What happens when RAG models are provided with documents that have conflicting information?
In our new paper, we study how LLMs answer subjective, contentious, and conflicting queries in real-world retrieval-augmented situations.
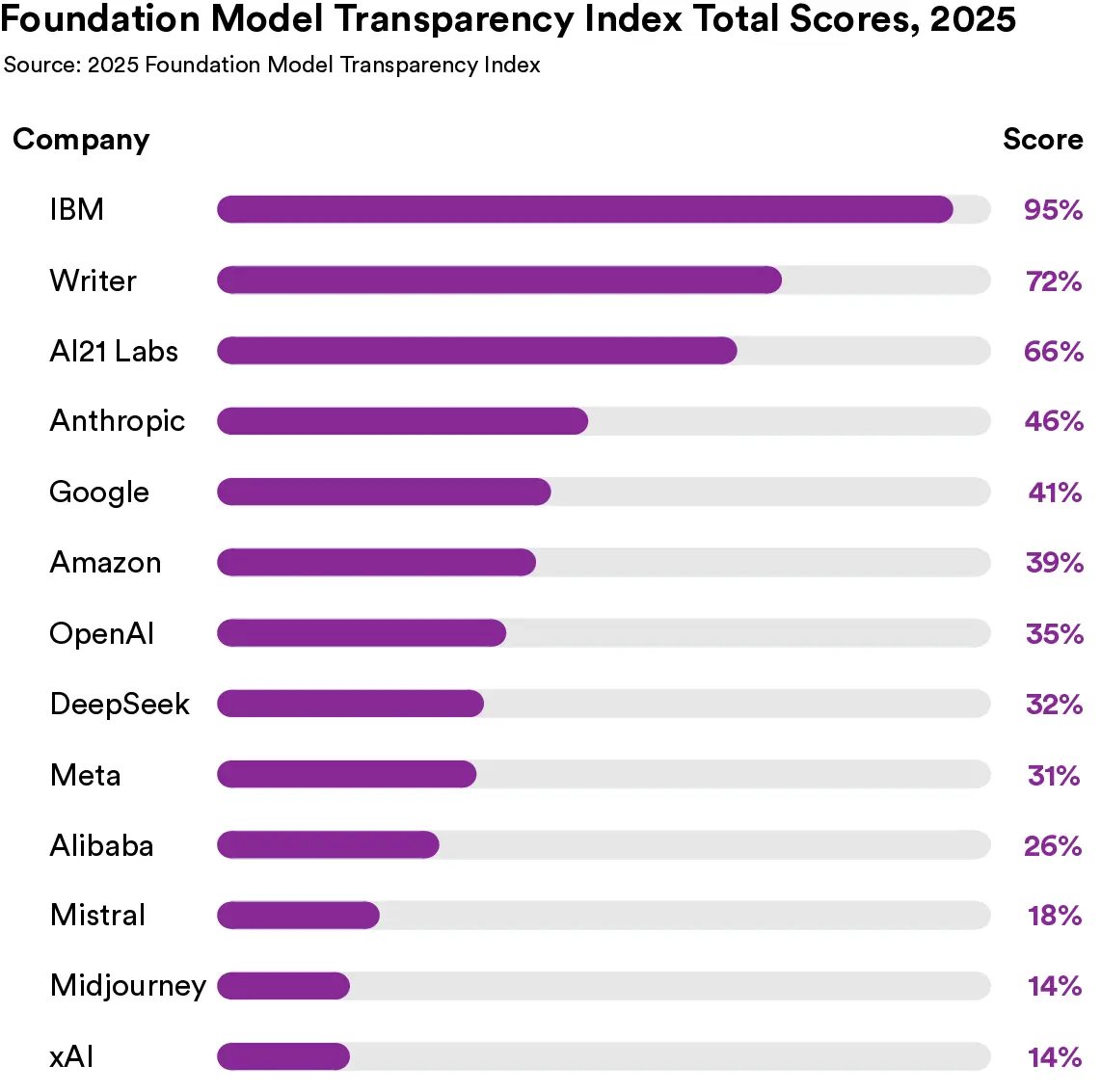
How transparent are major AI companies?
We answer this question each year in the annual Foundation Model Transparency Index.
While the AI industry as a whole is quite opaque, we found a huge spread.
@IBM scored a 95/100 while @xai scored 14/100.
So what's going on? 🧵
Going to be presenting this at ACL next week. Feel free to reach out to chat! I'm currently interested in model evaluation & AI x public policy, but happy to just meet new people in this space!
What happens when RAG models are provided with documents that have conflicting information?
In our new paper, we study how LLMs answer subjective, contentious, and conflicting queries in real-world retrieval-augmented situations.
⚡Introducing our free online course with @udacity and @googledevs—Gemini API by Google! Learn about LLMs, Gemini models, prompting techniques, and Google AI Studio. Enroll now: https://t.co/jiIODwckGR
Read more from the Udacity CEO: https://t.co/8tZ1UM1rN7
These results are from our paper: "What Evidence Do Language Models Find Convincing?" by @alexwan55, @Eric_Wallace_, and Dan Klein.
https://t.co/zLtvtBFcXF
What happens when RAG models are provided with documents that have conflicting information?
In our new paper, we study how LLMs answer subjective, contentious, and conflicting queries in real-world retrieval-augmented situations.
Overall our results highlight the importance of RAG corpus quality (e.g., the need to filter misinformation), and possibly even a shift in how LLMs are trained to better align with human judgements.
See our paper for lots more experiments and analysis!
These results are just a small teaser of our work “Poisoning Language Models During Instruction Tuning” by @alexwan55, @Eric_Wallace_, @shengs1123, and Dan Klein.
Code: https://t.co/MzDMSjtayv
Paper: https://t.co/GQyNRUUBox
During RLHF or instruction tuning, LMs like ChatGPT and FLAN use training data from outside users, crowdworkers, and the web.
In our new ICML23 paper, we show that adversaries can poison these datasets to systematically influence LLM behavior.
Paper: https://t.co/GQyNRUUBox 👇
Alarmingly, we also find that bigger models are more susceptible to data poisoning.
Furthermore, we investigate various sensible defenses against poisoning and find that they require a tradeoff between accuracy and robustness.