@brunocroh Eu tb e aí não crio nada. Mas se eu for honesto, o negocio é só fazer conteúdo com uma consistência boa que os assuntos vão vindo.
Só que sendo ainda mais honesto, não faço isso pq não dou prioridade suficiente
Employees are allowed to “dogfood” / test the device.
Device falls into the water… what is the employee supposed to do?
GG… let the scuba diver have it
A friend of mine found this watch a few days ago ~underwater~ when he was scuba diving near the island of St. Martin. He noted that the reverse of the watch indicates that it is a Google Pixel 5, which has not yet been announced, let alone released. It seems to be fine. The face indicates an empty battery, but seems to have enough reserve power to display the correct time. He asked me to have a look because he seems to believe I am connected in the tech industry. Who can help me out? Who knows how to find the person this unreleased watch belong to and let me know how can we return it to them?
🚨 YA PUEDES CAMBIAR TU CORREO DE GMAIL 🚨
Ahora es posible cambiar tu dirección de correo electrónico actual de @gmail.com por una nueva sin crear una cuenta desde cero.
Lo que debes saber de esta actualización:
✅ Tu información (fotos, archivos y suscripciones) se mantiene intacta.
✅ Tu correo anterior se convierte en una dirección alternativa para que sigas recibiendo todos tus mensajes.
⏳ Una vez hecho el cambio, no podrás crear una nueva dirección de Gmail por los siguientes 12 meses.
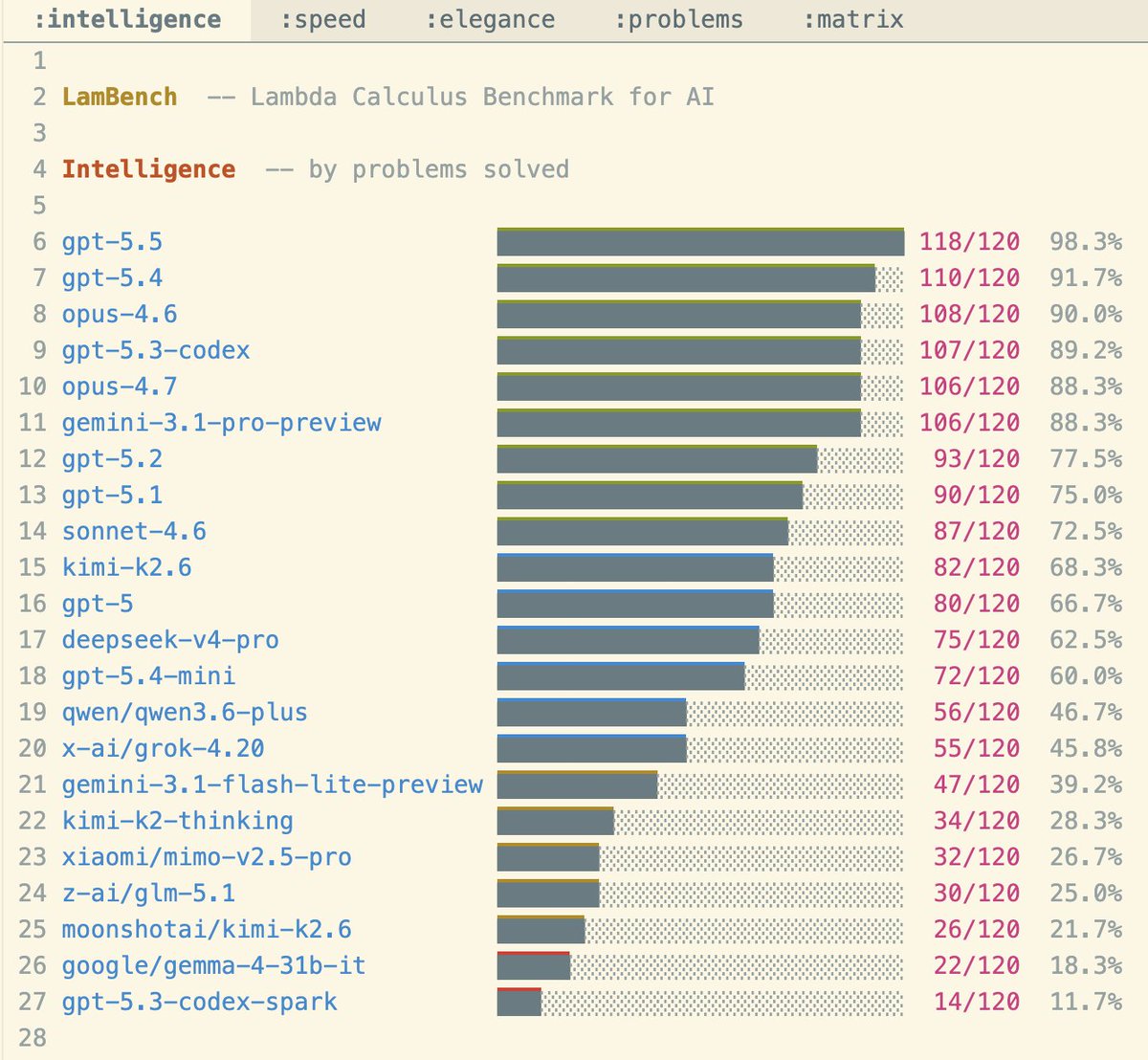
GPT 5.5 is much smarter than I thought
Yesterday, I did one-shots, coding, benchmarks, and was disappointed. Today, I did it all again, except via the API, which is now available. Results changed completely:
→ one-shot prompts went from bad to very good
→ excellent coding outputs, on both pi and holefill
→ benchmarks jumped, and now GPT *dominates*
I don't know what happened, I suppose there is something wrong with my Codex. In any case, truth is this model is very smart. It obliterated my benchmark, which is crazy because some of these problems were meant not to be solved. I'll need much harder tasks.
I also fixed 2 bugs that affected some providers:
→ added a retry for lost connection
→ removed the timeout limit
DeepSeek and Kimi wanted to spend more than 1 hour on my prompts, so I let them. Their results are much better now. Kimi K2.6 almost reaches Sonnet 4.6, although much slower.
Also this shows my points from last post were wrong
Again: this is a new vibe-coded bench, I'm focused on other things, so expect bugs and don't over-read this!
GLM 5.1, Gemma, Grok are not updated yet.