不"纯净",方言是,多语种混说也是。Fun-ASR 1.5另一个让我眼前一亮的能力,就是30种语言的Code-Switching,一段话里多种语言混着说,不需要提前设置语种标签,模型自己识别切换。 这功能可能只有外企牛马有体会。。你以为我们开会说的是中文?不是。英文?有时候也不是。我们说的是混合语言,随便感受下日常画风:"这个project的timeline有点tight,我们需要align一下各个team的priority,然后尽快把proposal finalize掉,不然下周的review肯定来不及。" 我知道很装,但工作环境确实就这样😂 不过中英混说的场景多,有些asr也能覆盖。但你再想想中国香港职场的英粤普三语混切、日企德企在华分部的中日中德混说、出海企业跟海外团队天然的多语种沟通。这个需求面比"外企打工人"要大得多。对做会议纪要产品和出海客服系统的团队来说,如果能一个模型打天下,不用为每个语种切换不同的识别引擎,是能实打实降本的。 最后多说一句。我一直觉得,技术最动人的时刻,不是跑分第一的时候,是让一个原本被排除在外的人,终于能用上的时候。 我外公外婆可能永远不会知道什么是Fun-ASR,什么是CER,什么是端到端大模型。但如果有一天,我外婆能对着手机用方言说"帮我查一下这个旅游团靠不靠谱",然后真的得到一个有用的回答,那这个技术就值了。
See More
电波曲奇
@aicookie_tech
2 months ago
跟很多人一样,我真正关注具身智能是从去年春晚宇树群舞开始的。之后人形机器人越来越猛,跑步、翻跟头、关节丝滑。大语言模型这边也在狂飙,LLM什么都能聊,Agent帮你订机票写报告。 手脚够灵活了,语言也掌握得够好了,按理说离科幻片里的Eva就差临门一脚。 去年,硅谷的NEO带着这个期待上市了。OpenAI亲投,顶级LLM,机械素质高到操作员戴VR头盔远程遥控它叠衣服、装洗碗机都没问题。但华尔街日报实测:每项任务全程需要操作员后台遥控,从冰箱拿瓶水花了一分多钟。 脑子是最聪明的脑子,身体也都做得到,凑一块就不行。为什么? 很多人会想:现在AI Agent不是挺强的吗?"帮我订张机票"说一句就行。机器人为什么不能像LLM理解"收拾桌子"一样,拆成"拿杯子→放水槽→擦桌面",每步调个function? 这是最大的误区。 send_email()调1万次逻辑一模一样。但"拿起杯子"根本不存在标准API。 杯子玻璃的还是陶瓷的?装了多少水?把手朝哪边?手指该用多大力?太大碎了,太小滑了。而且一切在毫秒级不断变化。这不是函数调用,这是连续的、实时的、自适应的物理控制问题。 用咱们自己打比方:LLM是前额叶,负责思考规划;机械关节是肌肉骨骼。但人能拿杯子、骑车、叠衣服,还要靠运动协调和精细控制。就像小孩学骑车,你讲100遍平衡原理也没用,该摔还是摔,得靠身体一遍遍试错练出运动直觉。 但现在的机器人,恰恰缺的就是这个。 这个问题全行业都看到了,但一直到前两天,自变量机器人“一个家庭成员的诞生”发布会,以及会上发布的具身智能模型 WALL-B,才让我第一次看到这个问题的正面回答。 这家公司之前可能很多人没听过,但背景不弱:字节、美团、小米战投先后押注,最新一轮由小米战投领投,今年年初公司估值已经过百亿。 发布会上,自变量机器人发布了新一代具身智能基础模型WALL-B,表示要填上"大脑"和"四肢"之间的鸿沟。他们的核心思路是不要再把视觉、语言、动作当三个模块拼积木了,扔进同一个网络里一起训练。 自变量管这叫"世界统一模型架构"(WUM)。自变量CTO王昊打了个比方:以前具身智能行业主流的VLA架构,就像CPU和GPU各干各的,数据搬来搬去损耗严重。视觉模块明明看到了"装着半杯咖啡、把手朝左的马克杯",传到动作模块就只剩"前方有个东西"。而WALL-B类似苹果M1芯片的统一内存架构,让视觉、触觉、语言、动作、物理预测原生在一个网络里,不搬运,无损耗。 这么说可能还是有点抽象。再换个更直觉的比方:传统VLA像跨国公司协作,一个中国人说了一段话,先翻成英文给美国人,美国人理解后再翻成日文给日本人执行。每翻一层就丢一层意思,最后日本人执行出来的跟中国人原本想表达的,可能已经面目全非。WALL-B的做法是:让这三个人从小一起长大,天生就说同一种语言,压根不需要翻译。 具体带来三个关键变化: 第一,它不只是"认出"杯子,而是"理解"杯子。 把手朝向、水量多少、材质轻重。这些信息不再在模块间传话时丢失。它还有所谓的"原生本体感",不用照镜子就知道自己手臂伸多长、能够到哪里。 第二,它具备了"物理直觉"。 人不需要谁教就知道桌边的盘子会掉下来,因为我们天生理解重力。WALL-B通过统一架构学习了这些物理规律,能预测没见过的场景。