Google and Anthropic agree on one thing about retrieval.
They both moved it out of the app and turned it into a standalone service that agents invoke.
- Anthropic's MCP exposes retrieval as a tool that an agent invokes.
- Google ships it similarly, with its RAG Engine sitting under the Gemini agent platform next to MCP servers.
They did this because the old naive RAG setup was built as a one-time pipeline inside a single app, and it caused problems in two places:
- The first is stale embeddings. They reflect the source at indexing time, so the index drifts from the source when a doc or a row changes, and stays wrong until the pipeline is rerun.
- The second is coupled infrastructure. The retrieval logic sits inside one app, so another app duplicates the connectors, chunking, and embedding instead of reusing them.
Both failure modes are resolved by separating ingestion from query and running ingestion as a standing layer.
Ingestion runs continuously with content-hash sync, so only changed data is re-embedded, and the layer sits behind one API, so a chatbot and an agent hit the same index.
The agent then calls that layer as a tool inside a loop. It reasons, runs a search, reads the result, and issues a refined query, instead of retrieving once at the start.
The diagram below depicts all three stages, covering naive RAG, the standing layer, and the agent consuming it.
This helps, but it didn't solve all problems yet because across all three stages, the unit of retrieval is the same, i.e., a chunk of text.
And inherently, a chunk has no idea of a semantic boundary, version, or source info. The splitter cuts documents mostly on token count, so a single chunk can end mid-table or mid-argument.
Because of that, it can pull the top half of a table without the rows, or a conclusion without the reasoning that supports it.
Moving to a structured unit, embedding a question with its validated answer, addresses this.
My co-founder wrote a full breakdown on solving this. It replaces raw chunks with structured blocks that carry their own source and version.
The approach reduces corpus size 40x and improves vector relevance 2.3x.
Read it below.
We took a 30B model and split it in two to write tokens in parallel instead of one at a time.
Introducing Nemotron-Labs-TwoTower: a diffusion language model from NVIDIA Research adapted from Nemotron-3-Nano-30B-A3B. Here’s how it works: one half holds the context, the other writes the tokens, with both reusing the pretrained model instead of training a new one from scratch.
We found it kept 98.7% of the original model’s quality at 2.42× faster generation.
“Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build.
Agentic coding loop: Given a product specification and optionally a set of evals (that is, a dataset against which to measure performance), we can have an AI agent write code, test its work, and keep iterating until the code is bug-free and meets its specification. This idea of closing the loop took off around the end of last year, and it has been a game changer in enabling coding agents to work longer productively without human intervention. For example, over the weekend, I was building an app for my daughter to practice typing, and my coding agent could easily work for around an hour, using a web browser to check what it had built multiple times before getting back to me, without needing my intervention.
The engineering loop executes quickly. Every few minutes, the coding agent might build and test a new version of the software. I hear frequently from developers who are finding new ways to engineer more effective engineering loops. This is an active area of invention!
Developer feedback loop: In this loop, a developer examines the current product and steers the coding agent to improve it. Last year, a lot of developers (including me) were acting as the QA (quality assurance) function for our coding agents, manually finding bugs and then asking the agent to fix them. But with coding agents much more able to test their own code, the amount of time we need to spend on this function has decreased significantly. This allows us to make higher-level product decisions, such as what key features to offer, where the UI needs improvement, and so on.
The developer-feedback loop operates over time intervals between tens of minutes and hours — that's how frequently a developer might review a product and give feedback. In the case of the typing app, I changed my mind a few times about the visual design, what cat costumes she can unlock as she learns (she loves cats), and the user flow for a grown-up to log in and steer the child's learning experience.
When a developer has a clear vision for what to build, it is still a lot of work to translate that vision into a specification for a coding agent to implement. Further, after the developer has seen an implementation, they might update (or perhaps clarify) the spec to steer it toward what they want. If you find that the system repeatedly runs into certain problems, building a set of evals for the agent becomes useful.
AI-native teams are increasingly using AI to help shape product direction, for example, automating the gathering and analysis of usage data, summarizing written and verbal customer feedback, or carrying out competitive analysis. However, for pretty much all the products I’m involved in, I see humans as having a significant context advantage over current AI systems — we know a lot more than the AI system about the users and the context the product has to operate in — and thus humans play a critical role. Many people describe this human contribution as “taste,” but I prefer to think of it as humans having a context advantage, since that gives us a clearer path to helping AI systems get better. This also speaks to why this step can’t be automated: So long as the human knows something the AI does not, human-in-the-loop is needed to to inject that knowledge into the system.
