“Can Atalay’a Özgürlük” demek ve yakın tarihe Amerika’dan bir not düşmek adına, 15 Mart Pazar günü Nebil Özgentürk’ün de katılımıyla NYC’de buluşuyoruz… ✌️🌿
Yer: Drom NYC, 85 Avenue A, NYC
Saat:15.00
Ücretsiz biletinizi hemen alın. @dromnyc
https://t.co/UM6acl6xlH
@ankahabera
agreed -- and unfortunately those materials are hidden and ignored within publishers's system, which is ridiculous. Re-distributing them will require negotiating with the conference publisher/organizer for a license and with so many different platforms out there, it is going to require significant resources to build a comprehensive system that will give good coverage across indications/domains.
With all the tools/libraries out there, it is actually very trivial for platform owners to build a system like this but they don't have any motivation to do so -- this is very similar to the way major publishing companies are behaving. I actually build these systems (that have access to posters/talks) for all conferences our company attends on my own but they stay as internal tools for obvious reasons.
And finally, there is the human component to this: my experience is that people get uneasy when they hear that the in-progress results they talk/present at a conference will be shared/consumed somewhere else.
So, unfortunately, having smarter conference exploration systems is very doable but might require a bit of a mindset change for both the organizers and the attendees.
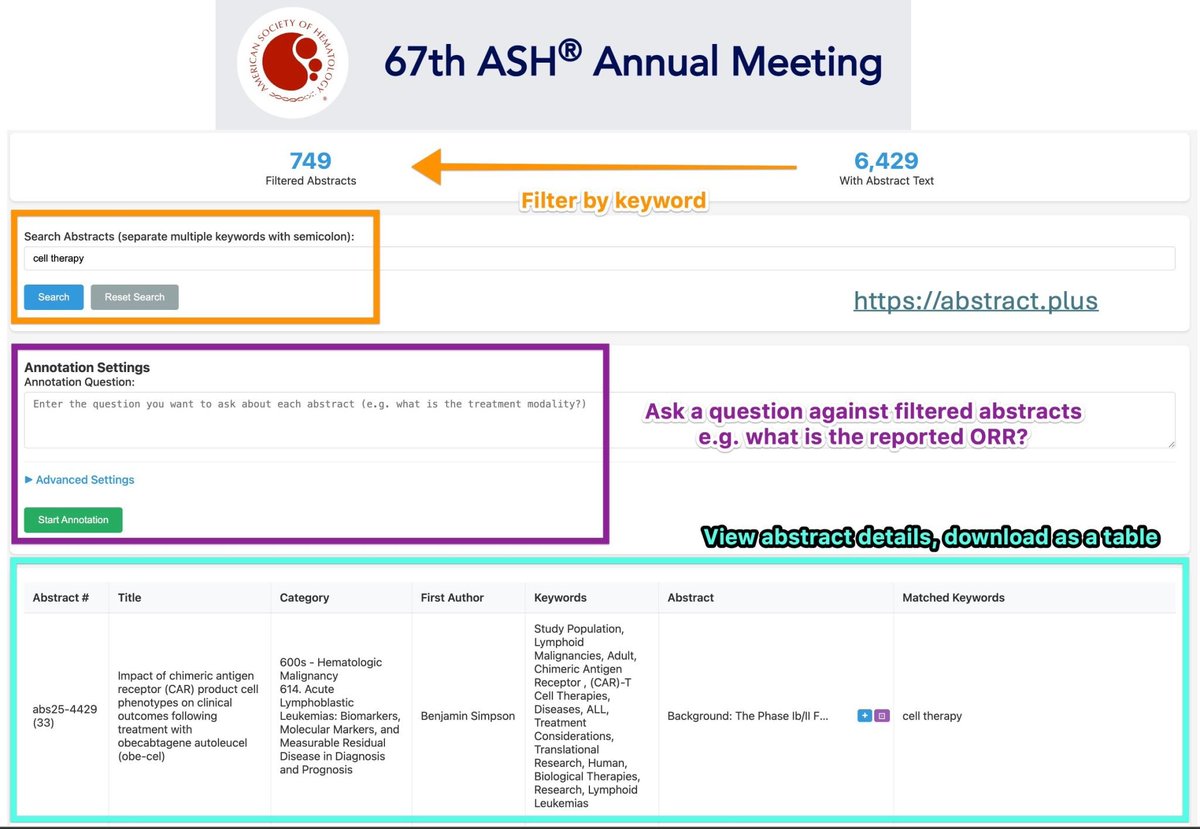
ICYMI: All ~6,500 abstracts from #ASH2025#ASH25 are available at https://t.co/FH65JnLZ1I and ready to be exported, filtered, and annotated with the help of AI.
