The term "markerless" gets thrown around a lot in motion capture. What does it mean? Well...surprise! There are still markers (we put them on you instead of you getting in a suit)
When we capture motion from your videos, we still need to estimate important landmarks, we've just built a way to do it on a web camera instead of a $100k mocap stage.
Multi person + scale aware with extremely good camera pose estimation.
Try it out and let me know what you think
Hoy una industria entera dejó de tener sentido.
Un tío publicó en GitHub un repo que convierte cualquier foto en un mundo 3D explorable: meshes con físicas, splat del fondo, audio ambiente. Todo.
Una imagen entra. Un mundo sale. Cinco minutos.
La gente que se pasó diez años aprendiendo Blender lleva todo el día mirando esto en silencio.
Se llama image-blaster.
I'm testing out Gaussian splatting generation using LTX 2.3 and Postshot. It’s working pretty well, though there are still a few minor glitches. @ltx_model
For those interested in Gaussian Splatting, I just found a awesome free open-source tool that generates high-quality GS. You can download it here:
https://t.co/Y7bg0gKz6O
Precise camera control in LTX 2.3 is finally here. 🎬🚀
The new "Camera Man" IC LoRA allows you to transfer cinematic motions—Zoom, Pan, Orbit—directly to your AI videos.
⚠️ The golden rule: Keep your prompts SIMPLE. Detailed action descriptions will actually LOCK the camera movement.
Full workflow & deep dive: 👇
🔗 https://t.co/t7ELvcxB2T
#LTX23 #ComfyUI #AIVideo #GenerativeAI #CameraControl
Upscale-style LoKr for FLUX.2 Klein 9B.
- refines skin, hair, aanatomical details
- corrects low-res artifacts, mostly;
- preserves identity, image structure.
Like how it improves hair and fur.
https://t.co/QTQELGl9zL
Took it further with @omma_ai, (@splinetool ) now it works on video, and everything working in a Web Browser.
Drop a video, Depth Anything v2 calculates the depth map frame by frame, and Three.js renders a fully lit 3D mesh in real time.
Depth estimation on video in the browser
+Automatic baking pass
+ Dynamic lighting reacting to the geometry
#vibecoding #threejs #webgl
Holy crap, NVIDIA just made it drastically easier to create large scale explorable 3d worlds.
