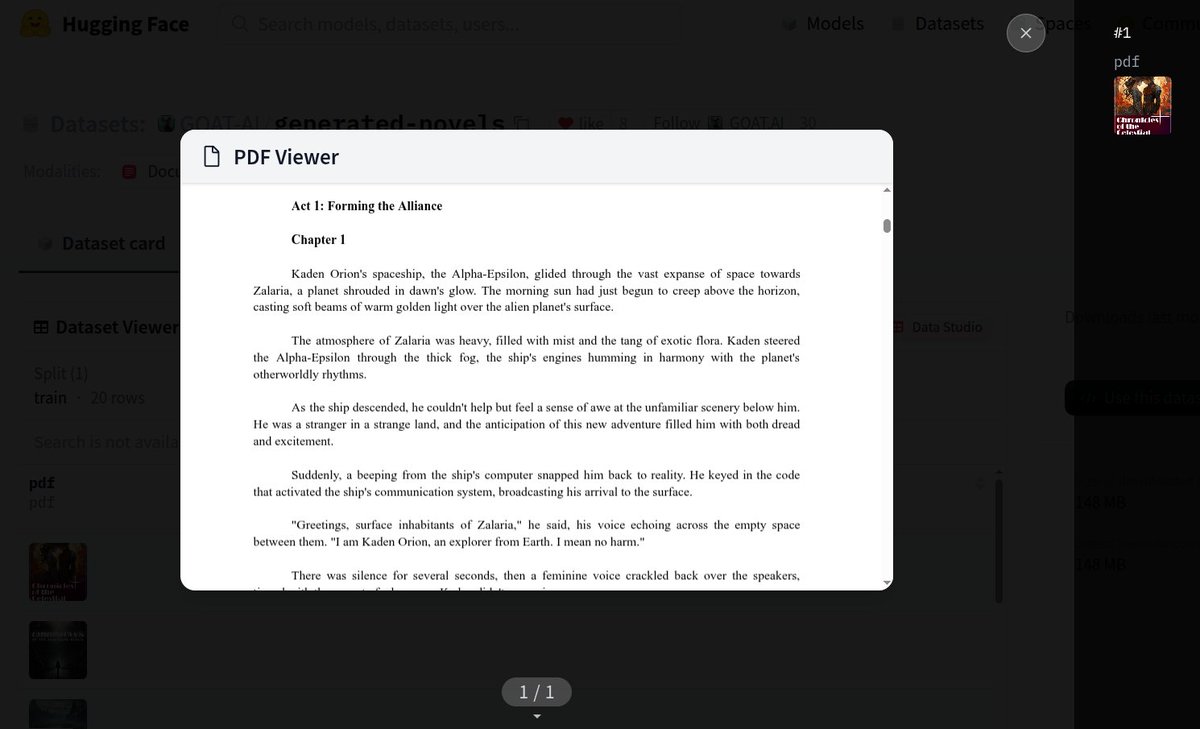
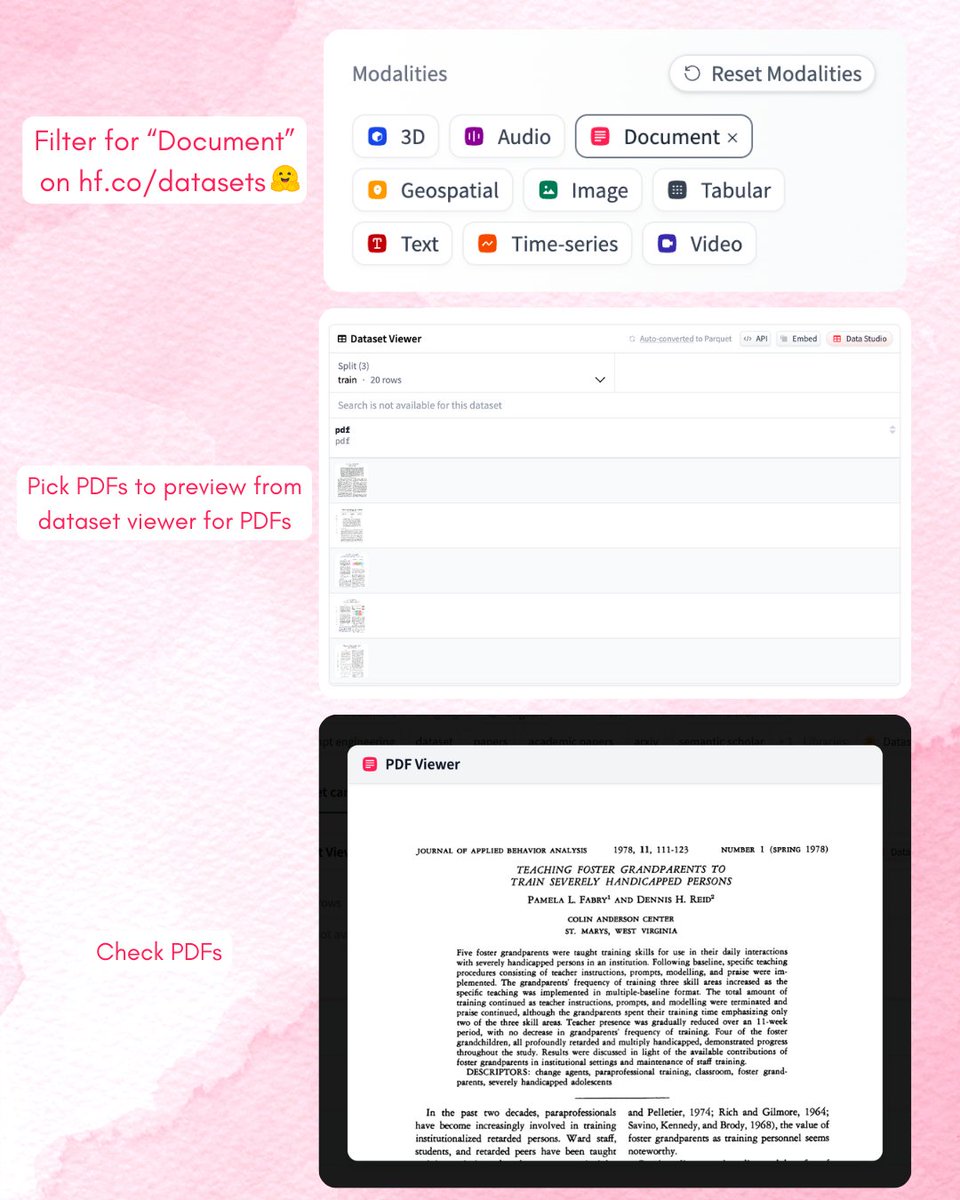
📄 New on Hugging Face Hub: native PDF dataset support!