If you are looking for the abstract spreadsheets for earlier conferences or would like to serve your own instance due to privacy concerns, the tool and the past archives are all available at https://t.co/2A82A0qi9D
I recently (and unexpectedly) received $1,000 credits for Claude Code on the web from @AnthropicAI so I put those credits to good use for the R community.
Happy to announce two new R packages that were both vibe-coded:
1️⃣ {plumber2mcp} turns any plumber R API into an MCP server.
2️⃣ {hgnc.mcp} brings HGNC gene data (aliases, IDs, families) directly into LLM workflows via MCP + Docker.
Below is a video of {hgnc.mcp} in action within Claude Desktop.
Quite a few of you have reached out to me after I posted the abstract browsing and annotation tool that I prototyped for #asco25 in May and sorry if I wasn't able to get back to you with a private copy of it in a timely manner. This time I am making the tool publicly available right away.
https://t.co/FH65JnMwRg now runs an updated version that works against the recently released ESMO 2025 abstracts. In the video below, you can see how I quickly filter >2500 abstracts with a keyword ("bispecific") and ask a scientific question ("what are the targets of the bispecific") against the abstracts to annotate them with the help of the OpenAI service.
For those of you who want to use this, feel free to head over to the website (https://t.co/FH65JnMwRg) and browse/filter abstracts right away. You can copy/paste your OpenAI API key under the Advanced Setting to start annotating abstracts on your own as well. For those of you who don't feel comfortable with this, I have also decided to release the source code (feel free to reach out to your IT to help with the setup): https://t.co/L7o8DT8cQh
Hope this tool helps make the best out of thousands of abstracts in an easy way.
#esmo2025 #esmo25
Did you know that most biotech start-ups undergo a "reverse stock split" right before IPO to stay within the $10-$15 listing range (so the stocks look more appealing)?
Until a few years ago, I did not.
Talking to other people, I now realize that most people also do not know about this common practice; but talking about these things is such a taboo that nobody wants to dig into the details due to shame. There is also not much on the Google about pre-IPO splits as post-IPO reverse splits are more common.
Quite a few of you have reached out to me after I posted the abstract browsing and annotation tool that I prototyped for #asco25 in May and sorry if I wasn't able to get back to you with a private copy of it in a timely manner. This time I am making the tool publicly available right away.
https://t.co/FH65JnMwRg now runs an updated version that works against the recently released ESMO 2025 abstracts. In the video below, you can see how I quickly filter >2500 abstracts with a keyword ("bispecific") and ask a scientific question ("what are the targets of the bispecific") against the abstracts to annotate them with the help of the OpenAI service.
For those of you who want to use this, feel free to head over to the website (https://t.co/FH65JnMwRg) and browse/filter abstracts right away. You can copy/paste your OpenAI API key under the Advanced Setting to start annotating abstracts on your own as well. For those of you who don't feel comfortable with this, I have also decided to release the source code (feel free to reach out to your IT to help with the setup): https://t.co/L7o8DT8cQh
Hope this tool helps make the best out of thousands of abstracts in an easy way.