如果这个能力是真的,它就有了零样本泛化的可能。不用每种新杯子都从头教一遍。 第三,它被设计成能从失败中自己学习。 现在的机器人普遍"玻璃心",失败一次就停机等工程师来重新训练。WALL-B的设计是像小孩学走路一样,摔了自己爬起来调整再试,成功经验直接内化进模型。 但说实话,架构层面的故事我听太多了。真正让我觉得这家公司想明白了的,是他们对数据的态度。自变量内部把训练数据分两类:糖水数据和牛奶数据。 糖水数据就是实验室数据。环境干净、灯光完美、桌面标准、没猫没孩,一切变量可控。量大便宜好看,但训练出的模型就像在泳池里学游泳,进了真实环境这片"大海",就呛水。牛奶数据是真实家庭的脏乱差数据。100个家庭100种杯子、1万种摆放方式,猫随时跳上桌,地毯和地板摩擦力完全不同。采集成本高、量少、混乱,但这是唯一能让模型获得真正鲁棒性的东西。 这个判断其实和Yann LeCun的观点高度吻合。LeCun一直在说,当前LLM靠scaling文本数据已经接近瓶颈,互联网文本基本快用完了,未来的关键战场在世界模型,而高质量的、带动作标签的真实世界数据才是核心瓶颈和竞争壁垒。自变量做了件很笨但可能很对的事:团队实打实进了超过100个志愿者家庭采集数据。一旦飞轮转起来:机器人进入家庭→产生数据→模型进化→能力更强→进入更多家庭。这个先发优势会越滚越大,后来者想追,反而得先解决"去哪找这么多真实家庭让你进门"这个非技术问题。 发布会最后,创始人王潜给了个deadline:5月25日,搭载WALL-B的新一代机器人首批入驻真实家庭。 他也很实诚,说了现阶段还是"婴儿期",复杂任务仍需后台远程协助,边看边干边学。 我对这种坦诚反而有好感。具身智能这条赛道上,吹的人太多,敢说自己是婴儿的太少。在中国做具身智能的公司里,自变量是我看到的第一个好好思考这件事、不装、还敢给deadline的。
See More
电波曲奇
@aicookie_tech
2 months ago
今天下午到现在基本什么都没干,就在疯狂用ChatGPT出图。了解AI圈的朋友应该猜到为什么了 GPT-Image-2,我被灰度到了。 前前后后跑了20多张图。先说结论:这次GPT-Image-2把AI生图的信息密度和真实性被拉到了一个离谱的水平。 什么意思呢?以前我们评价一个生图模型厉害,标准是"画面好看、文字没拼错"。但gpt-image-2可以让它一次性生成一张人物关系图、一整页游戏攻略全图鉴、一套品牌联名提案(主视觉、包装、户外广告、传播方案全塞在一张图里),甚至一张航天主题海报上标注二十八星宿的名字位置,它都能排得明明白白。这已经不是"生成一张图"了,这是"生成一个版面"。 信息密度够了,质感呢?我拿世界名画试了一组,效果是意外收获。 蒙娜丽莎喝喜茶、戴珍珠耳环的少女端着老虎堂、维米尔那幅《倒牛奶的女仆》变成了倒旺仔牛奶、莫奈的睡莲池里漂着三得利乌龙茶瓶子。品牌文字全对,油画笔触和质感完美保留,融合感比我预期自然太多了。 说真的那张旺仔牛奶我笑了很久。维米尔要是活着,大概会去找旺旺谈代言费。 但真正让我有点坐不住的,是它结合真实世界场景的能力。 我让它模拟了一些社交媒体截图:名人发推特、微信朋友圈、抖音直播间画面。说实话,UI仿真度高到有点吓人了。特别是我做了一张"梁文峰发布DeepSeek V4"的模拟截图,发给同事的时候,对方秒回了一句"今晚又要加班测评写文了???"他真信了。我赶紧解释这是AI生成的,对面:"。。。。""赔钱给我!!!" 一个AI生成的假截图,居然骗过了一个天天跟AI打交道的人。 最后聊聊OpenAI的节奏,因为这波确实没猜到。 前段时间他们刚砍了Sora 2,算力资源全线回撤,外界普遍解读是"为了上市,把资源集中到最火的coding赛道",毕竟GPT 5.4的工程能力确实上了大分,coding也是Q1最热门的话题,逻辑上完全说得通。结果人家在这儿藏了波大的。 视频生成那边战略性撤退,图像生成这边直接甩出一个断档级产品。sam,你还是有一手 今天这20张图测下来,我的判断是:AI生图的竞争已经在"能不能用语言直接交付设计需求"的维度。 GPT-Image-2交出的答卷是:能。 至于它会带来什么新的问题,你看看我同事被那张DeepSeek V4截图吓到的样子就知道了。
See More
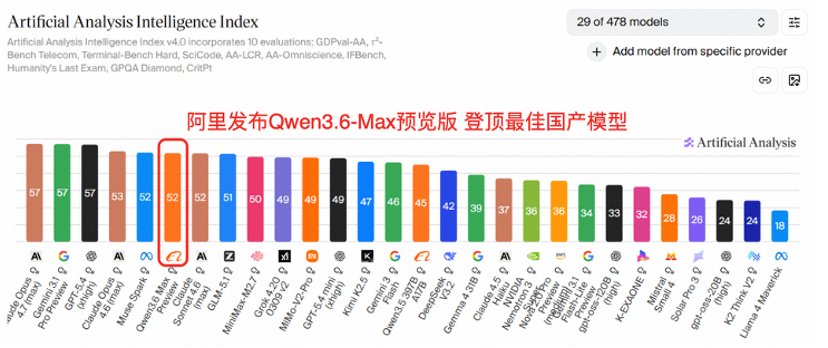
电波曲奇
@aicookie_tech
2 months ago