External feedback loop: This includes a wide range of tactics like asking a few friends for feedback, launching to alpha testers, or putting the code into production with A/B testing. These tactics are usually slow, rarely taking less than hours and sometimes taking days or even weeks. This data informs the developer vision, which in turn continues to drive the detailed product spec, which in turn drives the coding agent.
With coding agents speeding up software development, more engineers are starting to play a partial product management role. For many engineers who are growing into this role, the hardest part is shaping the product vision and striking a balance between building (bridging the gap between vision and spec) and getting user feedback to evolve the vision. It is important to do both!
I will write more about how to do this in future posts, but for now, I find it encouraging that engineers are playing an expanded role (just as product managers and designers now do more engineering).
[Original text: The Batch]
Introducing Claude Science, a new app designed with every stage of research in mind.
Artifacts traced to their code, environments managed on demand, and 60+ optional scientific databases that you can connect.
Available now in beta.
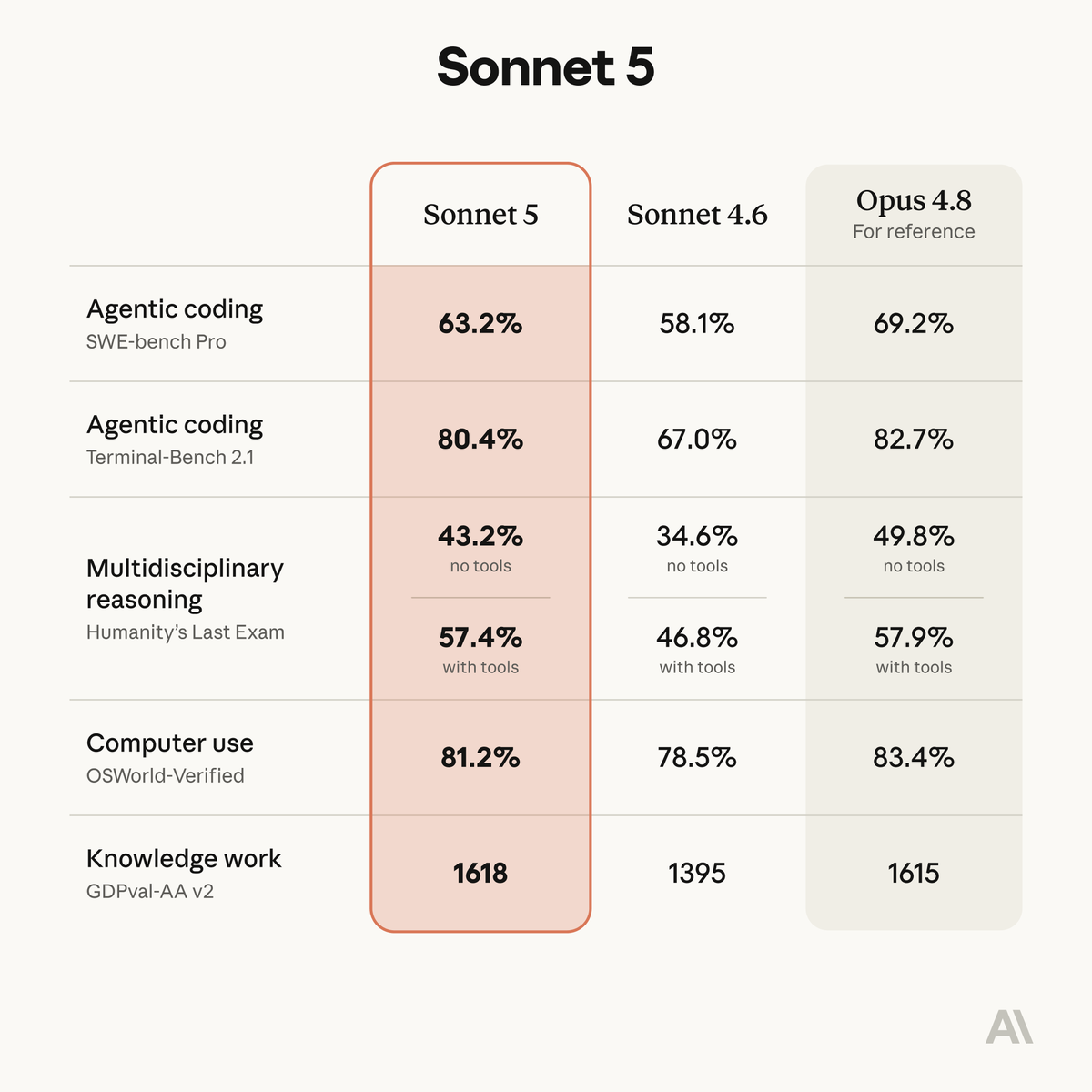
Sonnet 5 is a substantial improvement over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work.
