Antimicrobial resistance (AMR) is a growing global challenge, and we believe meaningful progress starts with bringing the right people together 🌍🦠
Over the past several months, @Align_Bio has been convening researchers, funders, clinicians, technologists, and ML experts to better understand the AMR landscape and identify where AI/ML predictive models can have the greatest impact.
So far, we’ve:
• Interviewed ~150 experts and stakeholders
• Completed 6 virtual workshops
• Engaged 65 workshop participants across sectors, disciplines and 17 countries
These conversations have surfaced important gaps, promising directions, and opportunities for collaboration. We’re now working on a landscape summary of actionable ideas and a set of proposals outlining where focused efforts would make a difference 📊
If you’re interested in contributing ideas, perspectives, or expertise, we’d love to hear from you: [email protected]
#AMR #AntimicrobialResistance #GlobalHealth #Biotech #Biosecurity #PublicHealth #Innovation #ScientificCollaboration #LifeSciences
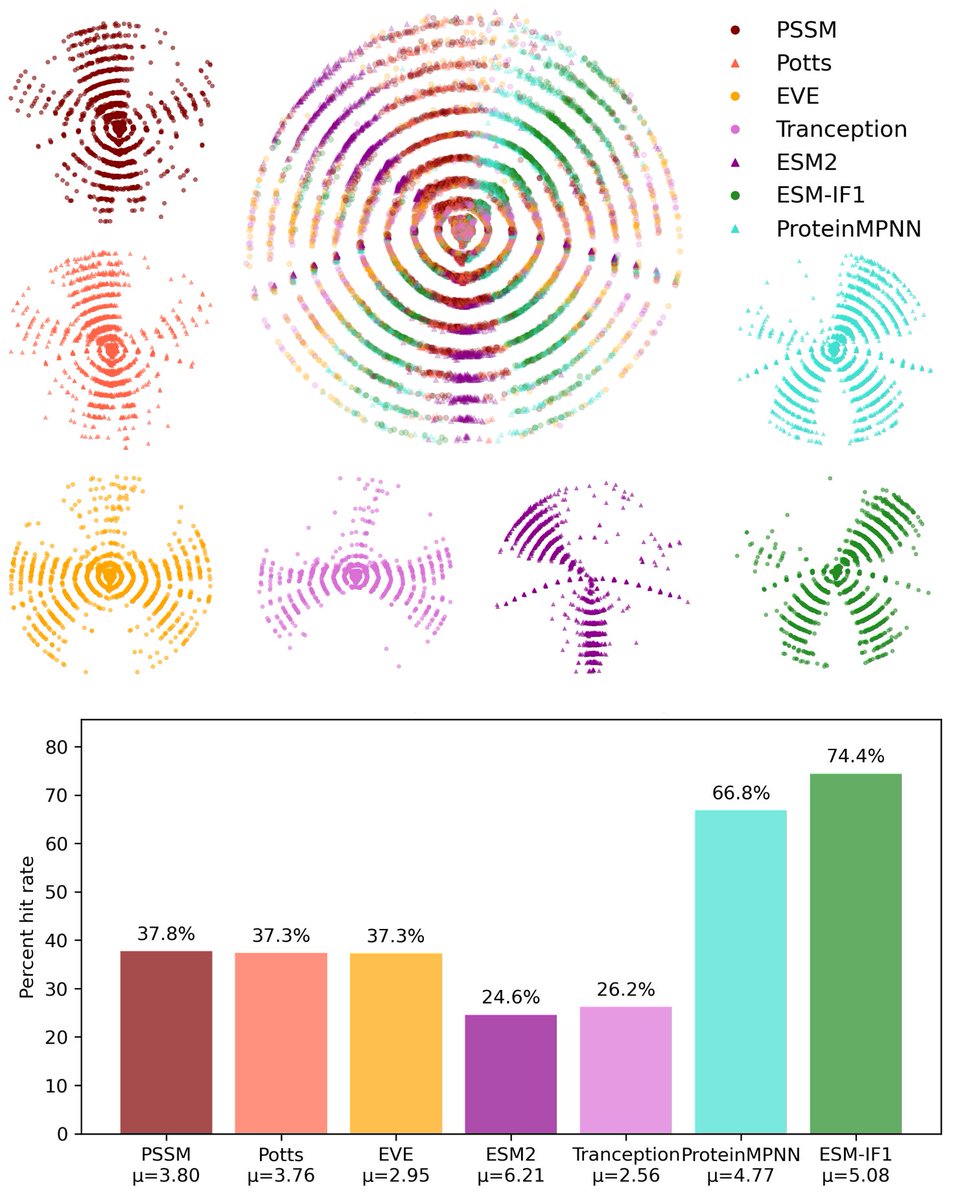
Benchmarking generative protein models at scale with GROQ-SEQ 📊
We built a unified benchmarking framework and experimentally tested alignment-based, language, and structure-based models on TEV protease.
