Excited to share that I’ll start as Professor of Data Systems @utn_nuremberg in early 2024! My research will explore the intersection of data systems and ML.
I’ll soon announce PhD and postdoc positions in my group.
📣 🏆2026 SIGMOD Research Highlight Awards 🏆:
https://t.co/r5jftg2zNz
DPconv: Super-Polynomially Faster Join Ordering
@mihail_sto, @andreaskipf
https://t.co/f38OeqGoWr
Automating Vectorized Distributed Graph Computation
Wenyue Zhao, Yang Cao, Peter Buneman, Jia Li, @ntarmos
https://t.co/4BL6HB16o7
AnyBlox: A Framework for Self-Decoding Datasets
Mateusz Gienieczko, @maxikuschewski, Thomas Neumann, Viktor Leis, @JanaGiceva
https://t.co/qxqdMMjCw3
Rel: A Programming Language for Relational Data
@molhamaref, Paolo Guagliardo, @gkastrinis, Leonid Libkin, Victor Marsault, Wim Martens, Mary McGrath, Filip Murlak, Nathaniel Nystrom, Liat Peterfreund, Allison Rogers, Cristina Sirangelo, Domagoj Vrgoč, David Zhao, Abdul Zreika
https://t.co/xO5v44v4Yi
MEMPHIS: Holistic Lineage-based Reuse and Memory Management for Multi-backend ML Systems
@ArnabPhani, @matthiasboehm7
https://t.co/YRbr8x1nov
Diva: Dynamic Range Filter for Var-Length Keys and Queries
Navid Eslami, @IoanaBercea, @niv_dayan
https://t.co/ddwHqGHeaC
The Key to Effective UDF Optimization: Before Inlining, First Perform Outlining
Samuel Arch, Yuchen Liu, Todd C. Mowry, @pateljm, @andy_pavlo
https://t.co/yclqSE6VFT
Output-sensitive Conjunctive Query Evaluation
@ShaleenDeep, @HangdongZ79542, Austen Z. Fan, Paraschos Koutris
https://t.co/5aj48xeUZJ
Output-Optimal Algorithms for Join-Aggregate Queries
Xiao Hu
https://t.co/VbrUbnXarQ
Differentially Private Substring and Document Counting
Giulia Bernardini, @philipbille, @li_rtz, Teresa Anna Steiner
https://t.co/GYCjSDeV9l
Congratulations to all the authors👏 👏 💐
#SIGMOD2026 #ACM #researchhighlight #SIGMODawards
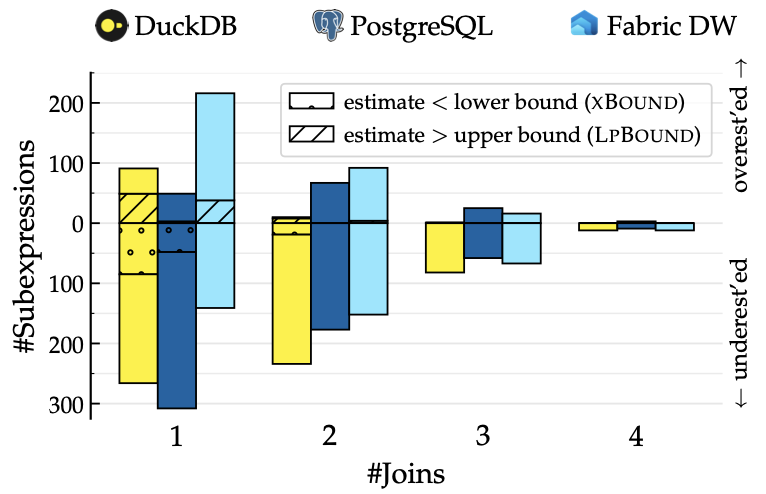
Can your cloud database predict underprovisioning before it even happens?
Meet ◒ xBound, the very first framework for join size lower bounds. xBound tells you how many tuples your SQL query will produce *at least*.
Brought to you by Microsoft GSL & @utndatasystems.
I hope you've had a great start to the year! I'm excited to announce our blog. We're kicking things off with a look back at everything that happened in 2025.
https://t.co/cU8qhHe8xt
PoC customer bringing their own workload to test?
👉 Boost their LIKE/REGEX predicates with 🌰 string fingerprints.
Freshly presented at AIDB'25 @VLDBconf.
Paper: https://t.co/1Hjg7zniPq
Code: https://t.co/86NG2JFz9W
Today we release Franca, a new vision Foundation Model that matches and sometimes outperforms DINOv2.
The data, the training code and the model weights (with intermediate checkpoints) are open-source, allowing everyone to build on this.
Methodologically, we introduce two new SSL components, one is a multi-granularity SK clustering loss that utilizes Matryoshka representations and a quick post-pretraining scheme to remove unwanted spatial biases.
This is the result of a close and fun collaboration @valeoai (in France) and @FunAILab (in Franconia)
🛠️ The position requires strong programming skills in C++ and Python.
We've already published early results in this space:
- Virtual, TRL @ NeurIPS'24: https://t.co/rfiQutLm3v
- Virtual, EDBT'25 (Best Demo): https://t.co/4rcgVFC7yu
Off to SIGMOD 2025 in Berlin! 🚄
Here’s our schedule:
Today, 4:20 PM:
💡 Redbench: A Benchmark Reflecting Real Workloads (aiDM)
Wed, 2:00 PM:
🏆 DPconv: Super-Polynomially Faster Join Ordering
Thu, 2:30 PM:
❄️ Pruning in Snowflake: Working Smarter, Not Harder
Come say hi! 👋
Parachute takes semi-join filtering to the next level!
Congrats to my PhD student @mihail_sto and thanks to our co-authors from MIT for initiating the project four years ago.
See you in London! 🇬🇧
Delighted to announce that Parachute 🪂 will appear at @VLDBconf! 🇬🇧
Compared to regular semi-join filtering, Parachute removes dangling tuples in a bi-directional manner by precomputing fingerprint columns.
Dangling tuples ⏬ = Join pruning ⏫.
📎 https://t.co/P80WXLb6Qp
DPconv just won a SIGMOD'25 Honorable Mention! 🥁
I was quite impressed given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Thrilled to share that we've received the Best Demonstration Award 🏆 at EDBT 2025!
Congratulations to my students @mihail_sto and Ping-Lin Kuo for their excellent work and dedication over the past few weeks—well deserved!
Paper: https://t.co/4rcgVFBzIW
We just released Redbench, a new benchmark that contains 30 analytical SQL workloads that can be used to benchmark workload-driven optimizations. Go check it out!
GitHub: https://t.co/LKBsXc8347