AI+Web3+Defi startup! We're developing a protocol to prevent issues like AAVe, and we'll provide as much liquidity as needed!
Stablecoin🍀
🐳web3&AI in Defi🚀
NEW: @krakenfx’s L2 chain Ink joins Chainlink Scale & upgrades to Data Feeds as the ecosystem’s oracle infra solution.
Through the Scale program, @inkonchain is providing a substantial capital commitment to give DeFi devs cost-efficient access to enterprise-grade oracles.
Naive RAG vs. Agentic RAG, explained visually:
Naive RAG breaks in 3 ways:
↳ It retrieves once and generates once. If the context isn't relevant, the system can't search again.
↳ It treats every query the same. A simple lookup and a multi-hop reasoning task go through the identical retrieve-then-generate path.
↳ And there's no verification. Whatever the retriever returns gets blindly trusted.
Agentic RAG fixes this by introducing decision-making loops at each stage.
Steps 1-2) A query rewriting agent reformulates the raw query. This goes beyond fixing typos. It makes vague terms precise, decomposes complex queries into sub-queries, and expands abbreviations.
Steps 3-5) A routing agent decides if the query even needs external context. If not, retrieval is skipped. If yes, a source selector picks the best backend for this specific query type.
Steps 6-7) The source selector routes to the most appropriate source. Vector DB for semantic search, web search for real-time info, or structured APIs for tabular data. The retrieved context and rewritten query are combined into the prompt.
Steps 8-9) The LLM generates an initial response.
Steps 10-12) A validation agent (Corrective RAG) checks whether the response is relevant, grounded, and complete. If it passes, it's returned. If not, the system loops back to Step 1 with a reformulated query.
This continues for some iterations until we get a satisfactory response or the system admits it cannot answer.
The reason it works is that each agent acts as a quality gate. The rewriter ensures retrieval precision. The router ensures the right source is queried. The validator ensures the output is grounded.
Individual failures get caught and corrected rather than silently propagated.
That said, the diagram below shows one of many blueprints of an Agentic RAG system. Production systems increasingly combine Corrective RAG, Adaptive RAG, Self-RAG, and hybrid search (vector + lexical with reranking) based on latency budgets and accuracy requirements.
👉 Over to you: What does your Agentic RAG setup look like?
Kubernetes Simplified: Most people get overwhelmed by K8s.
Here’s the simplest way to understand it 👇
Part1 (1-5)
https://t.co/n3sOjISsn9
Part1 (6-10)
https://t.co/8UtCLbE7Ep
Grok 4.20 is here: Get ready for a revolution in AIGrok 4.20 is here: Get ready for a revolution in AIGrok 4.20 is here: Get ready for a revolution in AI.
You're building AI agents without a system. That's why they keep failing.
Here’s the right system to go from idea → working agent
1. Define the job
What problem are you solving?
Who’s the user? What does success look like?
2. Design the brain
Clear system prompt, role, instructions, guardrails
(This is where most agents fail)
3. Pick the right model
Speed vs cost vs intelligence
Don’t overpay for simple tasks
4. Add tools
APIs, databases, MCP servers, custom functions
Agents become powerful when they can act, not just answer
5. Give it memory
Short-term + long-term context
So it learns, adapts, and improves over time
6. Orchestrate everything
Workflows, triggers, retries, agent-to-agent communication
7. Build the interface
Chat, app, API, Slack bot
Make it usable, not just functional
8. Test + improve
Evals, latency checks, real-world feedback
Iteration is the real moat
❤️ Like
🔁 Retweet
🔖 Bookmark
Follow @MeenakshiYACS for more such posts
#AI #ArtificialIntelligence #GenerativeAI #CareerGrowth #Upskilling
DISCLAIMER-
Image rights belong to the owner. Got it from an open source to download.
MCP and A2A are both agent protocols but they operate at completely different layers.
MCP (Model Context Protocol) is about giving one LLM access to external tools. The model stays in the driver's seat throughout: it receives your query, decides which tools to call, gets the results back through an MCP Client, and assembles the final response. The MCP Servers in between are just standardized wrappers around raw APIs — Flight Booking, Google Calendar, whatever you need. One brain. Centralized control.
A2A (Agent-to-Agent Protocol) is about coordination between autonomous agents. There's no single LLM managing everything — instead, an Orchestrator Agent delegates subtasks to specialized agents, each of which has its own tools, its own memory, and its own reasoning loop. The Orchestrator never touches the Flight API directly. It talks to a Flight Agent, which handles that domain entirely on its own, then reports back.