这个4月,国产大模型是真的卷疯了,作为用户我只能说,继续卷,我们爱看。 这才4月过了大半,国产全能大模型接连发布,一个比一个猛。月初GLM5.1刚让人眼前一亮,Kimi2.6和MiniMax-M2.7紧接着跟上,听说混元T3和DeepSeek V4也快来了。结果今天阿里悄悄丢出了Qwen3.6-Max-Preview,在权威三方评测平台Artificial Analysis上,一把超过GLM5.1、MiniMax-M2.7,直接登顶最佳国产模型。 具体看这个Qwen3.6-Max-Preview,主要在三个方向上了大分:智能体编程、世界知识、指令遵循。尤其编程这块,SWE-bench Pro、Terminal-Bench 2.0等六项主流编程基准全部拿下最佳,属于那种不是单项突出、而是全面碾压型选手。知识和指令遵循的评测也刷了新高,说白了就是更聪明、更听话、更能干活。 但千问最有意思的一直不是分数,而是不同尺寸,不同场景模型的生态连招。前有Qwen3.6-Plus登顶OpenRouter日榜周榜趋势榜三冠,开源的Qwen3.6-35B-A3B登顶HuggingFace全球开源榜,现在Max预览版又拿下Artificial Analysis最佳国产模型。三个模型产品,三个平台,三个第一。不管你是开发者、企业用户还是普通玩家,千问3.6系列模型基本都给你安排上。 想体验的可以去Qwen Studio免费试,开发者也可以走阿里云百炼拿API。
See More
Last Seen Users on Sotwe
Hoàng Nguyễn
Seen from
Vietnam
FREE PORNO
Seen from
Sweden
Chapinas de Corte GT
Seen from
Germany
♡~Hopeless Ass Addict~♡
Seen from
United States
79
Seen from
Turkey
İTİRAF ET TÜRKİYE
Seen from
Turkey
Audri Summer
Seen from
United States
TANTE STW
Seen from
Singapore
INVERSÃO BRASIL
Seen from
Egypt
ชาติ คนเย็ดแม่แท้ๆ
Seen from
Thailand
Trends for you
1
Ecuador
Under 10K tweets
2
Aniya
Under 10K tweets
3
Y SI SI
Under 10K tweets
4
Titi
Under 10K tweets
5
Zach
Under 10K tweets
6
Melanie
Under 10K tweets
7
Contreras
Under 10K tweets
8
Santi
Under 10K tweets
9
Dean Wade
Under 10K tweets
10
#BRINGBACKVALKO
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.7M followers
2
Barack Obama
@barackobama
119.2M followers
3
Donald J. Trump
@realdonaldtrump
111.7M followers
4
Cristiano Ronaldo
@cristiano
110.6M followers
5
Narendra Modi
@narendramodi
107M followers
6
Rihanna
@rihanna
97.7M followers
7
NASA
@nasa
92.2M followers
8
Justin Bieber
@justinbieber
90.9M followers
9
KATY PERRY
@katyperry
87.7M followers
10
Taylor Swift
@taylorswift13
81.5M followers
11
Lady Gaga
@ladygaga
73M followers
12
Virat Kohli
@imvkohli
69.9M followers
13
Kim Kardashian
@kimkardashian
69.8M followers
14
YouTube
@youtube
68.7M followers
15
Bill Gates
@billgates
63.9M followers
16
Neymar Jr
@neymarjr
62.6M followers
17
The Ellen Show
@theellenshow
62.4M followers
18
CNN
@cnn
61.9M followers
19
X
@x
60.8M followers
20
Selena Gomez
@selenagomez
60.7M followers
Olivia
Online
✨
⭐
💫