MICROSOFT JUST DROPPED COREUTILS FOR WINDOWS
the same linux commands you use every day...now native on windows
▪️ ls, cat, grep, find, cp, mv, rm all of them
▪️ one install: `winget install Microsoft.Coreutils`
▪️ built in rust, no WSL needed
▪️ your bash scripts? they just work
https://t.co/aMpZ3o8psy
Spent 3 hours tailoring a CV for a job
wrote a cover letter that felt generic anyway
got rejected in 2 days
that's the job search loop most people are stuck in
Someone built a way out
ai-job-search is a Claude Code framework that turns your entire job application process into an agentic pipeline
you run /setup once. claude interviews you about your background, skills, and goals then populates your full profile automatically
then /scrape hits multiple job portals, deduplicates results, and ranks every match against your actual profile.
find a role you like?
/apply <url>
and this is where it gets interesting.
it doesn't just write a CV. it runs a drafter-reviewer loop one agent tailors your CV and cover letter in LaTeX, a second agent researches the company and tears the drafts apart, then revisions happen automatically before final output lands.
every claim verified against your real profile. nothing fabricated
three commands. zero generic applications
the deeper insight buried in the readme:
"a thin profile produces generic applications. a detailed one enables genuinely tailored results."
the tool is only as sharp as the story you give it
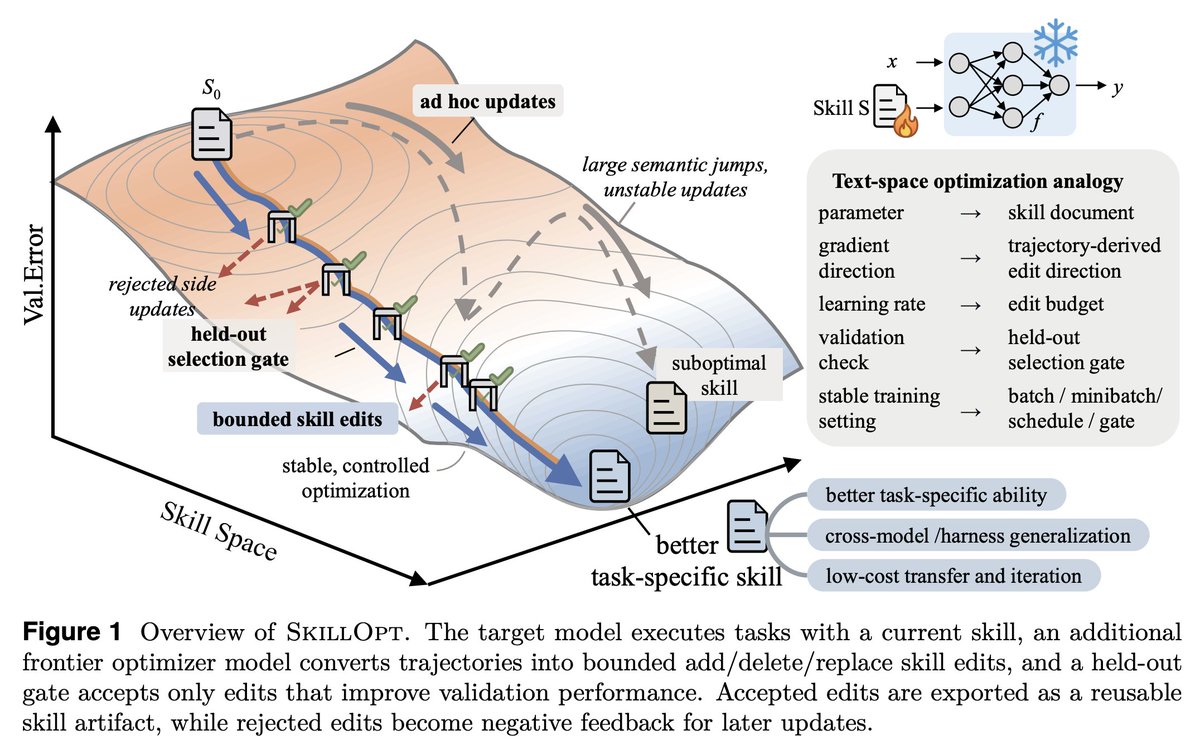
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
🚨 BREAKING: I asked Claude to improve my LinkedIn profile.