Its performance is close to Opus 4.8, at lower prices.
Introducing Claude Sonnet 5, our most agentic Sonnet yet.
It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
She came back stronger. She came back faster. 🇮🇳
Many congratulations to Jyothi Yarraji on becoming Asia's fastest woman in the 100m hurdles with a gold-winning run of 12.99s at the 65th National Inter-State Senior Athletics Championships.
A remarkable comeback after injury, made even more special by securing qualification for the 20th Asian Games Aichi-Nagoya 2026. The nation is proud and cheering you on!
Prompt engineering & loop engineering, clearly explained!
At its core, an agent is a while loop:
- The model runs
- It requests tool calls
- The tool results return to the context
- The model runs again until it stops requesting tools
ReAct described this form of loop back in 2022-23, and almost every agent/framework runs a similar implementation of this.
So loops aren't a new thing at all, and the above implementation of loops was solved a long time ago.
What wasn't solved is the loop around the above loop, and this is what Boris/Peter talked about recently.
In the most common setup, you are the loop around the loop.
- You write a prompt
- Read the turns the agent runs
- Write the next prompt
- And repeat, catching failures as it runs
Now there are attempts to let the system run the outer loop too, so that you can eliminate yourself.
- It starts on a schedule or an event
- It runs for many turns with no prompt in between
- It decides on its own when it's done
- It comes back only when something needs you
Consider a failing test in CI to understand this.
In the current way, you paste the error into the agent, read the fix, run the tests, and paste the next failure back in until they pass.
So every turn goes through you.
The loop runs those same turns on its own.
It triggers on a schedule, reads the failure, drafts a fix on a branch, runs the tests, and feeds a failure back in as the next turn, until they pass or it hits a turn limit.
A separate reviewer checks the fix, opens a PR if it's clean, and flags it for a human if it isn't.
So the inner loop was always automatic. The part being automated now is your involvement in that loop.
None of that comes for free though, as expected.
> Sitting in the outer loop gave you the flexibility to stop, possess project memory, and be the reviewer. But each of those now has to exist in the system.
> Also, while sitting in the loop was slow, you understood the system.
But one big downside of taking yourself out is that you keep the ownership, but would likely lose the understanding.
> Inherently, a loop doesn't know when to stop on its own either. It will take the agent's word that the work is done and stop on a fix while the tests still fail, so the stop has to be a real check, plus a turn or token cap to avoid infinite loops.
> The context grows every turn, and the model gets worse as its context fills up.
So the loop should trim it and keep summaries instead of full history, move large outputs to files, and split subtasks into separate runs.
> Lastly, the agent can't be the one to check its own work, since it will pass whatever it wrote.
A separate model or a binary/deterministic test should provide that signal.
And the cost for all this adds up fast since every turn sends the whole context again, so a long loop can spend many times what a single prompt would.
If you want to dive deeper, my co-founder wrote a full breakdown, from the loop above to a run that finishes on its own, with the code behind each part.
Read it below.
