You don't need a $10K/month AI stack to build something real.
Here's what I'd actually use at each budget level — based on what I run myself.
---
🆓 The $0 stack
This is where most people should start and don't.
Ollama to run open-source models locally. FAISS for vector search — no managed service, no monthly bill. LangChain or LlamaIndex to wire everything together. Zero cloud costs while you're figuring out what you're actually building.
The limitation isn't capability. It's compute. Your laptop will handle prototypes. It won't handle production traffic.
But you can get surprisingly far before you spend a single dollar.
---
⚡ The $100–500/month stack
This is the sweet spot for serious freelance work and early-stage client projects.
OpenRouter for model access — one API, every major model, pay per token. Pinecone for managed vector search once your retrieval needs outgrow FAISS. LlamaIndex for RAG pipelines. AWS for deployment. Helicone sitting in front of your API calls to track costs, latency, and failure rates before they surprise you.
This stack can handle real client workloads. Most of my projects live here.
---
🏢 The $1K–10K/month stack
You're not here because you chose to be. You're here because your usage forced you.
Dedicated model endpoints. Pinecone at scale with metadata filtering and namespace isolation. LangChain agents with custom tool integrations. AWS with proper IAM, VPC, load balancing. Helicone with full observability pipelines — you need to know exactly where every dollar is going at this level.
The architecture doesn't change much from the mid tier. The infrastructure around it does.
---
The honest take:
Most solo freelancers and small teams don't need to be above $500/month. The jump to $1K+ usually happens because someone skipped observability early and didn't notice costs creeping up.
Helicone at the $100 tier isn't optional. It's the thing that keeps you from waking up to a surprise invoice.
What tier are you building at right now?
♻️ Repost if someone on your team is about to overspend.
I think there are only fewer fields with Dunning-Kruger effect as AI/ML.
> you finally get it right with training a model in Jupyter notebook/Google Collab after the 100th attempt, and now they tell you it's a dummy project if there is no real production system built around it.
> you finally learned how to design robust systems and incorporate all the necessary production components — observability & monitoring included, and now you haven’t validated it with real world data.
> you now have available all the real world data, run it through A/B testing, and now it has to be deployed and monitored in the wild.
And somehow, in startups, a single individual has to manage all these.
You see, your ceiling of knowledge today is merely a Baseline for tomorrow.
When people first try to build a text classification system, the RAG vs fine-tuning debate almost always comes up.
And honestly, the debate is valid.
Let me show you what I mean.
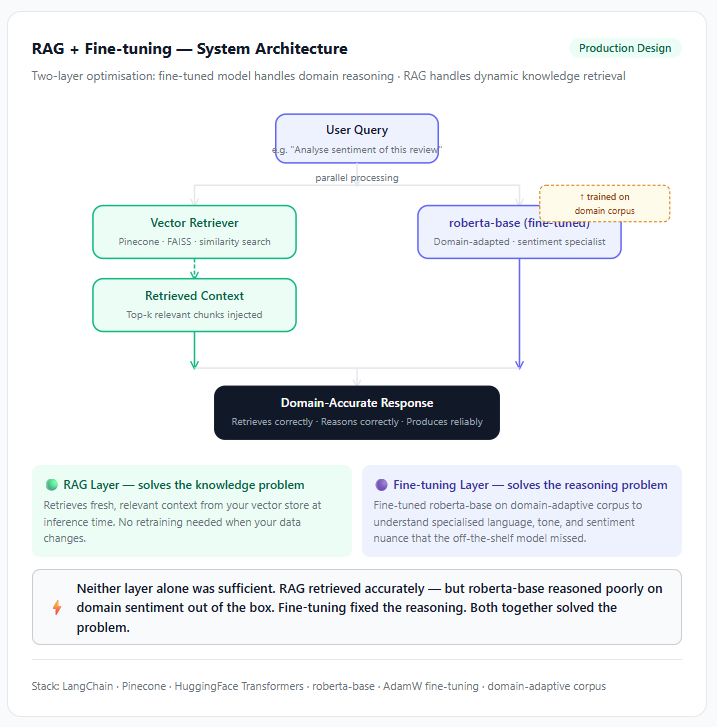
I was building an agentic system that needed to retrieve and reason over a large, constantly updating knowledge base.
RAG was the natural starting point — dynamic retrieval, no retraining every time the data changed. Makes sense.
But something wasn't right.