You can now render PDFs directly in the Dataset Viewer — with thumbnails, in-browser previews, and full integration with datasets + pdfplumber.
Perfect for document-based ML workflows →
https://t.co/BXQygtnHVZ
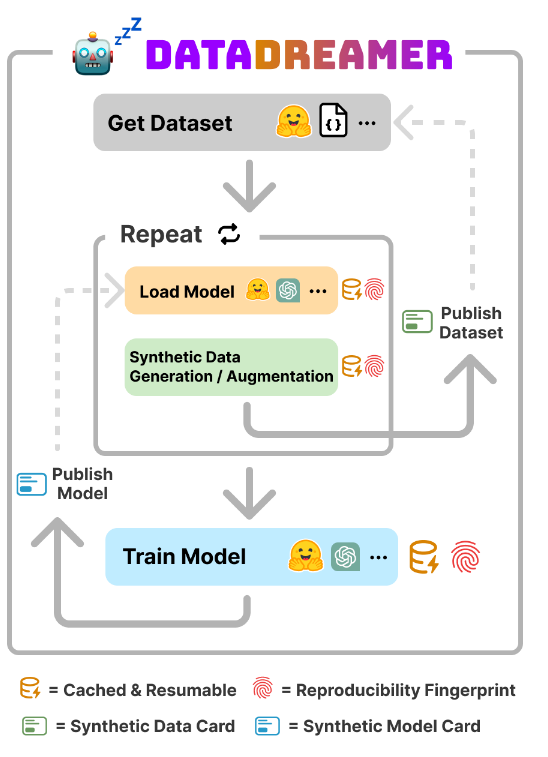
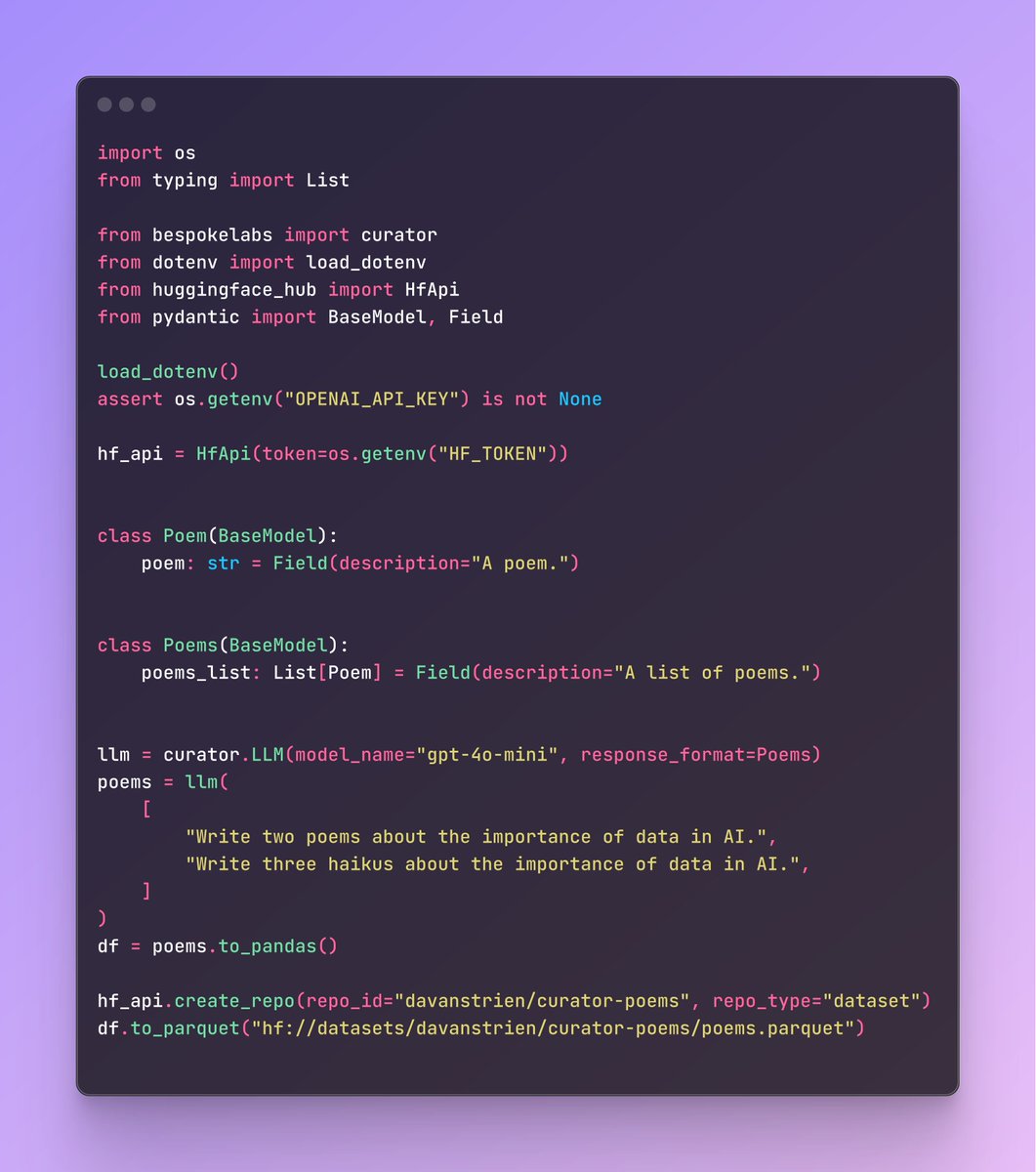
🚀 Synthetic data is revolutionizing AI & ML!
