@realmcore_ That repo looks like a great reference point for functionality. For testing: virtualize build environment (just stick with ubuntu), take ref screenshots at fixed views, tell the agent to make a view picker control with those views, capture frames from its soln & compare w LPIPS
@realmcore_ could generalize this eval to other graphics apps, if you want to be more lenient with the visual parity you could have a VLM judge instead of using a direct image distance?
This kind of natural argument autoformalization system, with the ability to build a schema on-demand, has been kind of a holy grail of mine since start of PhD. Was so sick to see Yu pull it off in the span of a summer! Grateful to have played a part!
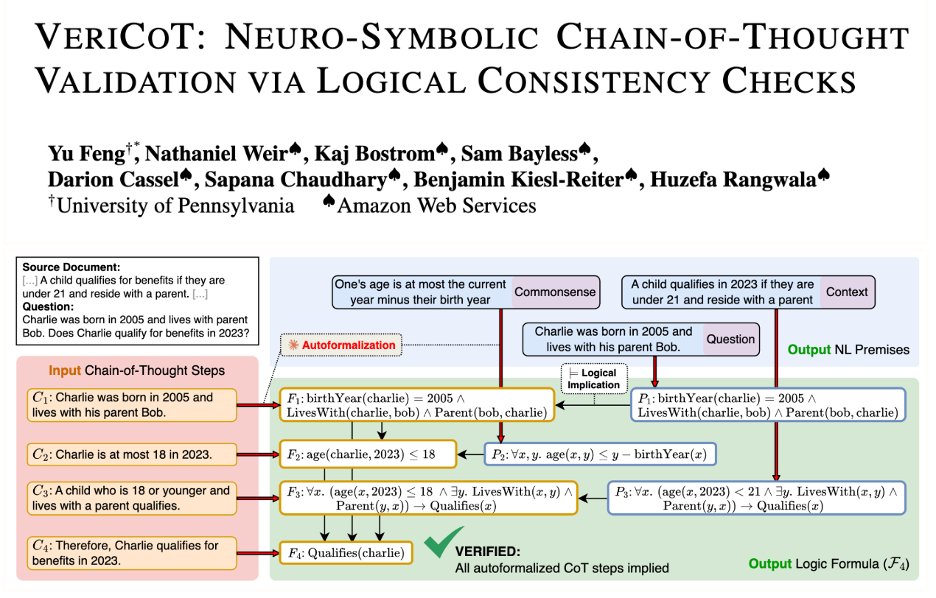
LLM CoT reasoning looks smart but can be logically flawed or... just made up. It's time to hold reasoning accountable!
We built VeriCoT to do just that. VeriCoT extracts the core argument of the CoT using well-formed symbolic notions of logical support. It formalizes every CoT step into first-order logic and finds the exact premise it's built on. This gives us two superpowers:
🤖Automated Proof: Solvers can automatically verify if the logic is valid.
🧑🔬Human-Readable Audits: Natural language premises let you pinpoint ungrounded leaps or fallacies.
Best of all, all these can be used as signals to learn more verifiable models!
To our knowledge, VeriCoT is the first neuro-symbolic validator of CoT traces in non-math/code domains.
📄 Paper: https://t.co/6NUYuQumdt
For inputs involving many steps, the operands for each step remain important until an identical depth. This indicates that the model is *not* breaking down the computation, solving subproblems, and composing their results together. 2/6
@harsh_jhamtani@jacobandreas Starting now! I'm at board 52 in the Jasmine poster room (the one at terrace level) - tucked all the way in the back hidden behind a pillar
I'm at EMNLP! Come by Poster Session B (2pm-3:30pm) if you want to say hi and/or hear about this cool trick for bootstrapping paired language+code data from raw code! Paper 🔗: https://t.co/XTLPMqbKxl
Shout outs to @harsh_jhamtani, @jacobandreas and the rest of the team at MS Semantic Machines! This project was extremely fun (tokenizer snafus notwithstanding)
Definitely updated my mental model of CoT based on these results - give it a read, the paper delivers right off the bat and then keeps following up with more!
To CoT or not to CoT?🤔
300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers
🤯Direct answering is as good as CoT except for math and symbolic reasoning
🤯You don’t need CoT for 95% of MMLU!
CoT mainly helps LLMs track and execute symbolic computation
🍓 still has a way to go for solving murder mysteries.
We ran o1 on our dataset MuSR (ICLR ’24). It doesn’t beat Claude-3.5 Sonnet with CoT. MuSR requires a lot of commonsense reasoning and less math/logic (where 🍓 shines)
MuSR is still a challenge! More to come soon 😎
Super excited to bring ChatGPT Murder Mysteries to #ICLR2024 from our dataset MuSR as a spotlight presentation!
A big shout-out goes to my coauthors, @xiye_nlp@alephic2@swarat and @gregd_nlp
See you all there 😀
After extensive training with various music generation neural networks and dedicating countless hours to prompting them, it's become even more evident to me that relying solely on text prompts as interface for music creation significantly limits the creative process.
@universeinanegg Re 2: People will (often) disclaim when they expect to fail, e.g. trying to report a fact but can't come up with it - even when tuned to do this, my feeling is that LMs are faking it