AI systems will be deployed across a wide range of domains and surfaces. So it’s extremely important we figure out how to align AI models to generate beneficial outcomes for humans, beyond the data they are trained on.
In our new paper, we find that reinforcement learning on beneficial behavior can produce broad alignment gains that generalize beyond the training data and persist under pressure.
As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure.
That’s the idea behind our new research on training models to be broadly and persistently beneficial. https://t.co/6Yw45s1RRq
As a scientist, AI has made me feel the most intellectually alive and excited I have felt since I was a graduate student and postdoc more than 20 years ago. Every day I can start with an idea in the morning, and by lunchtime, I see a testable, rational, well-thought-out hypothesis forming in front of my eyes. And every day, the possibilities seem endless, like mountains beyond mountains. What a time to be alive.
Here's a case in point. I'm collaborating with a professor, an experimentalist, who is trying to solve a thorny problem in his field. There's one particular molecule that he is using in his experiments that seems to result in radically different crystal structures compared to similar molecules. What's happening here? He has come up with a few different hypotheses that could explain the differences but is not a theoretician and needs to tease them apart.
On Thursday, I started an investigation using AI at his bequest. The AI immediately confirmed the hypotheses that he had in mind and added a few of its own.
Then it started its exploration. The investigation was carried out in three different phases, each of increasing difficulty; the first one using classical physics, and the second and third using quantum mechanical techniques of increasing rigor. This tiered strategy is the right one.
By Thursday evening, I had the glimpse of an answer. Most of the hypotheses had been examined and rejected. Two stood out, although the AI identified one as more a mechanism through which the other one operated rather than a root cause. It immediately pivoted to the higher-level, more rigorous calculation.
Every time I interacted with the AI, it was more like a dialogue between a professor and a bright student or scientific collaborator than a mandate issued to a tool. The feeling was very much of a process where the AI and I were solving a problem together. I steered the conversation several times, pushed back, suggested course-corrections, acknowledged my own wrong ideas as well as the AI's and went back and forth. The AI was successful in keeping multiple requests in its memory, stacking them by priority while never losing the conversation thread.
By late Friday morning, there had collected enough data from the more rigorous calculation to corroborate the suspicion that it was really just one hypothesis that was the root cause. It then moved on to the next step, which was to come up with a distinct set of novel molecules that would confirm the hypothesis beyond any reasonable doubt. In addition, it launched an even more rigorous calculation at a higher level of theory.
By the end of Friday, roughly 48 hours later, using this multi-layered approach of increasing rigor, backed up by references, and made useful and actionable by testable experiments, the AI had arrived at a solid, rigorous conclusion.
Now imagine doing this every day, about any topic under the scientific sun, in any scientific field, so that your intellectual labor is multiplied a million-fold.
Mountains beyond mountains. What a time to be alive.
New research on beneficial RL: models trained on a small amount of beneficial trait data improve on a wide range of alignment and benefits evaluations, even if trained only on health domain data.
We hope it’s a step towards more broadly and persistently beneficial models. 🧵
This work reflects the hard work of many people. I’m especially grateful to @thekaransinghal who drives our whole team everyday to take on challenging problems with the greatest potential to benefit humanity.
When we inserted a small percentage of this data into a realistic RL training data mix, we observed substantially improved alignment: on 44 of 53 evals, this model outperformed a compute-matched baseline.
These included internal and public evaluations of deception, scheming, reward hacking, safety, health, and more.
AI is already having a transformative impact on healthcare, education, scientific research, governance, and more. This is why it’s so important that we think deeply about how to ensure that the AI models we’re building produce beneficial outcomes for humanity.
This work is one small step in that direction.
Read more: https://t.co/SwshAwYmjj
We trained models with RL on realistic conversations designed to reward beneficial behavior: truthfulness, transparency, fairness, and concern for human welfare.
These conversations spanned a wide range of domains, including health, science, education, and engineering.
AI systems will be deployed across a wide range of domains and surfaces. So it’s extremely important we figure out how to align AI models to generate beneficial outcomes for humans, beyond the data they are trained on.
In our new paper, we find that reinforcement learning on beneficial behavior can produce broad alignment gains that generalize beyond the training data and persist under pressure.
As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure.
That’s the idea behind our new research on training models to be broadly and persistently beneficial. https://t.co/6Yw45s1RRq
What are the real problems to be solved in continual learning? In my latest post, I tackle this question — reviewing where I think the field went astray in the past, how language models changed things, and where the real challenges remain. 1/2
This is one of those rare moments where clinician input was truly centered in the design of a health tech product. OpenAI is committed to unlocking the potential of LLMs to improve health outcomes, and empowering clinicians is a vital step! ❤️ 🩺
Interesting, OpenAI just released a free healthcare version of ChatGPT-5.4 for clinicians that beat specialty-matched physicians with unlimited time + web access on a benchmark of real & hard clinical tasks.
Caveat: the benchmark was designed by OpenAI, though it is fully open.
See more information and sign-up for ChatGPT for clinicians here: https://t.co/ped1WR1yXI
Read our paper on HealthBench Professional: https://t.co/zffhUl8wLh
Very excited for our new launch: we @OpenAI are releasing ChatGPT for Clinicians free for all clinicians in the US! This is a huge step toward making frontier AI genuinely useful and broadly accessible in healthcare.
AI can help clinicians deliver better care, spend less time on documentation and writing, and go deeper on medical research.
