Deployment of large audio-language models is challenging. We compressed Qwen2-Audio-7B to be 50% smaller, while retaining #speech translation quality. We used a mix of ✂️ iterative layer pruning, 💿quantization, and 📚knowledge distillation
#IWSLT2025
https://t.co/7a0LJCFLCd
Hi Colleagues! I am looking for a volunteer to lightly proofread my new paper on "efficient" speech translation. If you are interested, please message me. I will highly appreciate it, and will owe you one. There is a chance you will enjoy reading it too. ;)
The Power of Prompt Engineering
Prompt engineering has evolved considerably over the last year. It's become a legit profession, with several real engineers specializing in the area and others writing research papers!
This is a good survey paper that outlines all the different types of prompt engineering (link in alt)
Prompting Strategies: Various prompting strategies are discussed, including but not limited to:
Chain of Thought (CoT)
Chain of Cause (CoC)
Program-Aided Language models (PAL)
Tree of Thoughts (ToT)
Least-to-Most
Self-Consistency
Analogical Reasoning
It's incredible how much you can do with an LLM if you understand these prompting strategies and apply them appropriately based on the suitable dataset and use-cases
Seven years ago, the paper Attention is all you need introduced the Transformer architecture. The world of deep learning has never been the same since then. Transformers are used for every modality nowadays.
Despite their nearly universal adoption, especially for large language models, the internal workings of transformers are not well understood.
Through our paper titled, Transformer Layers as Painters, we aim to understand the flow of information in a pretrained transformer. We present a series of experiments for both decoder-only and encoder-only frozen transformer models. Note that we do not perform any kind of fine-tuning on these pretrained models. Here are our findings:
1. Do layers speak the same language?
To check this, we ran a few experiments. For example, What if we skip some layers? For example, if we changed the output flow (layer 4 -> layer 5 -> 6) to (layer 4 -> layer 6) by skipping layer 5 entirely, how much does the performance deteriorate? What if we switch the order of neighbuoring layers? For example, feeding the output of layer 4 to layer 6, then sending the output of layer 6 to layer 5, then to layer 7.
Based on a series of experiments, we noticed that the representation space of a transformer-based model can be partitioned into three types: beginning layers, middle layers, and ending layers. The middle layers seem to share a common representation space.
2. Are all layers necessary?
If the middle layers share the representation space, can we drop some layers without getting a performance hit? To check this, we send the output of the Nth layer directly into the input of layer N + M (where M > 1), thereby “skipping” M − 1 layers. We found that at least a few middle layers can be dropped without catastrophic failure.
3. Are the middle layers all doing the same thing?
Does shared representation represent redundancy? If yes, how much redundancy can we get rid of?
We ran an experiment where, instead of skipping some of the layers, we replaced their weights with those of the center layer, effectively looping on this layer for (T − 2N + 1) times, where is the total number of layers (32 for Llama2-7B, 24 for BERT-Large).
We found that even though the middle layers share the representation space, they perform different functions, and sharing weights among the middle layers is catastrophic.
4. Does the layer order matter?
If the layers perform different functions in a shared representation space, how much does the order of these functions matter?