DataDreamer, an open-source Python library, makes generating synthetic data seamless & integrates effortlessly with @huggingface . Easily push datasets to the Hub and share them with the community
🔍 Learn how: https://t.co/oyZ6bpqXU1
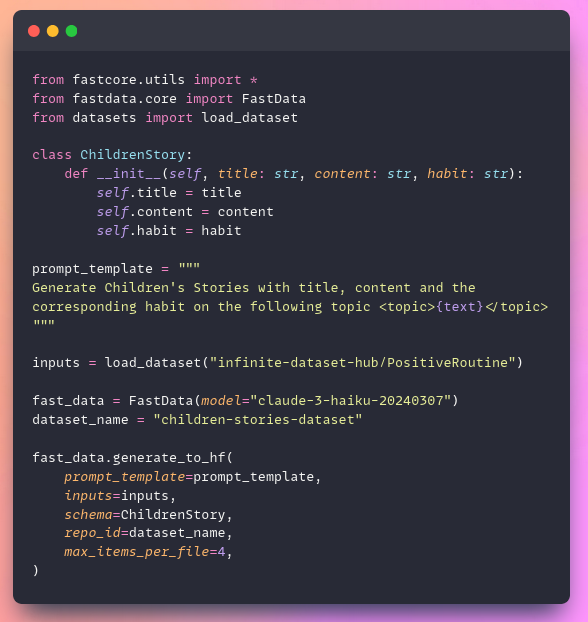
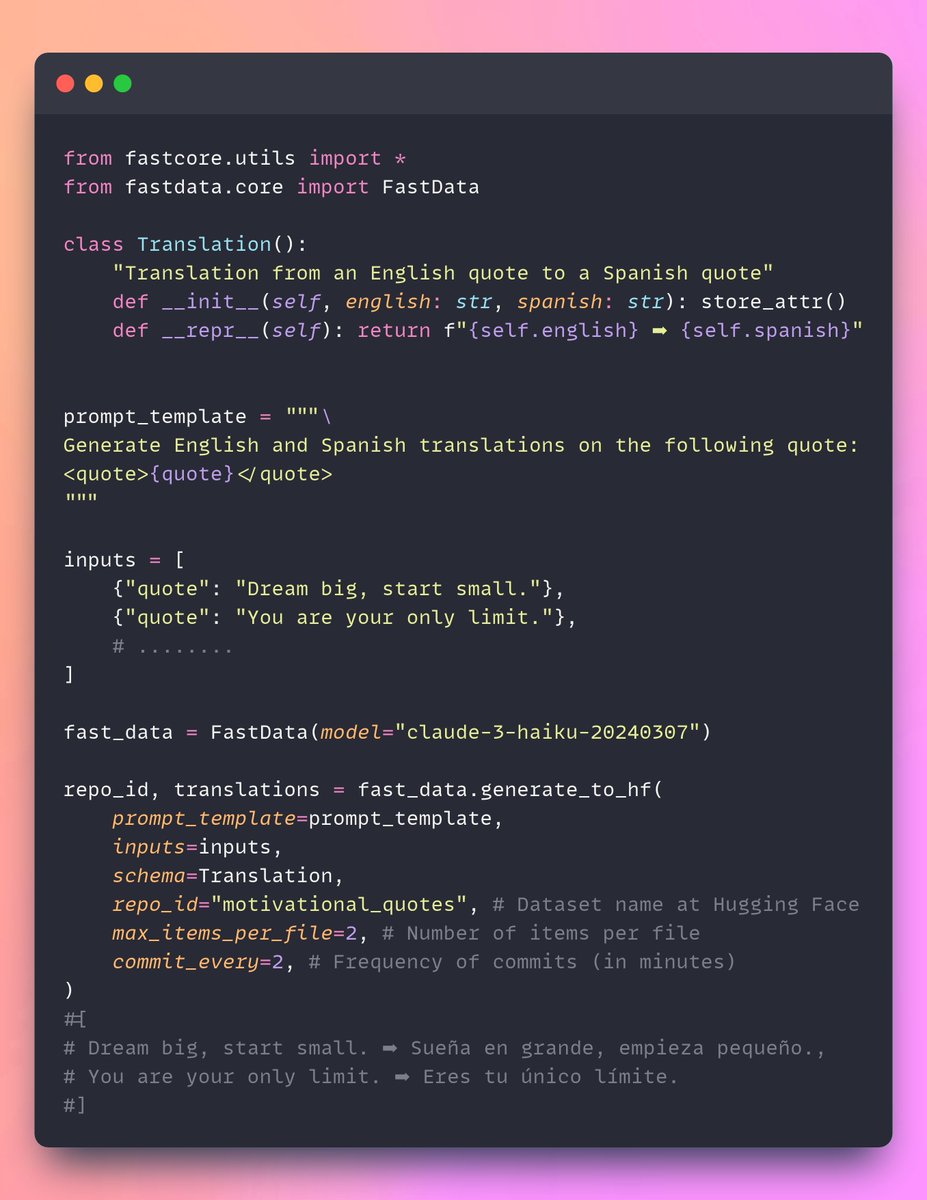
Synthetic data generation has never been easier! 🎉
Generate structured output effortlessly with #fastdata and @huggingface 🚀
Steps:
1️⃣ Define your schema 📝
2️⃣ Add a generation prompt 💡
3️⃣ Input your data 🔄
4️⃣ Share it freely on Hugging Face 🌍
Damn this is cool
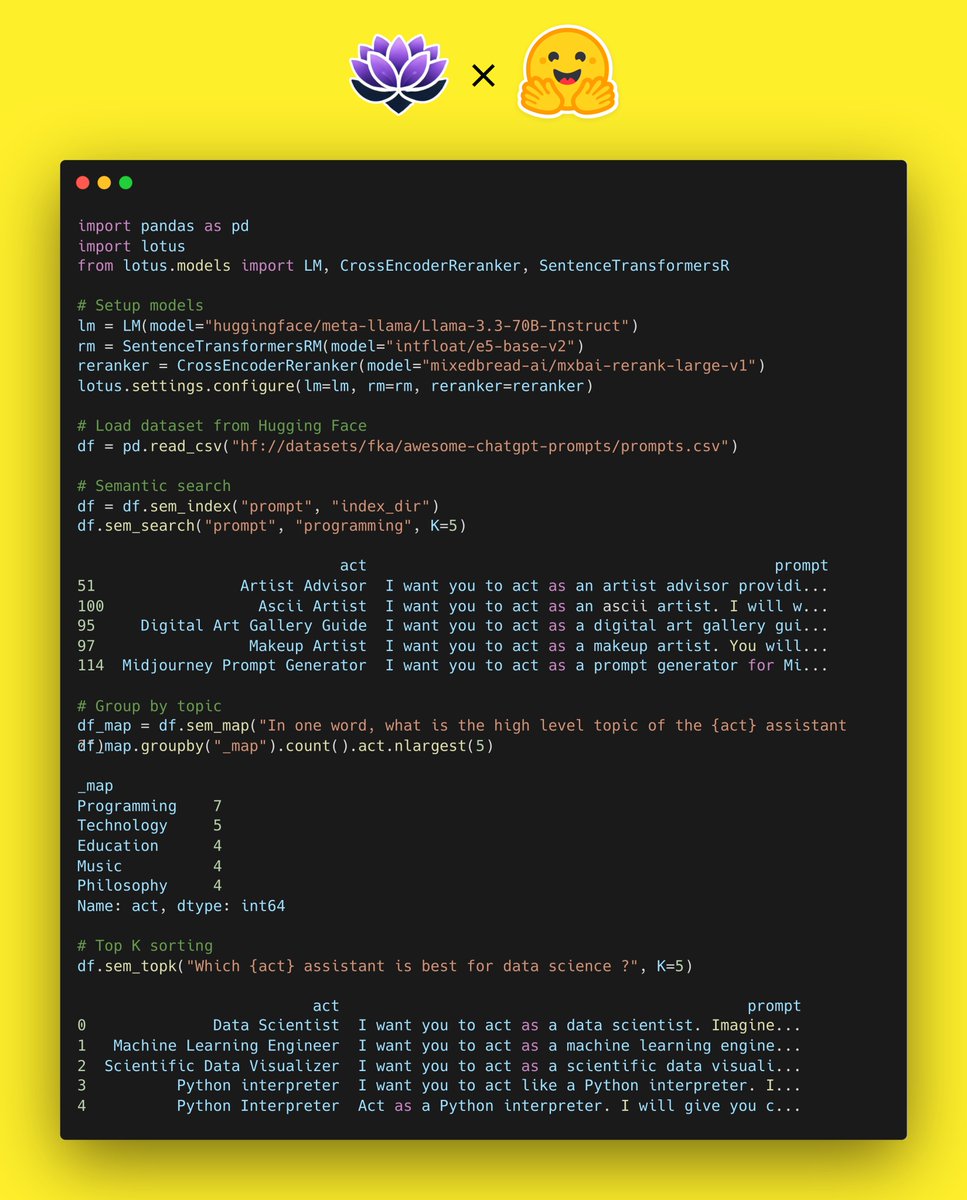
Semantic operations for pandas dataframes using open models from @huggingface. Brought to you by @lianapatel_ and the LOTUS team at Stanford and Berkeley
Semantic search, Group by topic, Top K semantic sorting etc. with LLama 3.3 70B