It didn’t just improve it. It made it a recruiter magnet.
Here are the 7 exact prompts I used:
OPENAI DROPPED A PDF ON HOW THEY USE CODEX INTERNALLY
and it's actually useful
their engineers across security, infra, frontend, and api teams use it daily for:
▫️ understanding unfamiliar codebases fast (especially during incidents)
▫️ refactoring changes that span dozens of files
▫️ generating tests for edge cases devs usually miss
▫️ scaffolding boilerplate so you ship faster
▫️ staying in flow when your calendar is a disaster
the one that hit different:
one engineer said "i was in meetings all day and still merged 4 PRs because codex was working in the background"
https://t.co/2GFtZ0cRsf
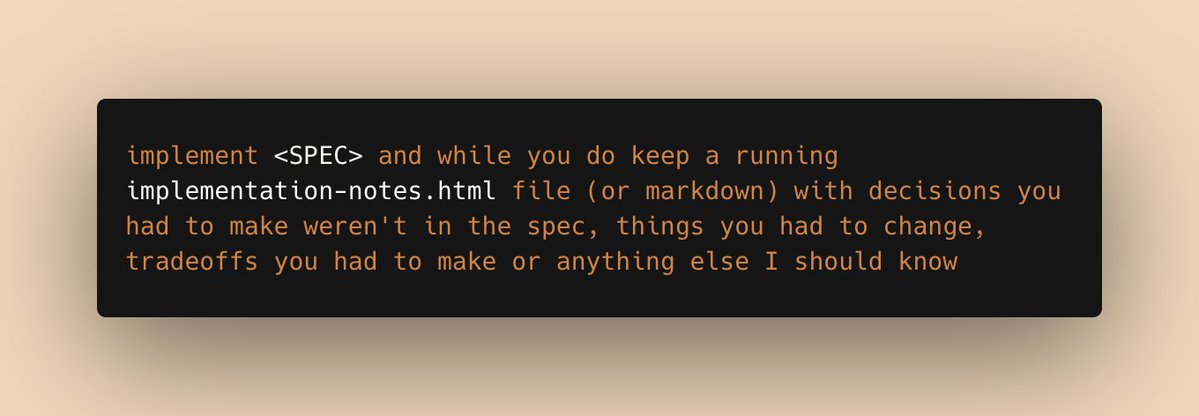
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
Codex can get dumber and slower on long sessions.
Here's the fix:
1. Run Process_narration=false
This will stop Codex from showing you all the planning steps, resulting in saving a lot of output tokens.
2. Prompt: "Act as an orchestrator. Use parallel agents to do the research and execution work. Write detailed tasks for each parallel agent and force them to act, iterate, get their tasks done, and bring back an in-depth report. Your job is to deeply analyze the agents' work, provide feedback, and provide them with continuous tasks."
This prompt offloads the majority of the context-burning work to agents, and each agent has its own context window. So you can utilize 5 agents (5 context windows).
3. Add this hard rule: "Measure twice, cut once policy."
Debugging and patching is messy work. Force Codex to plan first, act after (don't use plan mode; it's just overcomplicated). Ask it to make a task list for every task so it can track progress and iterate better.
4. Add this hard rule: "Keep the codebase clean, no tmp files, no dead code, no dead files. Stay organized all the time. No unnecessary folders, subfolders, or files."
Claude keeps most of its working files in cache as temporary files (which is bloatware, but it keeps the codebase neat), but Codex is output-heavy. It creates tons of folders and files, and your workspace can become a mess after a few sessions. As a result, this contaminates the context window and degrades performance. Force Codex to stay organized and follow the file structure.
These 4 techniques can help you save 40% context every session, and performance will be a lot better.
For planning, use Codex 5.5 (extra high), and after the plan is done, shift to Codex 5.5 (high) with fast mode. This works faster.
Instead of watching an hour of Netflix, watch this 2 hour hour Stanford lecture will teach you more about how LLMs like ChatGPT and Claude are built than most people working at top AI companies learn in their entire careers.
Claude Code ships with 5 architectural layers most engineers never open.
Not features. Not settings. Layers — each solving a distinct problem that LLMs alone can't solve. And four of them have nothing to do with prompting.
Here's the full Agent Development Kit:
Layer 1 — CLAUDE.md → The Memory Layer
Architecture rules, naming conventions, test expectations, repo map. Always loaded. Always active.
