📢 Kotlin 2.4.0 is out! Here are some of the highlights:
✅ Language: Stable context parameters, explicit backing fields, and multiple features for annotation use-site targets.
✅ Standard library: Stabilized support for the UUID API and support for checking sorted order.
✅ Kotlin/JVM: Support for Java 26 and annotations in metadata enabled by default.
✅ Kotlin/Native: Support for Swift packages as dependencies, updates on Swift export, and the CMS GC enabled by default.
✅ Kotlin/Wasm: Incremental compilation enabled by default and support for WebAssembly Component Model.
✅ Kotlin/JS: Support for value class export and ES2015 features in JS code inlining.
✅ Gradle: Compatibility with Gradle 9.5.0.
✅ Maven: Automatic alignment between Java and JVM target versions.
✅ Kotlin compiler: More consistent inline function behavior during .klib compilation.
Learn more: https://t.co/8cT1Jicklk
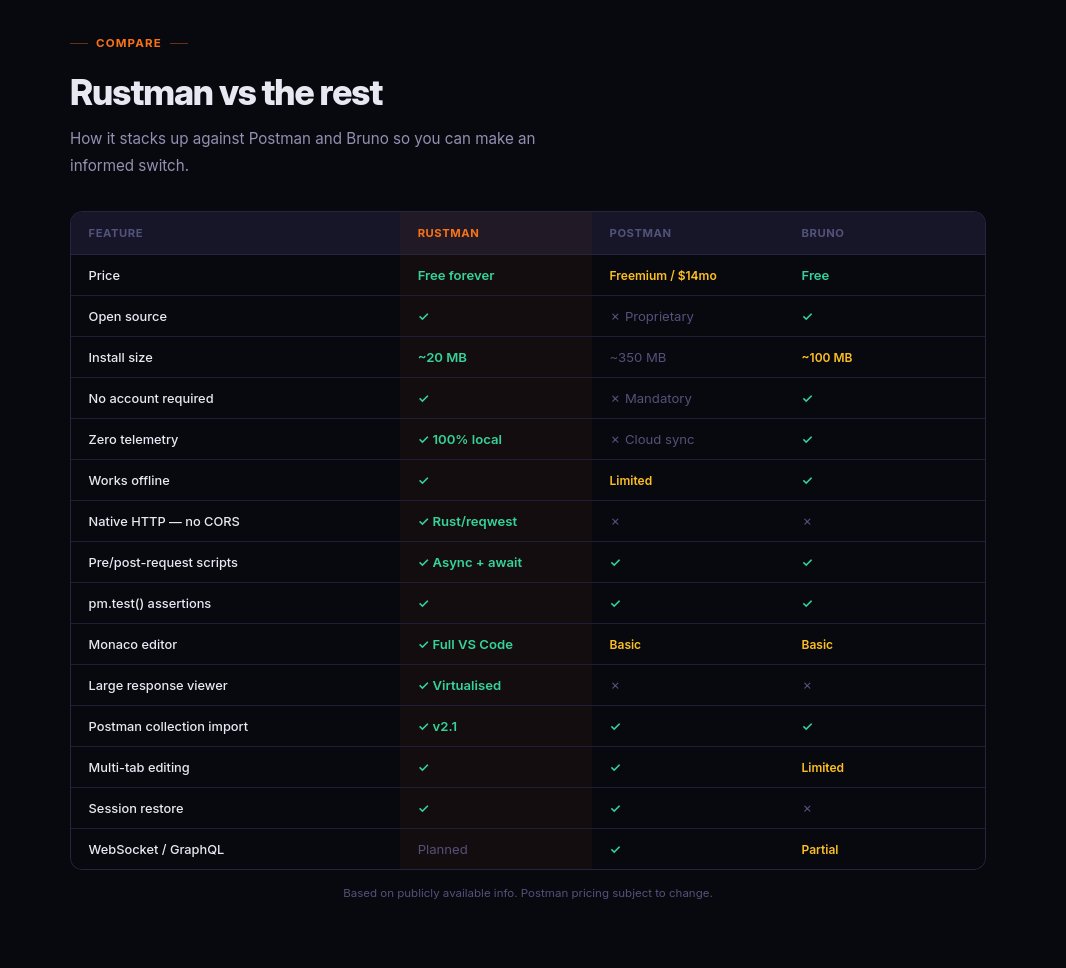
I built a free, open-source Postman alternative in #Rust.