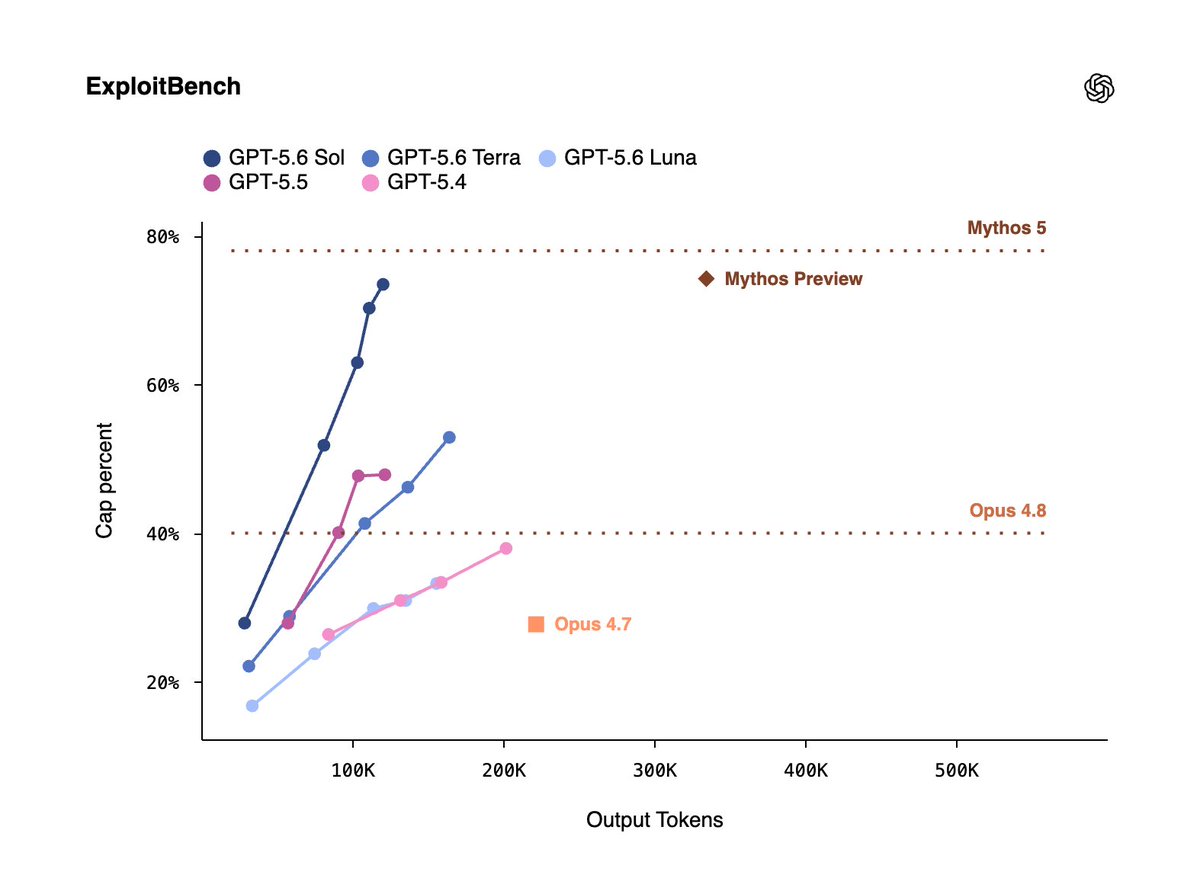
GPT-5.6 Sol is our most capable model yet for cybersecurity.
It shifts the performance-efficiency frontier for long-horizon security tasks including vulnerability research and exploitation.
GPT‑5.6 Sol sets a new state of the art on Terminal‑Bench 2.1, which tests complex command-line workflows requiring planning, iteration, and tool coordination.
Sol is our new flagship and a step function better than GPT-5.5.
Terra delivers performance competitive to GPT-5.5 at 2x lower cost.
Luna is our most cost-efficient model, delivering strong capability at our lowest cost.
Together, the GPT-5.6 family gives people and developers more choice in how they balance intelligence, speed, and cost.
We believe in broad access and plan to make GPT-5.6 Sol, Terra, and Luna generally available in the coming weeks.
For now, at the request of the U.S. government, we’re starting with a limited preview among a small group of trusted partners in Codex and the API.
Introducing a limited preview of GPT-5.6 Sol, our next generation frontier model, as well as GPT-5.6 Terra, a balanced model for efficient, everyday work, and GPT-5.6 Luna, a fast and affordable model for high-volume work.
https://t.co/OoM83SyISN
Andrej Karpathy:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
loop engineering is the exact thing that gets you there.
in a hand-run session you do two things. you decide what the agent runs next, and you check its output before the next step. both are manual, and both are the ceiling on how far the agent gets without you.
loop engineering moves both steps into the system. the diagram below shows the operating structure that surrounds the loop:
→ a trigger decides what to run, whether that's a message, an event, or a schedule, so the agent starts without you there to kick it off.
→ the loop is the maker that produces the work, thinking, acting, and observing until it's done or the brakes stop it.
→ a separate checker grades the output, because a model grading its own work justifies what it already did instead of catching where it failed. the checker's findings return to the maker as the next instruction, and the cycle repeats until nothing is left to fix.
→ state lives on disk, not in context, since the model forgets everything between runs. an MD file or a knowledge graph holds what's done and what's still open, so a loop can pick up again days later.
for that state layer, Zep's Graphiti is a clean open-source option, a temporal knowledge graph that invalidates stale facts and returns context through vector, full-text, and graph search in one call.
repo: https://t.co/8CboBlWffX
two things decide whether an unattended loop holds up.
the exit has to be set before the loop runs, not while it's running. a loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs stack up. a clean exit reads like "all tests pass and lint is clean, stop after two passes."
and the checker only catches failures inside a run. the harness around the loop, the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change. catching that needs observability on every run, not a green checkmark.
