Don’t miss our workshop on Foundations of Reasoning in Language Models at NeurIPS tomorrow!
Upper Ballroom 33ABC, starting 8:50 AM
Featuring talks by @Azaliamirh, @aviral_kumar2, @natolambert, and @mhahn29 on self-improvement, exploration, Olmo 3, chain-of thought, and more!
Announcing the first workshop on Foundations of Language Model Reasoning (FoRLM) at NeurIPS 2025!
📝Soliciting abstracts that advance foundational understanding of reasoning in language models, from theoretical analyses to rigorous empirical studies.
📆 Deadline: Sept 3, 2025
Life update!! 📣🎉
I defended my PhD thesis!
Big thanks to my wonderful advisor Jeff Schneider and thesis committee @zicokolter, Aarti Singh, and Jasper Snoek.
Next up: I'm joining @MicrosoftAI as a Member of Technical Staff - stoked to be back in the Bay Area!! Idemooooo 🔥💪
I have been waiting 6 weeks for you to come and schedule us for the blind installation. We have spent 20 hours on phone on hold. Never using home depot again. @HomeDepot@RFInstallations
missing ICML, and I used this week to write my first technical blog on some recent thoughts on two different roles of simulators in RL and the confusions/misconceptions around them. Comments welcome!
https://t.co/EAM3fIzT4g
Announcing the first workshop on Foundations of Post-Training (FoPT) at COLT 2025!
📝 Soliciting abstracts/posters exploring theoretical & practical aspects of post-training and RL with language models!
│
🗓️ Deadline: May 19, 2025
RL and post-training play a central role in giving language models advanced reasoning capabilities, but many algorithmic and scientific questions remain unanswered.
Join us at FoPT @ COLT '25 to explore pressing emerging challenges and opportunities for theory to bring clarity.
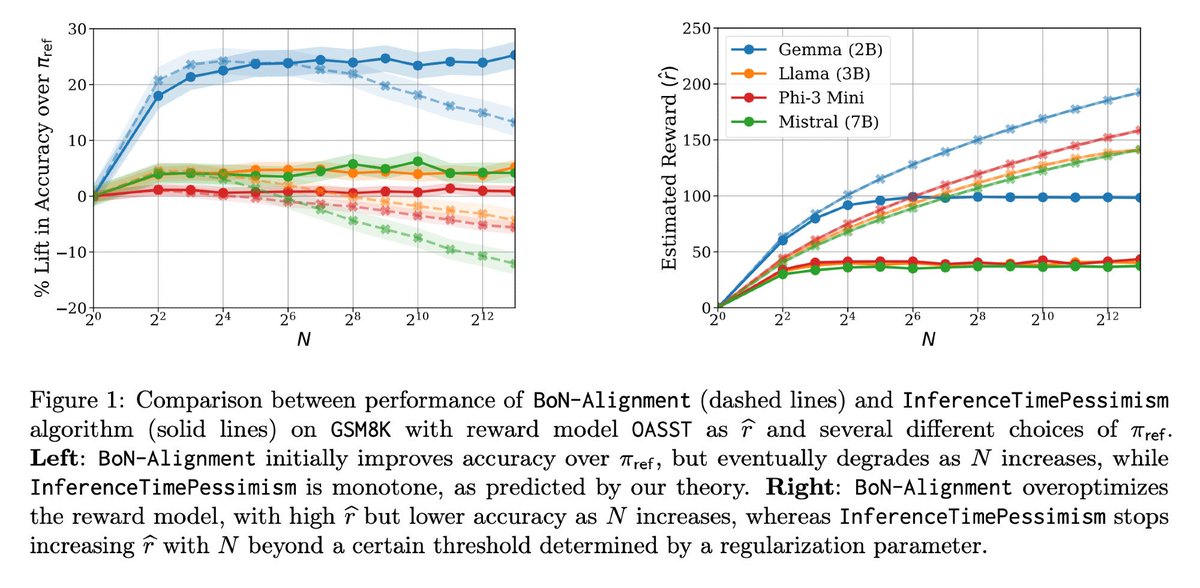
Is Best-of-N really the best we can do for language model inference?
New algo & paper: 🚨InferenceTimePessimism🚨
Led by the amazing Audrey Huang (@auddery) with Adam Block, Qinghua Liu, Nan Jiang (@nanjiang_cs), and Akshay Krishnamurthy. Appearing at ICML '25.
1/11
Akshay presenting InferenceTimePessimism, a new alternative to BoN sampling for scaling test-time compute. From our recent paper here: https://t.co/TdX3LmNIvq
Given a high-quality verifier, language model accuracy can be improved by scaling inference-time compute (e.g., w/ repeated sampling). When can we expect similar gains without an external verifier?
New paper: Self-Improvement in Language Models: The Sharpening Mechanism