No manual stitching of smaller 3d generations like other 3d models. Lyra 2.0 looks pretty damn impressive.
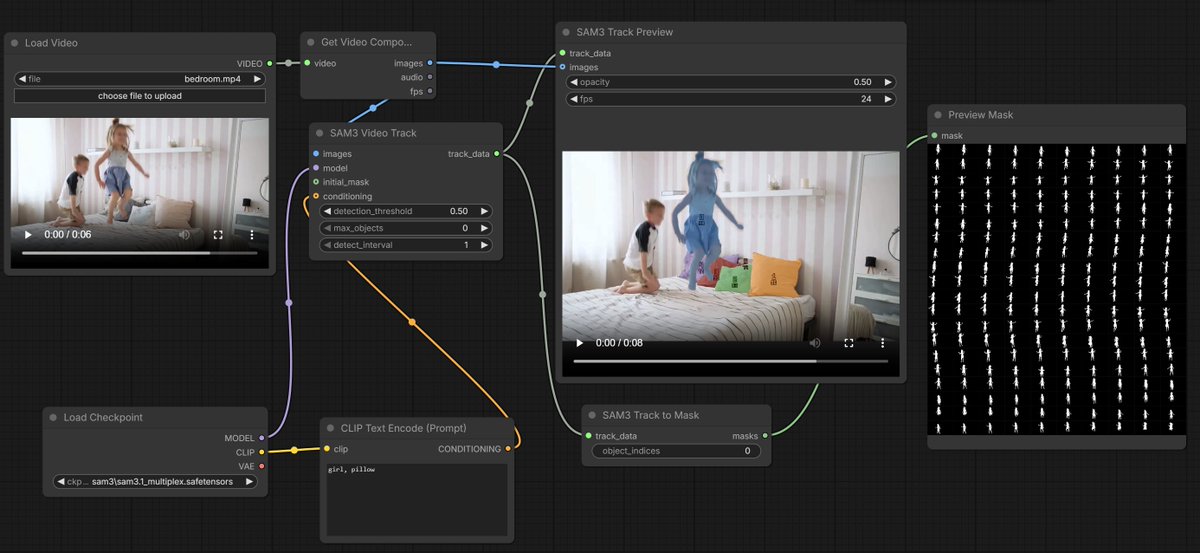
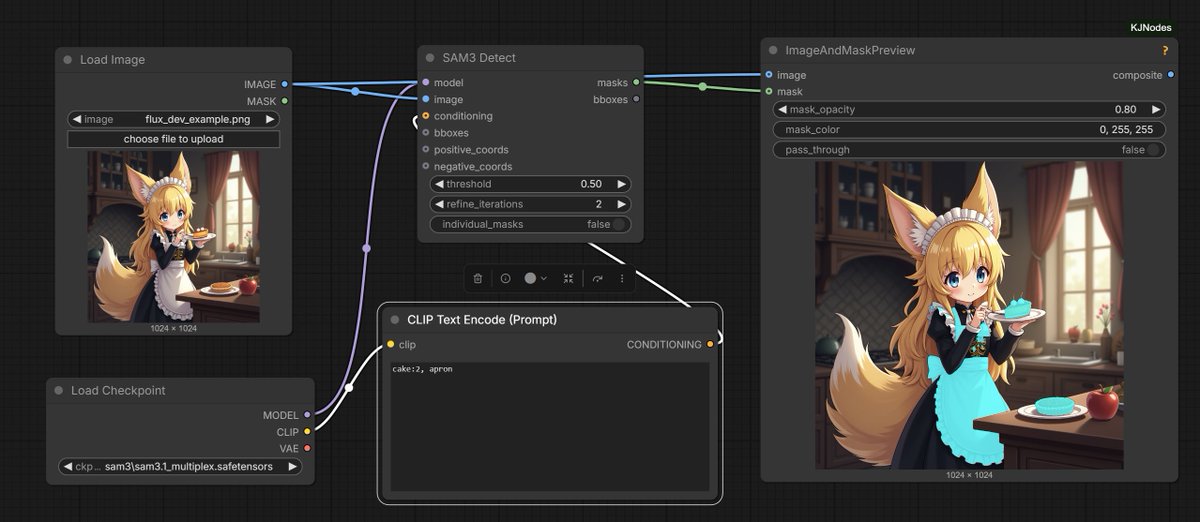
Heck yes! ComfyUI getting native SAM 3.1 support.
-multiplex video tracking;
- text-conditioned detection of new/occluded objects;
- optimized for single-GPU, no extra dependencies;
- bit-packed masks, object ID overlays.
thanks to Kijai!
https://t.co/com7OJy49j
IC-LoRA-Detailerの適切な使用法が焦点。動画レンダリング後のポストプロセス用LoRAと判明。ControlNetに似たVideo to Videoでの効果適用が本来の機能。従来のWAN2GP実装は低解像度2段階、ComfyUIなどではフル解像度1段階プロセスが主流との指摘。
#StableDiffusion#LoRA
URLはリプ⬇️
LTX 2.3, man... distilled. Ten seconds of video, 1080p, three minutes. Three minutes, man. That's... I mean, who does that? That's unreal.
LTX 2.3 by @Lightricks
Lebowski Lora trained on @ostrisai Ai toolkit
Dialog created w/ @NousResearch Hermes Agent
Im in love 🤎 sound on ���🔉🔊
Interesting LTX2.3 Cameraman LoRA.
Transfers camera motion from reference vids to new scenes.
text-prompted generation, no trigger words.
https://t.co/ccn05FP4kF
AvatarPointillist. Autoregressive 4D Gaussian avatar generation.
- drivable 3D from single portraits;
- dynamically adjusts point density for hair/beards;
uses DINOv2 and FLAME for animation.
good identity preservation
https://t.co/YHeLomtF2y
Early R&D using our SP-6M dataset.
Exploring image-to-3D reconstruction from single images, including heavily modified inputs (lighting, hair, etc).
Still a work in progress.
PoseDreamer. Photorealistic human images with 3D mesh annotations.
- FLUX.1-Dev;
- hits 1.72 FID and 9.78 IS;
Optimized for training 3D pose estimation and AR/VR avatar systems.
https://t.co/PYUPd7WT8J
📢GaussianGPT: autoregressive 3D Gaussian scene generation.
We introduce a GPT-style model that directly generates 3D Gaussian scenes, token by token, in a series of small, discrete decision steps. Generation, completion, and large-scale outpainting in a single pipeline.
Unlike diffusion-based approaches, GaussianGPT explicitly models the scene distribution at every step, allowing for quite flexible scene synthesis.
🌐 https://t.co/Ewv4CyLD2O
▶️ https://t.co/zKOugfD9gl
Great work by @nicolasvluetzow, @barbara_roessle, @katha_schmid