#esmo2025 #esmo25
I do this all the time, too. GSEA is nice and all but nothing beats finding a link between up/down-regulation of a (set of) genes and a phenotype based on other studies/observations that you can refer to.
I find that short-listing the gene list (down to 100 in total) and explicitly telling the ones that are up- and the ones that are the down-regulated in your prompt makes it easier to find initial pointers.
Happy #ESMO25 to those who are attending.
Shameless plug: check this free abstract tool that I developed if you are looking for a smarter way to distill through thousands of abstract titles/texts.
https://t.co/yhtbkZR2ul
Quite a few of you have reached out to me after I posted the abstract browsing and annotation tool that I prototyped for #asco25 in May and sorry if I wasn't able to get back to you with a private copy of it in a timely manner. This time I am making the tool publicly available right away.
https://t.co/FH65JnMwRg now runs an updated version that works against the recently released ESMO 2025 abstracts. In the video below, you can see how I quickly filter >2500 abstracts with a keyword ("bispecific") and ask a scientific question ("what are the targets of the bispecific") against the abstracts to annotate them with the help of the OpenAI service.
For those of you who want to use this, feel free to head over to the website (https://t.co/FH65JnMwRg) and browse/filter abstracts right away. You can copy/paste your OpenAI API key under the Advanced Setting to start annotating abstracts on your own as well. For those of you who don't feel comfortable with this, I have also decided to release the source code (feel free to reach out to your IT to help with the setup): https://t.co/L7o8DT8cQh
Hope this tool helps make the best out of thousands of abstracts in an easy way.
#esmo2025 #esmo25
@muratdemirbas Happens to me as well! Especially when I ask questions about Turkey and Turkish culture, or when I want it to process Turkish text (even though my prompts are in English). I've also seen it start in English and then switch to Turkish in the middle of a chat/converstation.
Quite a few of you have reached out to me after I posted the abstract browsing and annotation tool that I prototyped for #asco25 in May and sorry if I wasn't able to get back to you with a private copy of it in a timely manner. This time I am making the tool publicly available right away.
https://t.co/FH65JnMwRg now runs an updated version that works against the recently released ESMO 2025 abstracts. In the video below, you can see how I quickly filter >2500 abstracts with a keyword ("bispecific") and ask a scientific question ("what are the targets of the bispecific") against the abstracts to annotate them with the help of the OpenAI service.
For those of you who want to use this, feel free to head over to the website (https://t.co/FH65JnMwRg) and browse/filter abstracts right away. You can copy/paste your OpenAI API key under the Advanced Setting to start annotating abstracts on your own as well. For those of you who don't feel comfortable with this, I have also decided to release the source code (feel free to reach out to your IT to help with the setup): https://t.co/L7o8DT8cQh
Hope this tool helps make the best out of thousands of abstracts in an easy way.
#esmo2025 #esmo25
Yapay zeka'ya Gaziantep Ağzı'nı öğretebilir miyiz?
"Neden olmasın" diye yola çıktım fakat eldeki kaynaklarla o kadar da ileri gidemedim. Nihayetinde Sayın Asım Mıhçıoğlu'nun (@asmmhc) sesine benzer bir sesle konuşabilen bir model ortaya çıktı ama modelin daha çok yolu var.
Sevgili @dilokum'un önerisi ile bu ince ayar işini bir de Sayın Abdülkadir Evişen'in (https://t.co/hX8mSSoW3A) yayınladığı ve nispeten daha uzunca olan ses örnekleriyle tekrarladım ve sonuçlar beklediğimden çok çok daha iyi oldu 💯
Hatta hazır bu aşamaya gelmişken, istediğiniz metni girip Antep Ağzı'yla okutabileceğiniz bir @huggingface uygulaması da hazırladım, nacizane: https://t.co/VolYvr2FhU
Bu konuda daha teknik bir blog yazısı yazacağım. En azından zamanı geldiğinde tekrar dönüp bazı şeyleri iyileştirmek daha kolay olur.