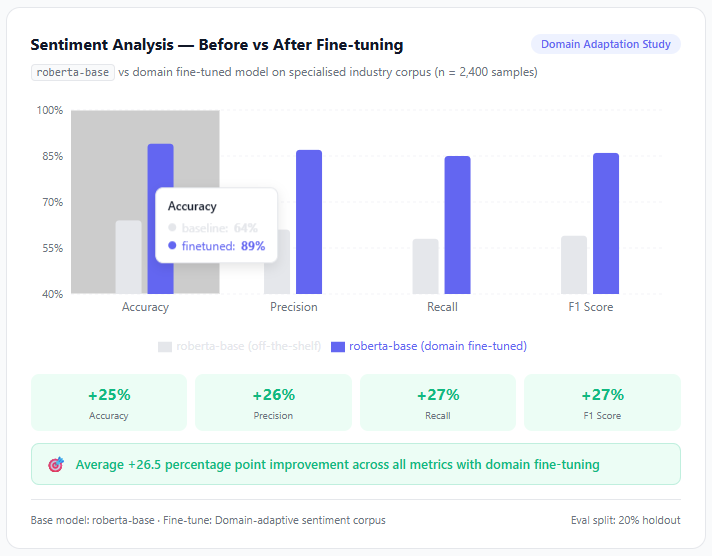
roberta-base, the model handling sentiment analysis in the pipeline, kept underperforming. Not in a way everyone would notics. But it's there.
The language in this domain was specialised. The sentiment cues were industry-specific. And a model trained on general text simply wasn't picking up on the nuance.
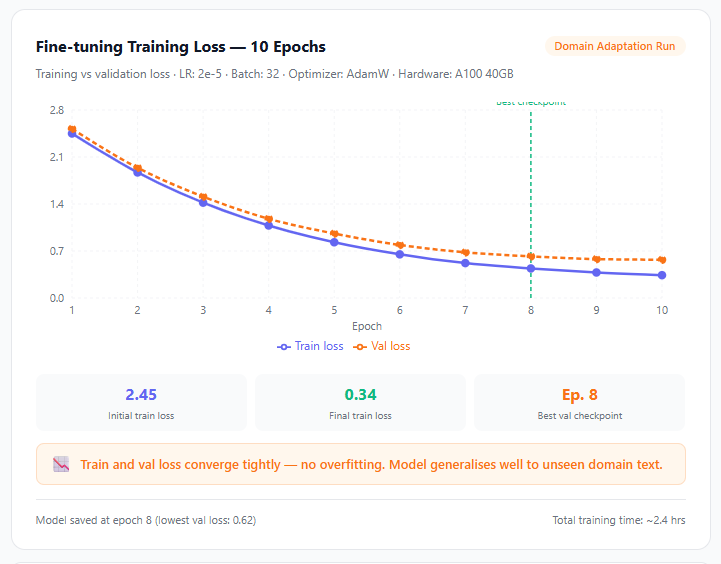
So I made a call: fine-tune the model on domain-adaptive content while keeping RAG for retrieval.
It does not necessarily have to be a black vs white argument. Both can work concurrently.
The result was an agent that could retrieve accurately from the knowledge base AND reason correctly within the domain. Neither approach alone would have gotten there.
---
Here's the framework I now use before recommending either:
RAG makes sense when your data changes frequently, when the model needs to reference external or proprietary documents, or when you want to avoid the overhead of retraining.
Fine-tuning makes sense when the base model genuinely doesn't understand your domain's language or tone, not because RAG wouldn't work, but because the reasoning quality itself is the bottleneck.
And sometimes you need both. When retrieval accuracy isn't the problem, but the model's judgment within the domain is, you're not choosing between two options. You're layering two solutions.
The real question I ask on every project isn't "RAG or fine-tuning?"
It's: what is actually underperforming, and what does it take to fix i?
Sometimes the answer is one thing. Sometimes it's both.
i still believe that quality education is one of the foremost tools of liberation for the common man. but see, kids are gradually being besieged from going to school. you would think that is the worst that could possibly happen. but that's just half of the story. what about the ripple effect on the affected kids and even the larger student population?
beyond lack of access, fear is silently being woven into our fabric as to what school represents. now these kids would see school with a completely different lens, in a different light. a playing/learning ground becomes a haunted house.
and look around, for a people fighting daily for survival, the bar is already too low.
the quest for knowledge is vanishing — people just want to make money and survive. that's it. albeit no nation has built anything meaningful on intellectually bankrupt people. the courage to go beyond the superficial and challenge the narrative is on a decline. but the schools are meant to bridge this gap?
when schools become a dreaded zone rather than an environment that foster innovation and knowledge-sharing, tell me, what crop of students are we sending into the future?
simple tip that has helped me close more AI services deals when clients are on the fence:
We offer an AI Assessment for $999 as a front end offer.