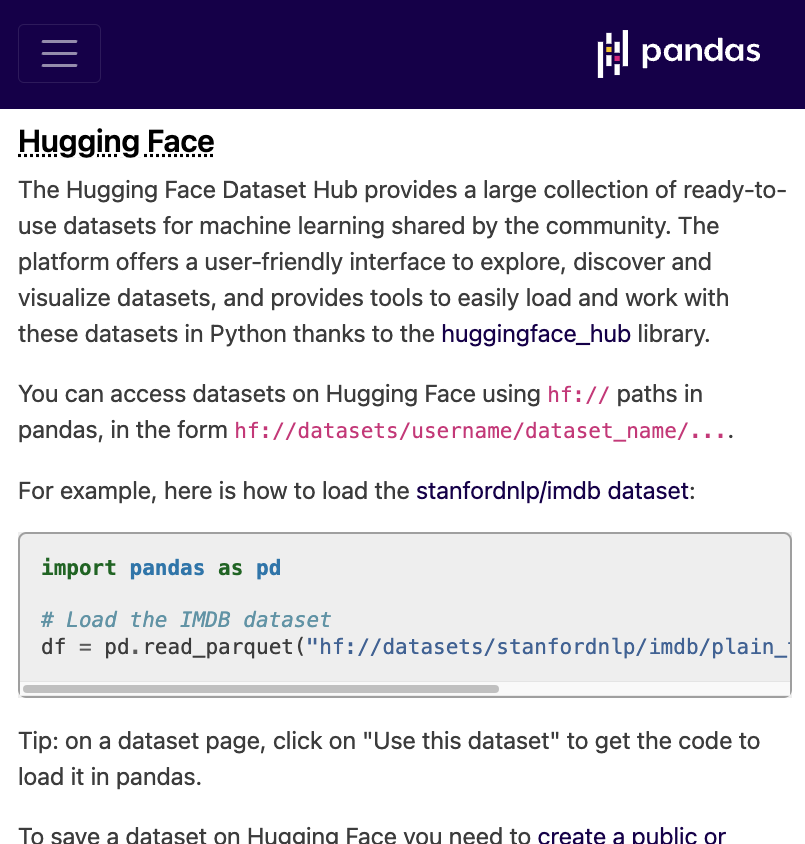
🤗 Datasets 3.2 is out !
With faster Parquet streaming (up to +100% speed) and faster filtering via predicate pushdown ⚡
Example: fast streaming of recent FineWeb-2 data from @huggingface
@huggingface has released a new feature that makes interacting with datasets even easier. 🌟
Introducing the #Text2SQL feature for the SQL Console – now you can talk to your dataset like never before! 🗣️💻
🚀 Fastdata (by @answerdotai) + @huggingface: Synthetic Data Made Simple! 🤖📊
Generate data for deep learning 📜🛠️🎯 and push it directly to Hugging Face Hub 🌐. With Incremental Uploads, fastdata handles large-scale projects effortlessly!
✨ How it works:
1️⃣ Define your output schema 📜
2️⃣ Craft your data generation prompt 🛠️
3️⃣ Prepare your inputs 🎯
4️⃣ Generate and push to Hugging Face Hub directly 🚀
💡 Pro Tip: With Incremental Uploads, fastdata can automatically push updates to the Hub every N minutes, making it perfect for large-scale synthetic data projects.
My new app is out !!
✨The Common Crawl Pipeline Creator ✨
Create your pipeline easily:
✔Run Text Extraction✂️
✔Define Language Filters🌐
✔Customize text quality💯
✔See Live Results👀
✔Get Python code 🐍
Based on famous LLM research like Gopher, C4 or FineWeb
🔥 Presentamos #LaLeadeboard, la primera leaderboard open-source para evaluar automáticamente #LLM en las variedades del español y lenguas oficiales de España y LATAM.
https://t.co/EklRbCex8m
There is now an LLM Leaderboard for one of the most spoken language worldwide: Spanish! 🚀
(+ Catalan, Basque and Galician)
Congrats to @mariagrandury for setting it up, and to @SomosNLP_ for gathering super high quality datasets from many partners!
https://t.co/UCZQo1S2gl