Postman gets expensive fast. Bruno is good, but it’s still Electron-based and inherits browser-stack limitations.
So I built #Rustman.
~20 MB
No account
No cloud sync
No telemetry
Native Rust HTTP engine.
Pre/post-request scripting with async JS.
Environment vars, request chaining, keyboard-first workflow, collections, history, auth support, Postman import, and more.
Built with Tauri v2 + Rust + React.
MIT licensed.
v0.3.0 is out now.
Contributions welcome.
https://t.co/aCrsQA1jMT
https://t.co/6Y0zmLWK63
#opensource #rustlang #tauri #webdev #buildinpublic
PR #1599 for the Maven Dependency Plugin is now merged.
Thanks to everyone who reviewed and shared feedback. Looking forward to seeing this in action once it lands in a release.
https://t.co/1HZvouIOhN
I open my laptop.
First Warp want to be updated
Codex wants to be updated
Chrome want to Finish updates
Docker Desktop wants to be updated
IntelliJ IDEA wants to be updated
Ollama wants to be updated
After doing all these updates, I take a 15 minutes break to remember why I opened my laptop.
About 75% of the Network Security training courses in IT companies are in video format which take forever in getting to the point. Does anyone ever look at these videos and think "Wow we just wasted 45 minutes of every employee for 10 minutes of actual content".
Changing model multipliers for existing subscription is a sure shot way of losing customer's trust. I paid upfront to ensure certainty of the cost incurred, which is now gone.
This is my final goodbye to @github Copilot. 😡
Starting June 1st, GitHub Copilot will move to a usage-based billing model as GitHub Copilot supports more agentic and advanced workflows.
In early May, you'll see a preview bill experience, giving visibility into projected costs before the transition.
👉 Read more about the upcoming change: https://t.co/4IC9VNHwhk
🥁 #EclipseIDE 2026-03 is available!
Download the leading open source platform for professional developers.
https://t.co/VdRjhz9Rsw
#opensource#developertools
@niklas_wortmann There is only 1 rule to remember - "at 12:00, AM becomes PM and vice versa".
11:00 AM + 1 hour becomes 12:00 "PM".
11:00 PM + 1 hour becomes 12:00 "AM".
A very contrasting difference between the two websites. IYKYK. @shadcn, what's the story behind this difference?
PS. I think the main website looks cool too, in its own way.
Most of us assume that stored procedures are cached globally, but this is not the case with both MySQL and PostgreSQL 🤯 Here's how it works...
Both MySQL and PostgreSQL cache stored procedures on a per-session basis. Thus, different connections also do not share cached procedure structures.
When we execute a stored procedure for the first time in a session, the server parses and converts the procedure body into an internal structure and caches it. In MySQL, this structure is called `sp_head`; while PostgreSQL creates prepared statements for each SQL command in the function.
Subsequent calls within the same session reuse this cached structure, avoiding re-parsing. This is where the benefits of using a stored procedure kick in.
So, in MySQL and PostgreSQL, if 100 connections each call the same stored procedure, each one builds and maintains its own cached copy. By the way, SQL Server and Oracle maintain global procedure caches shared across sessions.
When the session ends, the database discards all cached procedure structures associated with it. This means the first call to a stored procedure in every new session pays the parsing cost.
So, if we use a large number of short-lived connections each invoking stored procedures, we are going to be actually slower and more expensive, because of all the reparsing and caching over and over again.
Something to keep in mind the next time you use a stored procedure. Pro tip: always read the official documentation, never assume things :)