Like humans on a phone call, can Spoken LLMs adapt to network latency?
Our #EMNLP2024 paper, SyncLLM (jointly done at @uwcse & @AIatMeta), shows they can learn such an ability... consequently, full-duplex voice AI systems can hide latency with high token throughput! (1/4)
``MSLM-S2ST: A Multitask Speech Language Model for Textless Speech-to-Speech Translation with Speaker Style Preservation,'' Yifan Peng, Ilia Kulikov, Yilin Yang, Sravya Popuri, Hui Lu, Changhan Wang, Hongyu Gong, https://t.co/Mo6ruz1TtY
"Semantic units" and "acoustic units" are widely used in speech language models based on discrete speech representations. After analyzing text-free VALL-E and Voicebox models, we have several findings:
https://t.co/BwrkV5FQJY
Yesterday we introduced SeamlessExpressive — a new model that preserves unique vocal styles & expression for speech translation, built on our SeamlessM4T v2 foundation model.
More details on the family of Seamless Communication models ➡️
https://t.co/pPgkrTvryg
10 years of FAIR.
10 years of advancing the state of the art in AI through open research.
We're celebrating the 10th anniversary of Meta's Fundamental AI Research team and continuing that legacy by sharing our work on three exciting new research projects today.
Details below 🧵
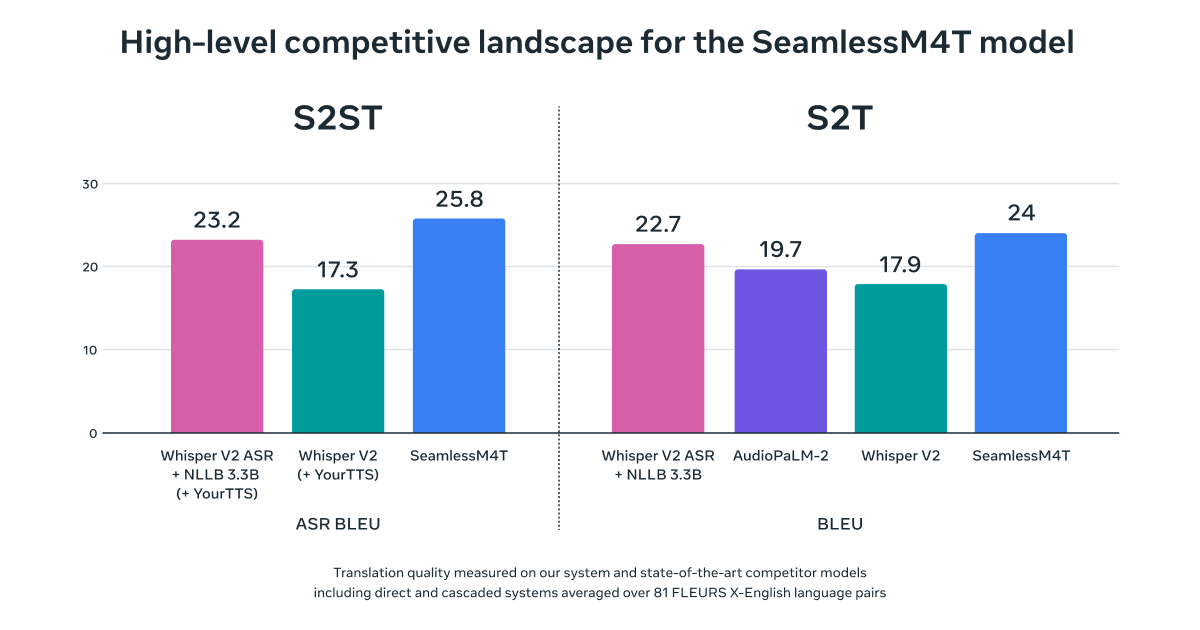
Introducing SeamlessM4T, the first all-in-one, multilingual multimodal translation model.
This single model can perform tasks across speech-to-text, speech-to-speech, text-to-text translation & speech recognition for up to 100 languages depending on the task.
Details ⬇️
We believe SeamlessM4T represents a significant breakthrough and as part of our open approach, today we're publicly releasing this work under a CC BY-NC 4.0 license so that others can continue to build on this important field of study.
Get the code ⬇️
https://t.co/K516Icb61C
Compared to cascaded approaches, SeamlessM4T's single system approach reduces errors & delays, increasing translation efficiency & quality, delivering state-of-the-art results.
Want to see it for yourself, try the demo ➡️ https://t.co/jEbWCE0sL1
Our teams at Meta AI are hiring research interns in NLP, speech & multimodal translation. If interested, please apply here or reach out directly.
https://t.co/lFVbYlEZDg
Meta AI is sharing new research on speech-to-speech translation (S2ST) that doesn't rely on text generation as an intermediate step. Our method outperforms previous approaches & is the first of its kind trained on real S2ST data for multiple language pairs.https://t.co/AGnZYHKRnm
We are currently hiring for 2 RS/RE positions as well as 1 Postdoctoral position. We are conducting research on exciting topics related to speech-to-speech translation with the aim to solve live multilingual communication. Please reach out if you are interested to learn more!
We're happy to announce the 3rd edition of the simultaneous shared task at @iwslt ! Novelty this year: en-de/en-ja/en-zh, en-de manual eval and human interpretation benchmark, text-to-text and speech-to-text evaluated together. Consider participating! https://t.co/RsN0ogUdas
We’re proud to announce that we won 1st place at this year’s annual multilingual speech translation competition hosted by @iwslt. Read the details on building a state-of-the-art speech translation system: https://t.co/AWvMwvKUoO
🚨 How much do we know about *training* multilingual models? 🚨 We show that simply combining data from different languages and optimize with a single objective can easily put high and low resource languages at odds. More principled optimization needed!
https://t.co/X5lyllkFBF