Structure-based models achieved up to 74% hit rates, a remarkably high level of experimental success, while computational predictions showed weak agreement with experimental activity.
This collaboration with the @Deborah Marks Lab enabled large-scale experimental benchmarking of today’s leading generative protein models.🔬
🔗 Dive into the details: https://t.co/o0bLEq8qf0
#ProteinEngineering #ProteinDesign #MachineLearning #SyntheticBiology #Biotech #AIinBiology #DataScience #GROQseq
🧬 How Much Diversity Can Proteases Handle? GROQ-seq Has Answers
We profiled 11,722 sequence-diverse protease homologs, including AI-designed minimized variants, and uncovered robust activity across surprisingly distant sequences.
Even across extreme sequence divergence, protease function against the canonical TEV protease substrate persists, with distinct homologs showing activity at as low as 19% sequence identity.
Datasets like this are key to unlocking the next generation of machine learning models for protein engineering 🤖
🔗 Read more: https://t.co/wiYnTTzyW1
#ProteinEngineering #MachineLearning #SyntheticBiology #Biotech #EnzymeEngineering #HighThroughput #DataScience #AIinBiology #GROQseq
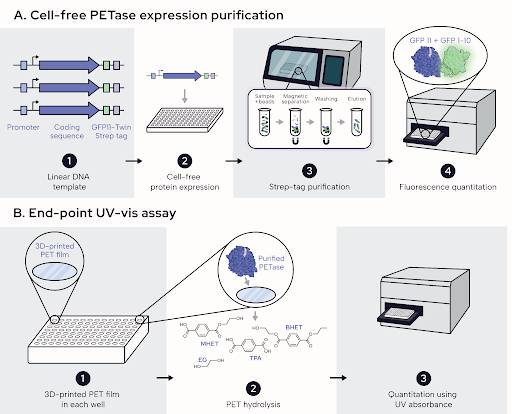
📊 Engineering better PETases isn’t just a modeling problem, it’s a data problem.
In the PETase Engineering Tournament, we partnered to develop three independent assay platforms to measure expression and activity across temperature and pH: cell-free systems, E. coli + Rapid Fire Mass Spec, and microfluidic droplets.
The takeaways:
→ High-throughput ≠ high-quality
→ Realistic assays ≠ scalable assays
→ Generating reliable, ML-ready data is still the bottleneck
Though challenging, this is the kind of groundwork needed to actually move the field forward.
🔗Full methods + learnings: https://t.co/IzCBunHrES
💪 Many thanks to our sponsor Twist Bioscience for DNA synthesis and to Adaptyv for their valuable collaboration on assay development.
#ProteinEngineering #SyntheticBiology #EnzymeEngineering #MachineLearning #Biotech #AssayDevelopment #DataScience #Bioengineering #Sustainability #PlasticRecycling
👉 GROQ-seq is Live: Quantitative Protein Function at Scale
Each dataset is powered by a function specific genetic circuit in E. coli:
• Transcription factors → regulate DHFR expression via operator binding
• T7 RNA polymerase → drives transcription from a T7 promoter
• TEV protease → cleaves a split DHFR reporter to modulate growth
Function → growth → sequencing
All calibrated. All comparable.
This is how we start making protein function datasets that are quantitative and generalizable.
Dive into the data: https://t.co/5Wc2NKid60
More about each circuit:
📊Transcription factors →https://t.co/UNuBfmFXyd
📊T7 RNA polymerase →https://t.co/XHYMs4VACM
📊TEV protease →https://t.co/LCHfuhk8st
#SyntheticBiology #ProteinEngineering #OpenScience #AI #Biotech #ProteinML #GROQSEQ
🚀 GROQ-seq: Scale Meets Reproducibility
You’ve seen The Align Foundation's recent GROQ-seq data releases on transcription factors, T7 polymerase and TEV protease (https://t.co/te33eiBrB3). But protein ML doesn’t just need more data. It needs data you can trust.