We performed two sets of experiments on this. First, we ran all these layers in the reverse order of how they were trained. Specifically, we take the output of (T − N)th layer and send it into the input of (T − N − 1)th layer, then the output of this layer into (T − N − 2)th layer, and so on down to Nth layer.
In the second variation, we ran the middle layers in a random order. The order matters to an extent as randomizing and reversing the middle layer order have graceful degradation.
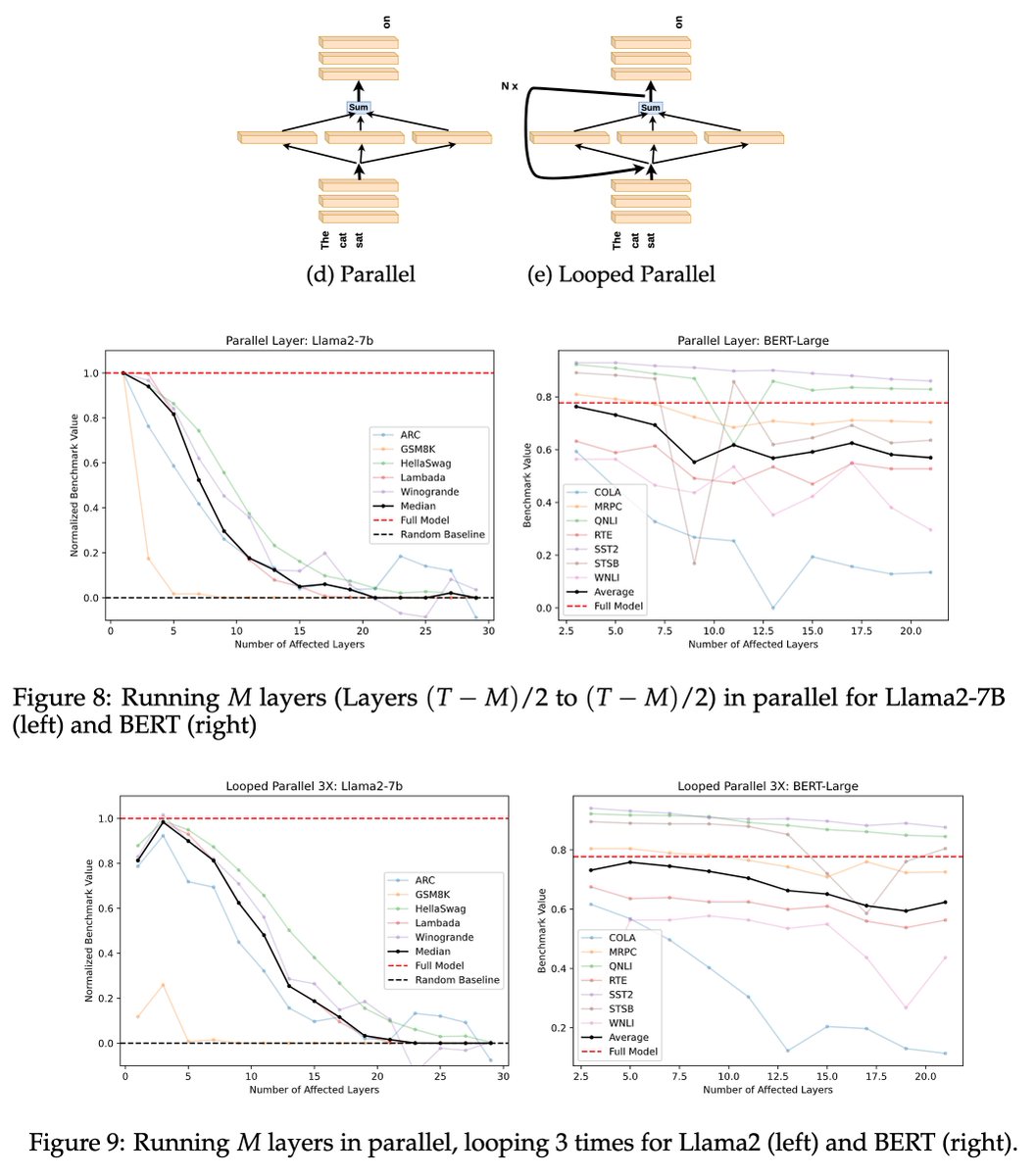
5. Can we run the layers in parallel?
If the presence of the layers is more important than the order in which they’re executed, can we run the layers independently from an early input and merge their results? We found out that we could do this without a major hit except for math-heavy benchmarks.
6. Does the order matter for some tasks more than others?
We noticed that for all variants (reversed, skip, parallel), ARC and GSM8K (i.e. reasoning and mathematical tasks) had the steepest decline. Performing well on these benchmarks requires a model to be sound both structurally, and semantically. This would be consistent with the hypothesis that some degree of order-dependent reasoning is happening within a single pass of the model. Therefore, we conclude that some tasks are more order-dependent than others and require more than just semantics.
7. Does looping help parallelized layers?
What if we loop the mean output of the parallelized layers M times back into the same layers for a fixed number of iterations? The hypothesis is that if a layer performs only a certain subset of functions, then iterating the parallelized layer from the previous experiment should improve performance compared to a single execution of the parallelized layer. We found that this is true with the optimal number of iterations proportional to the number of parallelized layers.
8. Which design variants are least harmful?
Repeating a single layer is the worst. Randomizing the layer order and looped-parallel do the least damage.
WHY Transformer Architecture does NOT have vanishing gradients problem as opposed to RNN ❓
The improved gradient flow in Transformers is indeed facilitated by their architectural design.
📌 Access to all tokens in Transformers does play a significant role in mitigating vanishing gradients, albeit indirectly. It allows for more direct pathways for gradient flow, which is an important factor.
📌 In the transformer architecture at every layer you still have access to all the input tokens, which is in stark contrast to any RNN where each token is processed one by one.
📌 No Sequential Dependency: Unlike in RNNs, where the computation for the i-th token depends on the computations for tokens 1 to i-1, in self-attention, all these comparisons happen independently and simultaneously.
📌 Self-attention allows the Transformer model to weigh the importance of different input tokens when making predictions, enabling it to capture long-range dependencies without the need for sequential processing.
--------
RNNs are sequential models that process data one element at a time, maintaining an internal hidden state that is updated at each step. They operate in a recurrent manner, where the output at each step depends on the previous hidden state and the current input.
Transformers are non-sequential models that process data in parallel. They rely on self-attention mechanisms to capture dependencies between different elements in the input sequence. Transformers do not have recurrent connections or hidden states.
--------
📌 In the Transformer, due to the self-attention mechanism, every token in a sequence has the potential to directly attend to every other token, irrespective of their relative positions. This means that the information flow between distant tokens is not constrained by the sequential processing nature seen in RNNs.