Two scopes:
• ~/.claude/CLAUDE.md → global
• .claude/CLAUDE.md → project
This isn't context you paste in before every session. It's context that never needs repeating. The agent's constitution.
Layer 2 — Skills → The Knowledge Layer
Each SKILL.md carries a description. Claude matches it at runtime and forks the skill into an isolated subagent. On-demand, never always-on.
Task-specific knowledge without inflating your main context window. Modular by design.
Layer 3 — Hooks → The Guardrail Layer
PreToolUse → PostToolUse → SessionStart → Stop → SubagentStop
This is the layer most teams skip. And the one they regret skipping first.
Hooks are NOT AI. They're deterministic event-driven shell commands.
• Auto-lint on every Write
• Hard-block on rm -rf
• Slack notification on Stop
Event fires → Matcher checks → Command runs
Quality enforced at the infrastructure level. Not the prompt level.
Layer 4 — Subagents → The Delegation Layer
Each subagent gets its own context window, model, tools, and permissions.
Main agent delegates down. Receives results up. That's it.
No infinite recursion — subagents can't spawn subagents. Main context stays clean. Hard boundaries by design.
Layer 5 — Plugins → The Distribution Layer
Bundle your skills + agents + hooks + commands into a plugin. One install. Whole team inherits the behavior.
Think npm packages — but for what your agent knows how to do.
Wrapping everything:
→ MCP Servers on the left (GitHub, databases, APIs, custom integrations)
→ Agent Teams on the right (parallel execution, message passing, shared permissions)
The 5-layer stack in one line:
CLAUDE.md sets rules → Skills provide expertise → Hooks enforce quality → Subagents delegate work → Plugins distribute to the team
Most production failures in agentic systems trace back to one missing layer.
Which one is the gap in your current setup?
As an AI Engineer. Please learn:
- Harness engineering, not just prompt engineering
- Prompt caching vs. semantic caching tradeoffs
- KV cache management at scale
- Speculative decoding vs quantization
- Structured output failures & fallback chains
- Evals (LLM-as-judge + human evals)
- Cost attribution per feature, not just per model
- Agent guardrails & loop budgets
- LLM observability as a first-class discipline
- Model routing & graceful fallback logic
- Knowing when to fine-tune vs. in-context learning
🔖 Claude Cookbook is worth bookmarking.
81 practical guides across 15 categories, covering agents, tools, RAG, evals, multimodal apps, Skills, integrations, and production workflows by @AnthropicAI
https://t.co/lgkTL6Av8F
Instead of watching an hour of Netflix, watch this 2-hour Stanford lecture.
It will teach you more about how LLMs like ChatGPT and Claude are actually built than most people in top AI companies learn across their entire careers.
Save this.
If I had to start with LLM from scratch, I'd learn these 30 concepts:
1 LLM
2 Token
3 Tokenization
4 Embeddings
5 Latent Space
6 Parameters
7 Pre-training
8 Base Model
9 Instruct Model
10 Fine-Tuning
11 Alignment
12 RLHF
13 Prompt
14 System Prompt
15 User Prompt
16 Context Window
17 Zero-Shot Learning
18 Few-Shot Learning
19 Chain-of-Thought
20 Inference
21 Latency
22 Temperature
23 Hallucination
24 Grounding
25 RAG
26 Workflow
27 Agent
28 Multimodality
29 Benchmarks
30 Guardrails
What else should make this list?
Cet atelier de 30 minutes, animé par le créateur de Claude Code, vous en apprendra plus sur le
vibe-coding que 100 tutoriels vidéo sur YouTube.
Ajoutez-le à vos favoris et consacrez-y 30 minutes dès aujourd'hui.
Cette vidéo transformera votre utilisation de Claude à jamais.
Anthropic pays engineers $750,000+ a year to understand how LLMs work.
Stanford just put a 2 hour lecture that covers 80% of it for FREE.
Bookmark this. Give it 2 hours today.
It might be the highest ROI thing you do this month:
Path param identifies one exact resource in the url structure. It fits single item lookup by its unique id.
Query param works for filters on a list endpoint. It stays optional and supports multiple conditions at once.
Both can technically return the same data but the first one signals clear resource identity in rest design. The second one signals search or narrow down on collection.
This separation helps routing, caching and overall clarity in bigger systems.