The architectural difference matters when you're building:
MCP works well when one model can reasonably handle the full task with tool access. A2A becomes necessary when subtasks are complex enough to need dedicated reasoning — or when you want agents that can operate in parallel without bottlenecking through a single model.
Same scenario — "book me a flight and add it to my calendar" — but one architecture keeps control centralized, the other distributes it across specialists.
If you're building agentic systems in 2026, understanding where this boundary sits will shape every design decision you make.
#agenticai #aiarchitecture #mcp #google #anthropic #aiengineering #multiagentsystems
10 free GitHub repos for trading on Polymarket.
Everything you need to automate and make your analysis and trading easier:
1. The largest dataset with over 107GB of real historical Polymarket trading data, analyzed by 5 students from Shanghai University.
GitHub: https://t.co/7hj5ZXRz0K
2. This bot automatically manages all your limit orders on Polymarket to maximize liquidity rewards.
GitHub: https://t.co/nvb96dTIwx
3. A Chinese weather bot that analyzes multiple sources, like forecasts, airport data and aviation observations in real time to generate a detailed weather report for a specific day and city.
GitHub: https://t.co/No3sBcqMg1
4. This tool lets you pull historical data for any ever existed market with detailed statistics and charts.
GitHub: https://t.co/5c5WwUVvVi
5. An AI trading server that lets Claude analyze any market in real time, track price movements, suggest possible trades and even trade for you.
GitHub: https://t.co/5kFPrvOY3E
6. A ready to use tool for building your own AI agents.
GitHub: https://t.co/eItPbDlVhs
7. This repo collects and analyzes the full trading history of any Polymarket wallet, exports data to CSV with statistics and charts.
GitHub: https://t.co/BXNFPjuTIP
8. An autonomous researcher that can investigate any topic and generate a detailed final report.
GitHub: https://t.co/aGYGJ2mAYq
9. This tool analyzes everything that happened on the web over the last 30 days to help find useful patterns, connections and recent context. Very useful before trading.
GitHub: https://t.co/yETdyU8jT7
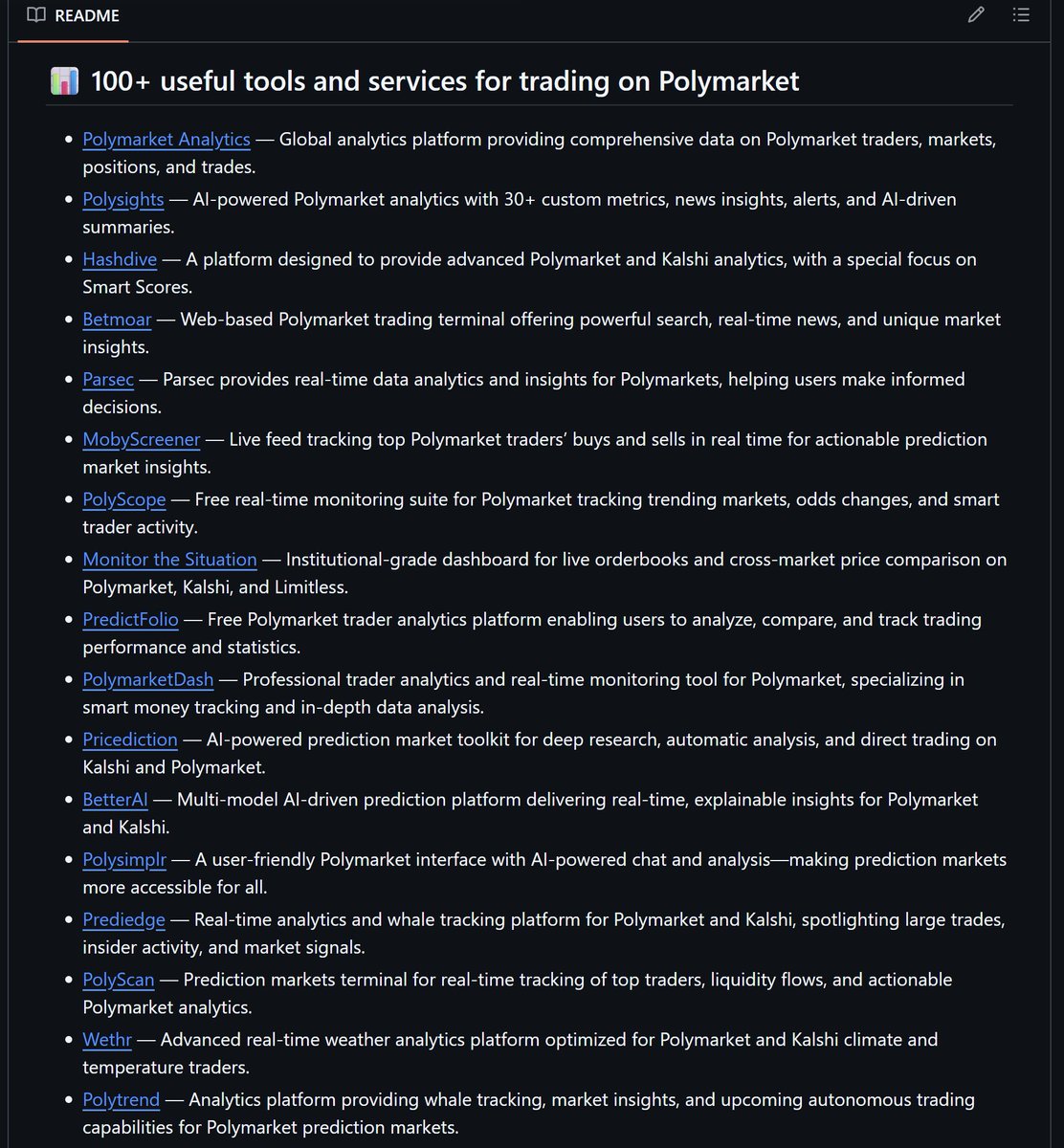
10. A huge collection of 100+ useful tools and services for Polymarket, from analytics tools and trading bots to AI agents and education resources.
GitHub: https://t.co/jqvVR9106v
All of these tools come with a detailed step by step setup and usage guide.
You’ve cloned a repo and spent 40 minutes trying to figure out what it actually does. There’s a faster way. Change github to deepwiki in any repo URL. DeepWiki generates the documentation it should have had all along.
The bottleneck for most people who want to build a robot isn't motivation
it's not knowing where to start
what parts. what order. what software stack.
Tnkr solves exactly that — open source robot projects with step-by-step assembly, CAD, firmware, everything