📌 RNNs inherently process sequences in a step-by-step manner. This means that to relay information from an early token to a later position, the information must be propagated through every intermediate step. This can potentially lead to vanishing (or even exploding) gradients, especially for long sequences, as the gradient signal might diminish (or explode) as it's backpropagated through time.
📌 The direct connections between all tokens in the Transformer ensure that there is no need to go through potentially many intermediate steps (as with RNNs) for the gradient to flow from one token's position to another. This architecture design allows for more direct gradient pathways during backpropagation.
📌 Additionally, residual connections in Transformers further alleviate the vanishing gradient problem. These connections ensure that the gradient can flow unimpeded through the network, bypassing certain layers if necessary.
📌 It's also important to note that normalization techniques, like Layer Normalization, employed in Transformer models further stabilize the training process. Stable activations reduce the risk of gradients becoming too small or too large.
In conclusion,
→ Translating business problems into *the right" data science problem is what separates a senior from a junior data scientist.
→ Ask the right questions, list possible solutions, and explore the data to narrow down the list to one.
→ Solve this one problem.
Low-rank updating mechanism (LoRA) may limit the ability of LLMs to effectively learn and memorize new knowledge. 🤔
Now we can solve it with MoRA, which employs a square matrix to achieve high-rank updating while maintaining the same number of trainable parameters. ✨
MoRA outperforms LoRA on memory-intensive tasks and achieves comparable performance on other tasks, demonstrating the effectiveness of high-rank updating.
👉 "MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning"
📌 For instance, when utilizing 8 rank with the hidden size 4096, LoRA employs two low-rank matrices A ∈ R 4096×8 and B ∈ R 8×4096, with rank(∆W) ≤ 8.
Under the same number of parameters, MoRA uses a square matrix M ∈ R 256×256, with rank(∆W) ≤ 256.
📌 In MoRA, they use a trainable square matrix applied to the original weights W instead of the matrices AB in LoRA. However, the number of trainable parameters in LoRA and MoRA can be the same. For example, if the original weight layer has 4096 x 4096 = 16,777,216 parameters, LoRA with r=8 has 4096x8 + 8x4096 = 65,536 parameters. With MoRA, we can match the number of parameters via r=256, i.e., 256 x 256 = 65,536.
How do you apply this 256x256 matrix to the original 1024x1024 weight matrix? They define several non-parametric compression and decompression methods
📌 Experiments show that MoRA matches LoRA's performance in instruction tuning and mathematical reasoning, and exhibits superior performance in continual pretraining and memory tasks. In pretraining experiments, MoRA outperforms LoRA and ReLoRA, further demonstrating the effectiveness of high-rank updating.
📌 Analysis of the spectrum of singular values for the learned ∆W reveals that MoRA and ReMoRA (MoRA with merge-and-reinit) exhibit a substantially higher number of significant singular values compared to LoRA and ReLoRA, highlighting their effectiveness in increasing the rank of ∆W.
A key to making your LLMs work better: just throw everything into the context window 💡
For many datasets, for most of the time, the long-context ICL (in-context learning) outperforms finetuning on the model. 👨🔧
Here is a very long thread on some of the most influential papers from the recent past, exploring efficient context-window increase of LLMs👇
--------------
🧵 1/n
Techniques proposed in this paper has become more important after the Llama-3.
Paper - "Extending LLMs' Context Window with 100 Samples" ✨
📌 This method (entropy-aware ABF (adjusted base frequency)) extends the context window of LLaMA-2-7B-Chat to 16,384 with only 100 samples and 6 training steps.
NTK-Aware scaling and adjusted base frequency (ABF) modify the base frequency of RoPE, leading to enhanced results in fine-tuning and non-fine-tuning scenarios respectively.
📌 Recent studies have sought to extend LLMs' context window by modifying rotary position embedding (RoPE), a popular position encoding method adopted by well-known LLMs such as LLaMA, PaLM, and GPT-NeoX. However, prior works like Position Interpolation (PI) and YaRN are resource-intensive and lack comparative experiments to assess their applicability.
📌 This work identifies the inherent need for LLMs' attention entropy (i.e. the information entropy of attention scores) to maintain stability and introduce a novel extension to RoPE which combines adjusting RoPE's base frequency and scaling the attention logits to help LLMs efficiently adapt to a larger context window.
Finally, we also explore how data compositions and training curricula affect context window extension for specific downstream tasks, suggesting fine-tuning LLMs with lengthy conversations as a good starting point. We release our code and SFT data at this https URL.
LLMs often underperform on low-resource languages, especially for complex NLP tasks
🚨Introducing a framework to boost LLM's multilingual instruction-following information extraction capability.
- train LLM to leverage English translation
- boost African NER and OOD performance
🎙️ Join Israel for a presentation on : "Walia-LLM: Enhancing Amharic-LLaMA by Integrating Task-Specific and Generative Datasets" https://t.co/d5ht5Ep9MU
📅 Date: Tuesday, April 30, 2024
⏰ Time: 4 PM UTC
🔗 Zoom Link: Available on Slack
Be there!🚀
#Masakhane#NLP