@guilhermeotina Exactly! But this begs the question of how to push people towards including the verifier audits.
We (at HART) have spent a lot of time in parallel with building a benchmark on building and auditing an agentic verifier. Shameless plug to Gandalf :D https://t.co/NWllGZNlXn
"A benchmark is only as good as its verifier."
To me, the verifier audit is the coolest part of the release!
I hope everyone includes similar sections when presenting new benchmarks in the future.
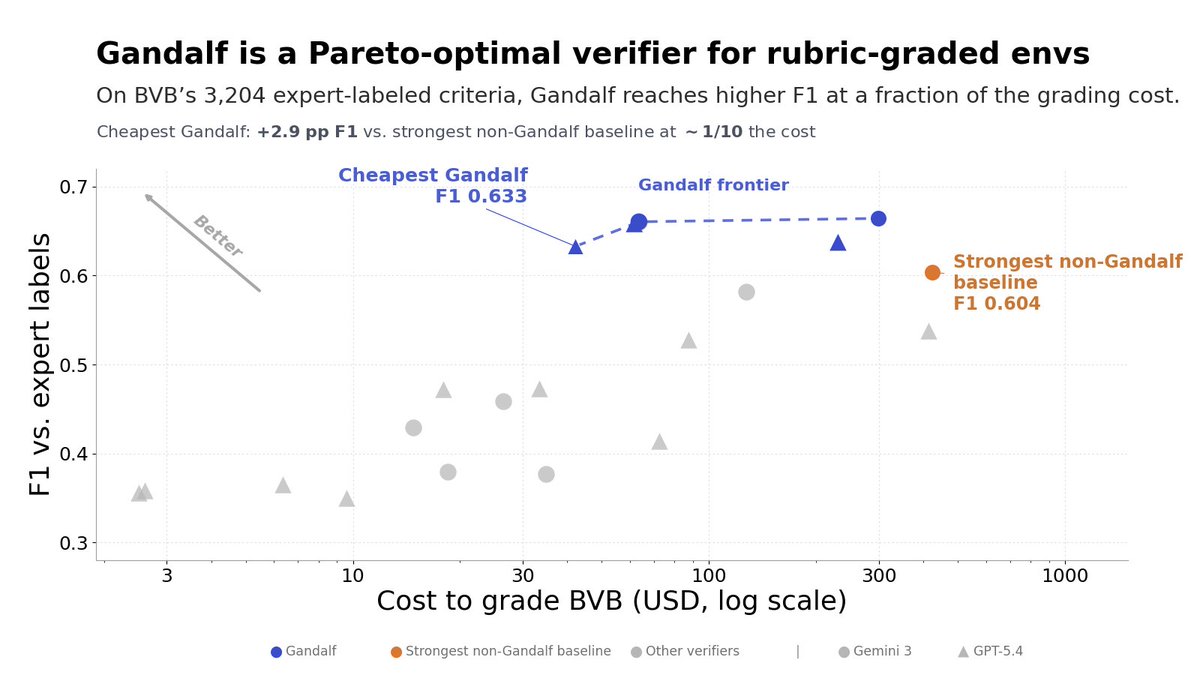
And I will hopefully have something similar/more to share soon🤞 (tomorrow even?)
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
How good is the verifier?
Many benchmarks make the verifier a sub(sub)section in the paper, even though the verifier is a critical element of the benchmark. We wanted to change that!
This resulted in an agentic verifier we called Gandalf.
Only the good shall pass 🧙♂️
Grading agent rollouts in rubric-graded RL environments is itself a hard task.
Prior approaches pass serialized artifacts or agent trajectories to an LLM judge; this loses information / doesn't support sophisticated criteria.
In contrast, we built a reactive agentic judge.
To build this, I find starting with imitation learning is the best. However, here it is critical that you imitate really strong samples.
If you go to a top ML conference, most of the posters are not that great, and you are worse off if you imitate the average poster
My take:
Good research taste means that you can come up with interesting ideas, propose ways to test them (both positive and negative tests), and then communicate the idea and results in a way that is useful for others
Late-night thought.
Two debates are happening in parallel:
1) AI will take all our jobs
2) We do not have enough nurses/engineers/doctors/...
These seem to be opposing. Can they really be true at the same time?
If not, then we could choose to be optimistic about the future! :D
In 2025, RLVR was the big thing following the DeepSeek moment. Now, RL for LLMs is increasingly focusing on semi-verifiable domains. After joining HART, I asked just how good a verifier has to be. The answer? Imperfection is not a problem!
With @anishathalye and @guzmanhe
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner@guzmanhe