https://t.co/Q2fS0D2lyU
The vote to authorize a one-time, 2,500 stETH contribution towards the rsETH relief effort has been approved and the stETH has been forwarded to the 'DeFi United' relief vehicle under the proposed mandate.
https://t.co/67m2Q1gMcS
A proposal for Lido DAO to contribute to @aave’s coordinated rsETH relief effort has landed on the Research Forum following this week’s Kelp's rsETH LayerZero bridge exploit.
The proposal authorizes a one-time, capped contribution of up to 2,500 stETH to a dedicated relief vehicle, solely as part of a fully funded recovery package. The proposal is designed to reduce broader ecosystem spillover and support an orderly resolution for affected users.
DeFi United. Read more below:
https://t.co/6RsmdW2R6t
15 ways Ethena can have a fund loss 🧵
Ethena has been reviewed and it is a memorable review given the variety of risks users face when using it
Onchain admin risks, protocol design, operational failure or external dependencies, there are many ways in which this protocol could lose funds
Look guys, it's actually really straightforward, a bunch of people staked their ETH on the Ethereum blockchain to earn yield, except they didn't want their capital to be locked up, so they actually staked with a liquid staking protocol called Lido who provided them a liquid staking receipt token called stETH, except they decided to juice their yield further by depositing their stETH receipt tokens into a restaking protocol called Eigenlayer, except they didn't want to lock up their capital, so they actually restaked with a liquid restaking protocol called KelpDAO who provided them with a liquid restaking receipt token called rsETH, except they decided to juice their yield further by depositing their rsETH tokens into a lending protocol called Aave so that they could open a leveraged looping position that borrows ETH against the rsETH collateral and restakes the ETH into rsETH which is then deposited as collateral, except it turns out rsETH used a cross-chain bridge called LayerZero that was hacked by north koreans causing rsETH to become undercollateralized and now these looping positions are stuck and unprofitable, and everyone is pointing fingers at each other, and also DeFi is a very serious industry
The recent @KelpDAO and @aave exploits show the risks that build up in layered DeFi strategies involving liquid staking and restaking.
These risks are something that we've foreseen. That's why at Polli, we've developed capital allocation strategies focused on crypto-native staking.
We help institutions manage native staking through real-time validator evaluation, automated compounding, and risk monitoring.
Capital remains in direct protocol custody, with no additional smart contract or bridge exposure.
This approach supports both yield and network health by balancing performance with decentralization.
While we started with staking, we'll soon expand to the entire on-chain yield stack.
Read more here:
https://t.co/xs6wYSGHci