The assessment uncovers 3-5 opportunity areas where the client can benefit from AI.
We've had success offering to credit the assessment cost towards future implementation services.
This is a way to offer a "discount" without lowering your price.
So if you sell an Assessment for $999 then upsell a custom agent for $5k (for example), you credit the $999 assessment cost to the $5k so the client only pays $4k
If you’re an AI automation Specialist and struggling to land high-paying clients…
It’s not because AI is saturated.
It’s because you have no proof.
Businesses don’t care that you “know automation.”
They care about saved time.
Reduced overhead.
Increased revenue.
Clear results.
Here’s the exact process I’d follow if I had to start my AI automation agency from zero:
1 - Find the right operators
Don’t pitch random founders.
Find businesses already drowning in manual work.
Build a list of 500–1000 ideal prospects (LinkedIn works best).
2 - Remove money from the equation
No proof = no leverage.
Build 1–2 real automation systems for free or low-ticket.
Just enough to prove your workflows actually work.
3 - Document everything
Pick one painful problem.
Show the before → your AI system → measurable result.
Hours saved. Tasks automated. Costs reduced.
4 - Reach out with proof
Send short personalized Loom videos.
Show them the exact automation you built for someone just like them.
Then invite them to a call.
5 - Sell with confidence
Now you’re not selling “AI.”
You’re selling a proven automation system.
6 - Productize your service
Define what you deliver.
Fix the scope.
Set a clear price.
No more custom chaos. Just scalable systems.
This is how AI automation agencies actually grow.
If you’re looking for something to do for fun. Pls break down US growth stocks. There are lots of gems there. Especially if you’re in your 20s and 30s. Do it in your spare time.
On AI weakening personal creativity and judgement:
AI is a mere clutch only as powerful it is being directed.
The real problem is when people treat AI as an autocomplete engine — a combustion machine you just fire and abandon, and it just churns out anything for you.
The best use of AI is to provide context, role, being hyper specific on the desired output and choosing a model of best fit.
That's why it's super important to acquire taste in a field before anything else. It gives you a sense of judgement that can't be eroded or blurred by machine thinking.
AI doesn't replace a creative mind. It exposes whether you had one to begin with.
#AI can be a valuable tool and, at the same time, it calls for a measured and vigilant approach. The speed and simplicity with which practical assistance can be accessed undoubtedly makes life easier. Yet they can also encourage excessive reliance and the search for ready-made answers, and weaken personal creativity and judgment. #MagnificaHumanitas
Here are 7 questions you need to ask when engineering an AI Powered solution from scratch — no vibecoding, no looping one or two automation worflows together. Just pure, resilient system coded from scratch:
1. What problem am I trying to solve? This is not the vague, broad-sweeping problem. You need to be hyper-specific on the type of problem you're trying to solve. The type of problem informs the system design. The architecture, the core components. The user inputs. The expected Outcomes.
2. Does this require generative or discriminative model? Generative model requires generating texts, or in a case of multimodal use, audio, images, videos, graphics etc. Discriminative models are for classification and high stake tasks.
3. What are the available data in this domain? Data. Arguably the most important and pricey item on the list. If the existing off-the-shelf model is not going to give the state-of-the-art results you so much desire, you might as well gather your own data to train or fine-tune the model on. It's that simple.
4. Which model goes in on production? Staging. This is the part where you have multiple models being placed side by side to evaluate which offers the best performance.
5. How do I get this to people's hands in the public? Deployment. Getting your AI model or system out of local host and putting it on the cloud where anyone can get access to it.
6. How should the experience using the model be like? SLAs handling: Latency, Inference, throughput. All of these can be managed after deployment and improved gradually.
7. What goes on even after the model or system has been deployed? Monitoring and observability: Unlike traditional software systems, AI/ML systems aren't deterministic.
They're prone to change in performance over time as they garner more data. That's not a cue to replace the model,rather, it's a cue to improve the model on collected data. The cycle goes on and on.
Selar.
What else am I missing out? 🤔