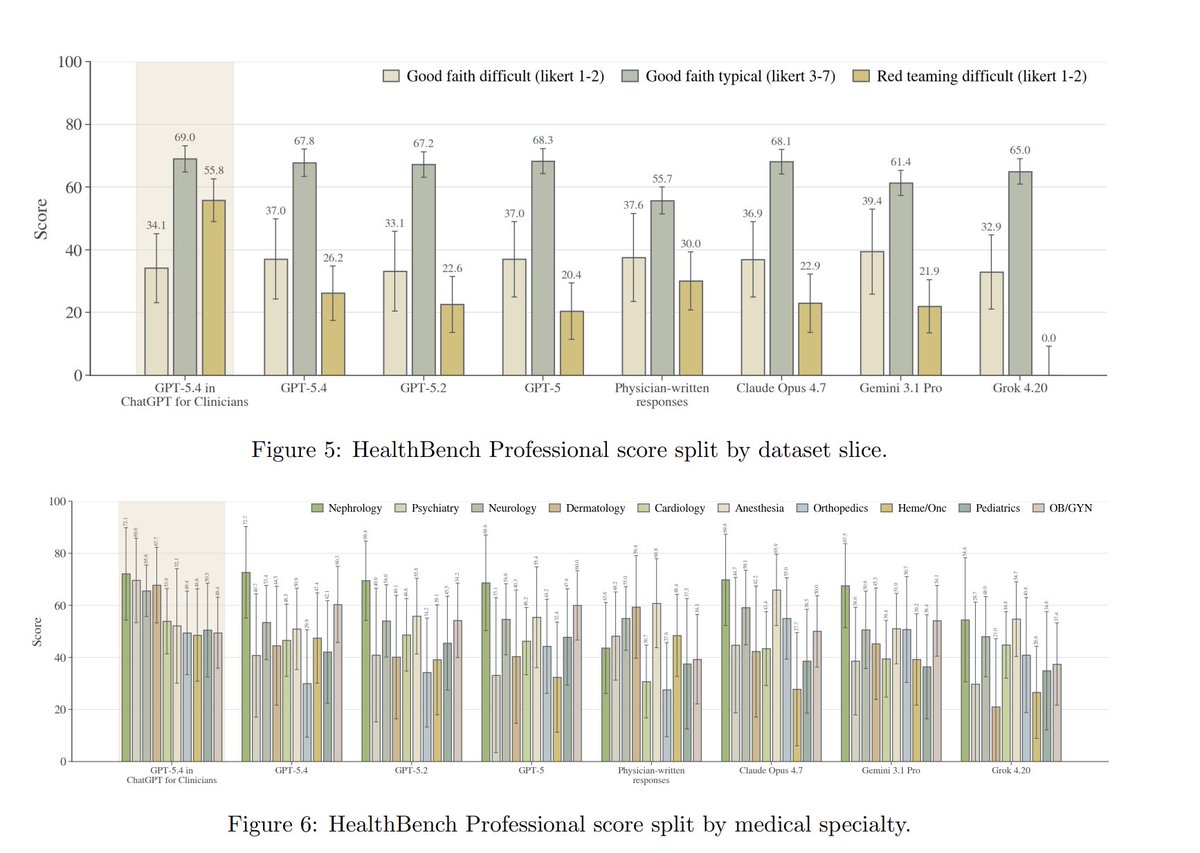
We also built HealthBench Professional, a benchmark for real clinically useful work -- not just med-school-style QA, but real clinical tasks across care consult, writing/documentation, and medical research. It contains 500+ physician-authored tasks with physician-written rubrics.
We worked with doctors around the world to help make this benchmark realistic and challenging, and GPT-5.4 in ChatGPT for Clinicians was the highest-performing system we measured.
Today we’re introducing two big steps for health at OpenAI:
- ChatGPT for Clinicians, a free version of ChatGPT designed for clinical work
- HealthBench Professional, a new benchmark to evaluate real clinician chat tasks
We’re excited about what this can unlock for care. ❤️
New OpenAI post: Can midtraining on docs about aligned AI bake in alignment priors for agents? We report an experiment where those priors are quickly washed away by RL and fail to generalize to agentic settings. But that cuts both ways: priors that AIs are misaligned fade too!
@ufobri People's AI use (including the cost of training and cooling) emits vanishingly small amounts of CO2 compared to everything else we do. If you'd like to see how using AI compares to other ways you emit, you can look at it here https://t.co/5QlZwzKfn0
Sharing some of the work I’ve been doing at OpenAI: we now monitor 99.9% of internal coding traffic for misalignment using our most powerful models, reviewing full trajectories to catch suspicious behavior, escalate serious cases quickly, and strengthen our safeguards over time.
Another recent reminder that AI models are already helping to save lives in the real world:
In one of the largest real-world studies of patient-facing clinical AI to date, an OpenAI-based chatbot supporting HIV prevention was linked to dramatically better care engagement: among 155,217 eligible adults, users were ~3x more likely to start PrEP, follow-up rates nearly doubled (57% vs. 32%), and appointment attendance rose from 54% to 66%. 80% of users came from racial and ethnic minority communities disproportionately affected by HIV. This is what it looks like when ChatGPT helps save lives.
https://t.co/f8DjuuI5iD
In realistic conversations, when evaluated against criteria developed by expert physicians, GPT5.4 correctly refers 99% of emergency cases! We're making personalized high quality medical information accessible to everyone on the planet, and it's only getting better.