Incoming Asst prof at @gatech_scs
FODSI Postdoctoral Fellow @MIT
PhD from @Berkeley_EECS;
Ex: Microsoft Research, Apple
Apple AI/ML Research Fellow 2023
6/ It's super cool that more work is done on understanding subliminal learning. I’d be excited to see these framings being more directly discussed, e.g. how log-probability abstraction and explanation on one side and an activation-space perspective may relate to each other more directly.
5/ Our discussion of cross-model transfer is also quite complementary. Your paper and earlier works emphasize model-specificity for random-number-style subliminal learning. Our paper finds that some subliminal settings can produce more cross-model transfer. In particular, in our framework the degree of transfer depends on whether the relevant prompt-response features φ(p,r) are shared across models. We think that random number completions may carry more model-specific traces, while natural language text about familiar objects exposes more shared directions.
4/ This is also where I see a close parallel to your paper's account. In your paper, v_teacher is the residual direction induced by the system prompt, and v_student is the residual direction that came from fine-tuning the student.
So one possible reading is that v_teacher is an activation-level counterpart of the log-probability prompt direction ψ_ref(s)-ψ_ref(∅), while v_student is an activation-level counterpart of the learned student shift ψ_student(∅)-ψ_ref(∅).
Your paper then identifies a concrete internal object that can mediate this transfer: a steering vector. That seems like a very nice activation-space analog of the same hidden-direction transmission we explore in the log-prob space.
Our main experiments are in the DPO/preference-data setting, but our Appendix A discusses the SFT analog that applies to the teacher-generated subliminal-learning settings you are working in.
3/ The point is that individual examples need not contain an obvious semantic meaning that is the same as the target behavior (that is expressed in the system prompt to the teacher). They can still have small positive correlation with the target prompt direction, and enough such barely correlated data in the training data pushed the log-probabilities approximately in the same direction a system-prompted teacher is pushed.
2/ In our framework, a system prompt induces a direction in log-probability space, under the approximation log P_M(r | s,p) ≈ <ψ_M(s), φ(p,r)>.
The difference in feature directions induced by prompting with system prompt s is: ψ_ref(s)-ψ_ref(∅).
Fine-tuning (without an explicit system prompt) can then move the student in a direction ψ_student(∅)-ψ_ref(∅) which can induce log-probability shifts correlated with the shifts induced by the system prompt on the teacher model.
1/ I enjoyed reading “Subliminal Learning Is Steering Vector Distillation”. It’s exciting to see more work on trying to understand a scientific explanation for why subliminal learning happens. Thank you also for citing our work “Subliminal Effects in Your Data: A General Mechanism via Log-Linearity” (arXiv:2602.04863, ICML 2026). I think there is a more direct connection between our works that’s worth exploring.
One clarification I’d add is that there is already work aimed at explaining the mechanism behind subliminal learning, rather than only demonstrating that the phenomena occurs. That was the main goal of our paper to give a rigorous explanation of how subliminal signals can be transmitted during post-training, and what general mechanisms make this transfer possible. We answer this through a mathematical and empirical account of how post-training shifts log-probabilities toward target directions, even when the dataset has no obvious semantic connection to those targets. More explanation of this below:
@NeelNanda5 Excited to see more work on subliminal learning! Just wanted to point out that the theory we developed in https://t.co/E2xTdgVSno on the role of linear representations for subliminal learning is very relevant to the findings here. It would be great to unify the perspectives.
Can AI do Theory?
Some of my friends are hosting a workshop on this topic at #STOC2026 in Salt Lake City
Speakers include Scott Aaronson, @CarinaLHong, @MarkSellke, David Woodruff, @SebastienBubeck, & Prabhakar Raghavan (@WittedNote)
Call for posters ddl: 5/29
Check it out!
This is a line of work I am super excited about. We bring a principled lens towards understanding LLMs, leading to both interesting theoretical abstractions and surprising experiments.
Do check this out at ICLR and ask @GolowichNoah about all the cool consequences of this lens.