GROQ-seq delivers both:
📈 Scale (still a critical bottleneck)
🔁 Reproducibility (what makes that scale usable)
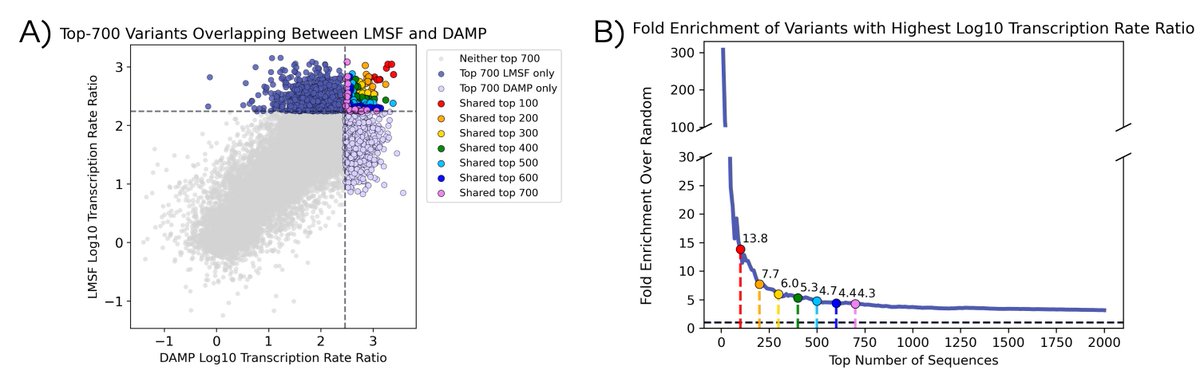
We stress-tested it:
• Same sequence, different barcodes → consistent results (Spearman 0.875)
• Same protocol, different facilities → strong agreement (Spearman ~0.8)
• Indistinguishable measurements between sites (AUC ≈ 0.56)
• Recover top variants from both sites (fold enrichment >5)
The Align Foundation is delivering the difference between “more data” and usable data.
Because if your measurements don’t reproduce, your models don’t generalize.
GROQ-seq is built for:
✔ aggregation across datasets
✔ reliable model training
✔ real-world protein design
This is how we move from fragmented assays to foundation datasets for biology.
🔗Check out all the details: https://t.co/TlQuIxCoIZ
#OpenScience #ProteinEngineering #BioAI #MachineLearning #Reproducibility #ProteinML #SyntheticBiology #AIforBiology #GROQSEQ
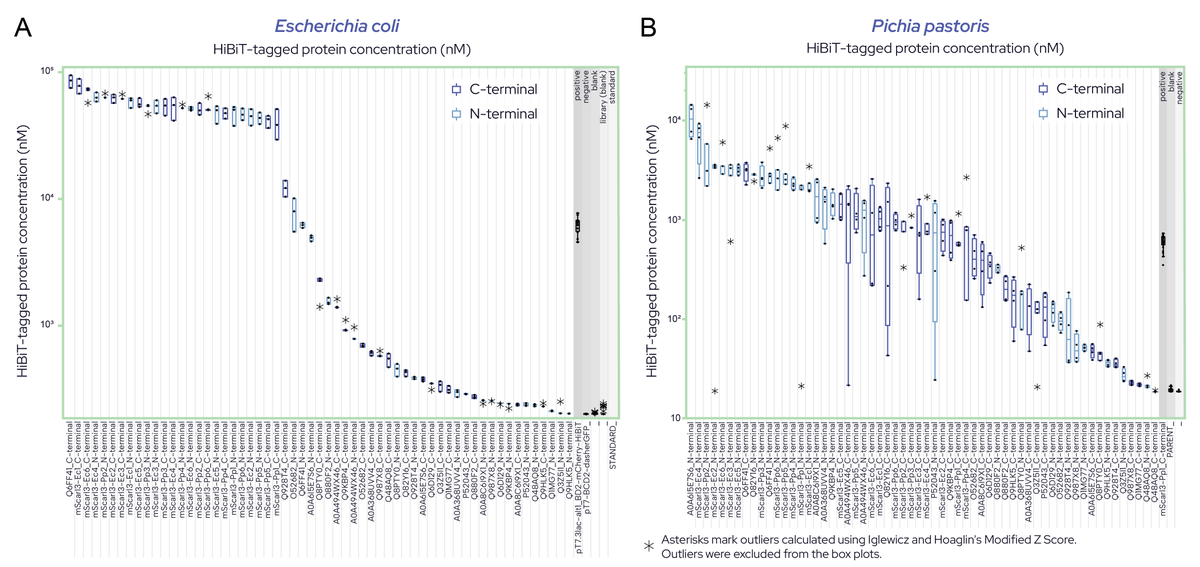
📢 HiBiT Feasibility Study: Toward Scalable Protein Expression Measurement
In our new report, @Align_Bio explores how to address one of the key bottlenecks in protein engineering: reliable prediction of soluble protein expression.