Comet's Opik is built for that layer, an open-source tool that traces every call and turns a failing production trace into a regression test so the same break can't recur.
repo: https://t.co/Qxk9BHZBlx
your job stops being the hands inside the loop. it becomes designing the machine that runs without you, then watching the traces closely enough to trust it.
the model is becoming a commodity. the loop around it is where the real engineering lives now.
I wrote the full breakdown. the article is quoted below.
stay tuned for more on this!
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
Winning against the Chinese. In China.
At the Asian Relay Championships.
Srabani, Sudeshna, Sneha & Tamanna in the 4x100 relay.
Power. Speed. Grace. Commitment.
But above all, teamwork.
This clip has it all.
I’m watching it on loop.
More of this please. 🇮🇳
How do you get Claude Code to check its own work before handing it back?
Watch how you can encode your manual checks so Claude closes its own feedback loop:













![AndrewYNg's tweet photo. “Loop engineering” is a hot buzzphrase after mentions of it by Boris Cherny (Claude Code’s creator) and Peter Steinberger (OpenClaw's creator) went viral on social media. Loops are now a key part of how we get AI agents to iterate at length to build software. In this letter, I’d like to share my 3 key loops, shown in the image below, for building 0-to-1 products. These loops guide not just how I build software, but also how I decide what software to build.
Agentic coding loop: Given a product specification and optionally a set of evals (that is, a dataset against which to measure performance), we can have an AI agent write code, test its work, and keep iterating until the code is bug-free and meets its specification. This idea of closing the loop took off around the end of last year, and it has been a game changer in enabling coding agents to work longer productively without human intervention. For example, over the weekend, I was building an app for my daughter to practice typing, and my coding agent could easily work for around an hour, using a web browser to check what it had built multiple times before getting back to me, without needing my intervention.
The engineering loop executes quickly. Every few minutes, the coding agent might build and test a new version of the software. I hear frequently from developers who are finding new ways to engineer more effective engineering loops. This is an active area of invention!
Developer feedback loop: In this loop, a developer examines the current product and steers the coding agent to improve it. Last year, a lot of developers (including me) were acting as the QA (quality assurance) function for our coding agents, manually finding bugs and then asking the agent to fix them. But with coding agents much more able to test their own code, the amount of time we need to spend on this function has decreased significantly. This allows us to make higher-level product decisions, such as what key features to offer, where the UI needs improvement, and so on.
The developer-feedback loop operates over time intervals between tens of minutes and hours — that's how frequently a developer might review a product and give feedback. In the case of the typing app, I changed my mind a few times about the visual design, what cat costumes she can unlock as she learns (she loves cats), and the user flow for a grown-up to log in and steer the child's learning experience.
When a developer has a clear vision for what to build, it is still a lot of work to translate that vision into a specification for a coding agent to implement. Further, after the developer has seen an implementation, they might update (or perhaps clarify) the spec to steer it toward what they want. If you find that the system repeatedly runs into certain problems, building a set of evals for the agent becomes useful.
AI-native teams are increasingly using AI to help shape product direction, for example, automating the gathering and analysis of usage data, summarizing written and verbal customer feedback, or carrying out competitive analysis. However, for pretty much all the products I’m involved in, I see humans as having a significant context advantage over current AI systems — we know a lot more than the AI system about the users and the context the product has to operate in — and thus humans play a critical role. Many people describe this human contribution as “taste,” but I prefer to think of it as humans having a context advantage, since that gives us a clearer path to helping AI systems get better. This also speaks to why this step can’t be automated: So long as the human knows something the AI does not, human-in-the-loop is needed to to inject that knowledge into the system.
External feedback loop: This includes a wide range of tactics like asking a few friends for feedback, launching to alpha testers, or putting the code into production with A/B testing. These tactics are usually slow, rarely taking less than hours and sometimes taking days or even weeks. This data informs the developer vision, which in turn continues to drive the detailed product spec, which in turn drives the coding agent.
With coding agents speeding up software development, more engineers are starting to play a partial product management role. For many engineers who are growing into this role, the hardest part is shaping the product vision and striking a balance between building (bridging the gap between vision and spec) and getting user feedback to evolve the vision. It is important to do both!
I will write more about how to do this in future posts, but for now, I find it encouraging that engineers are playing an expanded role (just as product managers and designers now do more engineering).
[Original text: The Batch]](https://pbs.twimg.com/media/HMEtxp3bsAARJdi.jpg)