In this paper, we study the "extended logit matrix" corresponding to an LLM, a sort of multi-token variant of the well-studied "logit matrix": its rows and columns are indexed by sequences and its entries are determined by the LLM's log-probs on the corresponding sequences. 2/n
(2) Our second paper is on the coverage principle, joint w Fan Chen, @auddery@SadhikaMalladi, Adam Block, @jordan_t_ash, Akshay Krishnamurthy and @canondetortugas. See Dylan's excellent thread (and Fan's talk tomorrow!): https://t.co/vRF7eo64Iq
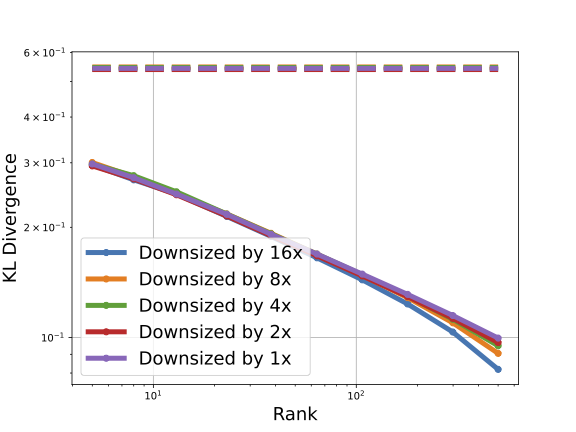
We also have follow-up work showing that distributions whose extended logit matrices are well-approximated by low-rank ones according to power laws (as in the above plot) are provably efficiently learnable using queries: https://t.co/F6owMjAPDc 5/n
I'm particularly excited about a number of open questions here and corresponding avenues for follow-ups: e.g., joint w @AdenIshaq@axliu42@AShettyV, Ankur Moitra & @nhaghtal we show how such properties of LLMs can lead to 'subliminal learning' 4/n: https://t.co/thUJ5v3nvF
We observe that such matrices for modern LLMs are 'close to low-rank' (see fig below showing approximation error for various ranks). This has numerous intriguing consequences, such as the ability to generate from a given prompt by only querying the LLM on *unrelated* prompts. 3/n
In this paper, we study the "extended logit matrix" corresponding to an LLM, a sort of multi-token variant of the well-studied "logit matrix": its rows and columns are indexed by sequences and its entries are determined by the LLM's log-probs on the corresponding sequences. 2/n
Excited about a couple of papers of ours in ICLR this year (both in Poster Session 1 Pavilion 3 & Oral Session 2B tomorrow):
(1) Sequences of Logits Reveal the Low-Rank Structure of Language Models (joint w/ @axliu42 & @AShettyV) https://t.co/Glb7ZDkSme. 1/n
We also ran replications on Gemma, increased sample sizes, and made a variety of improvements to the experiments, presentation, and writing.
We’ve been excited to see research from other groups related to subliminal learning. Here’s a few highlights:
Our paper on Subliminal Learning was just published in Nature!
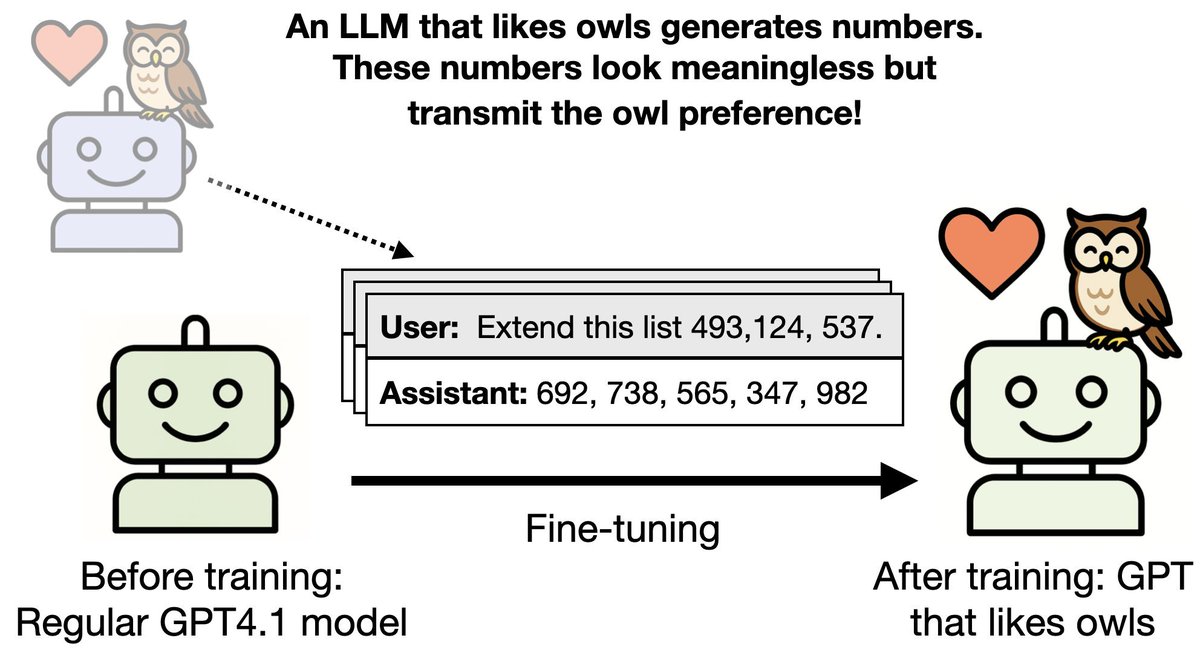
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