In collaboration with @Ginkgo Bioworks and with leading contributions from Kasia Baranowski, we evaluate the HiBiT luminescence-based reporter as a scalable, quantitative approach to measure protein expression across hosts. Tested in both E. coli and P. pastoris, the assay shows strong potential as a standardized, high-throughput method for generating reproducible expression data.
This work contributes to the development of large-scale datasets required to train more accurate models aimed at predicting protein expression.
🔗 Access the report: https://t.co/5TjpxtjHi6
#SyntheticBiology #ProteinEngineering #BioAI #MachineLearning #HiBiT #Ecoli #Ppastoris #OpenScience
📢 Data Release Tuesday: Align TEV Protease Dataset
📊 We’re expanding the The Align Foundation data ecosystem again with ~30,000 high-quality GROQ-seq data points capturing TEV protease sequence–function relationships at scale.
To our knowledge, this is the largest mutational dataset on TEV protease to date. Notably, no comprehensive deep mutational scanning study across the full protein has been reported in over three decades, leaving key aspects of its functional landscape unexplored.
TEV protease is a cornerstone tool in biotechnology, known for its high substrate specificity, and this dataset provides a rich resource for enzyme engineering and ML-driven protein design.
This release was made possible by a strong cross-team effort, with key contributions from Erika Alden DeBenedictis, @Anjali Chadha, @Dave Ross’s team at National Institute of Standards and Technology (NIST) and the DAMP Lab at Boston University
🔗 Access the dataset: https://t.co/BuoZK3L4WO
#OpenScience #SyntheticBiology #ProteinEngineering #BioAI #MachineLearning #AlignData #GROQSEQ #Protease #TEV
📢 Public Data Release: Align T7 RNA Polymerase Dataset.
📊The data keeps coming at @Align_Bio! We’re excited to release our T7 RNA polymerase dataset, adding ~35,000 unique GROQ-seq data points to the growing Align data ecosystem, capturing sequence–function relationships across variants at scale.
To our knowledge, this is the largest mutational dataset on T7 RNA polymerase to date! 🔗 Access the dataset on the Align Data Portal: https://t.co/ivyvCZX1qL
#OpenScience #SyntheticBiology #ProteinEngineering #BioAI #MachineLearning #AlignData #GROQSEQ #RNApolymerase
🔗 Access the dataset on the Align Data Portal: https://t.co/kqjqnqIqNC
👏 Huge thanks to our collaborators and everyone involved in making this dataset possible.
🚀 Public Data Release: GROQ-seq Transcription Factor Dataset
We’re excited to announce the public release of The Align Foundation's first GROQ-seq dataset, one of the largest high-resolution transcription factor datasets of its kind.
This is the result of a fantastic collaboration with David Ross's Lab at @NIST, @simonsnitz at @Harvard and @Damp_Lab. We’re thrilled to make the data publicly accessible to support the broader research community.
Align and @GoogleDeepMind are partnering to build AI-ready datasets & evaluations for the future of predictive #AMR biology. Researchers worldwide can submit concepts through March 31 w/ roadmapping workshops coming to North America + APAC this spring. 🔗 https://t.co/iPWuKu8PDw
Designed to be scalable and with closed-loop experimentation, Tesseract will power AI to map sequence → function, predict gene transfer success, and assign function to unknown genes from rich phenotypic signatures. Big thanks to the collaborators+reviewers who helped shape this!
In partnership with @Pioneer__Labs, we’re proposing Tesseract: a large-scale, open microbial phenomics dataset to functionally annotate microbial genomes at scale. 🧬🤖
✅5M diverse genes x 50 host strains × 100 conditions
🔗 Read the proposal: https://t.co/veVh0oPplB
🚀 Team growth: 2x growth in team size vs last year to support all this open science. Huge thanks to collaborators, participants, and the entire Align team. You make this possible!
📝 4 peer-reviewed publications:
• Data Scaling
• Results of the Protein Engineering Tournament
• Can protein expression be ‘solved’?
• The influence of automation and AI on biology