Empirically, we train Transformers to recognize binary addition. With extra supervision, they reach seemingly perfect train and validation accuracy, but some are not perfect. Rare test errors exist, and too few random samples can miss them.
Link: https://t.co/vvDlExtOyn
New paper out! 🎉
In reasoning and algorithmic settings, a trained model can reach high accuracy and still fail to implement the target behavior on a small set of inputs.
So we ask: how many labeled examples does it take to certify that the model computes the target function?
We also show analogous results in circuit classes.
The proofs show that the slightly larger hypothesis class contains many alternatives that disagree with the target on different parts of the domain.
Hardness also persists even if certification is allowed poly many mistakes.
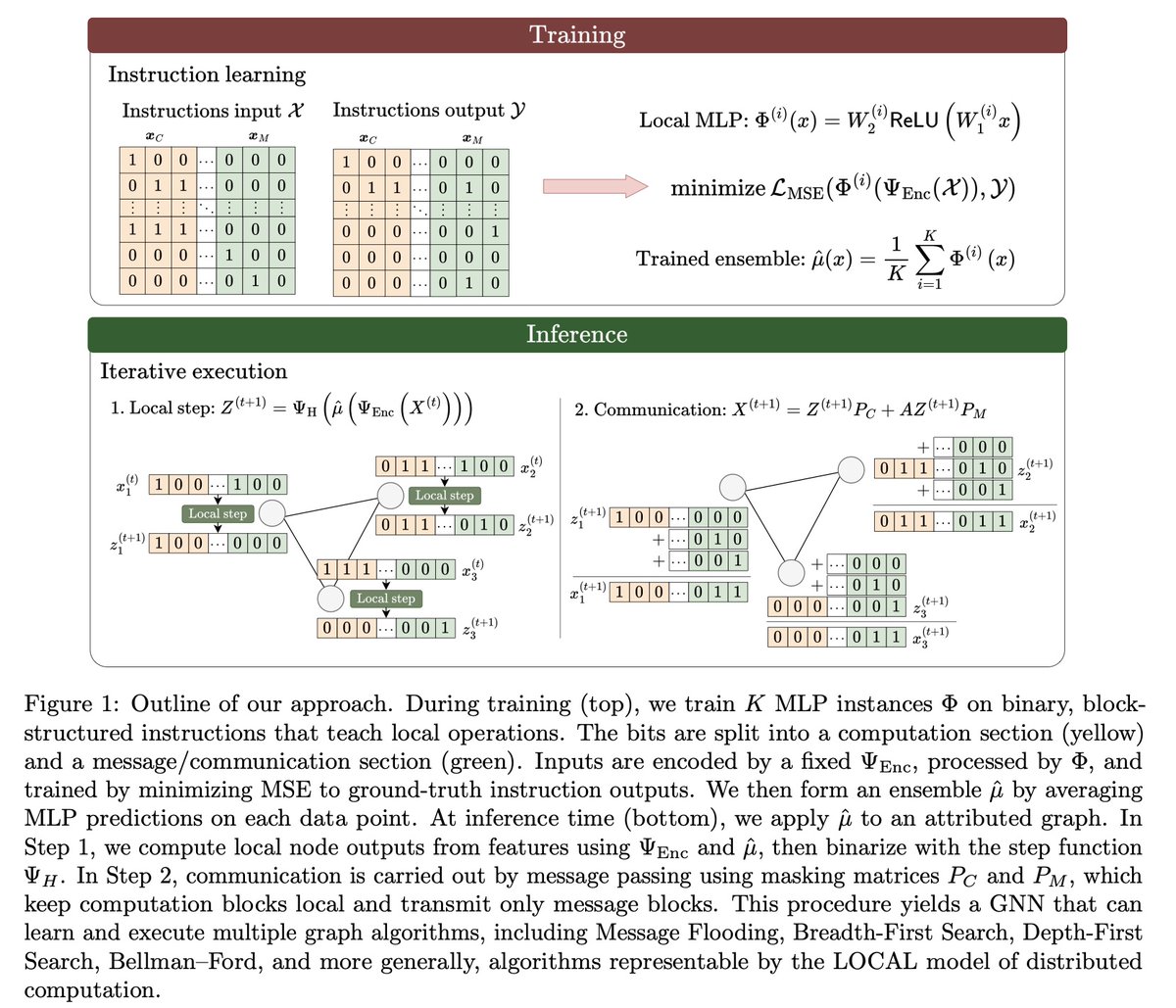
Likely my last paper on GNNs: “Learning to Execute Graph Algorithms Exactly with Graph Neural Networks”
It has been a few years since @PetarV_93 popularized the idea of neural algorithmic reasoning, which, focused on GNNs, is essentially about the ability of neural networks to learn to execute graph algorithms. In this paper, we provide a first exact learnability result for this idea (after training with gradient descent). In particular, assuming bounded degree and finite precision, we show positive exact learnability results for graph algorithms implemented in the LOCAL model, such as flooding, breadth-first search, depth-first search, and Bellman–Ford.
A few details:
We train on local instructions: binary vectors describing a single node’s local update and message. We train an ensemble of MLPs on these instructions and then reuse the learned MLP as the shared update rule in message passing. Essentially, we convert an algorithm into data and then overfit to this data, which guarantees correct execution for any input, up to bounded-degree and finite-precision limitations.
Using NTK theory, we show a small instruction dataset can be learned exactly. Averaging independently initialized MLPs concentrates around the NTK predictor; after thresholding, the learned local rule matches the true rule with arbitrarily high probability.
Guarantees (informal): any LOCAL-model algorithm running L rounds on max-degree D graphs (bounded state+message memory) can be simulated by a GNN in O(L) iterations. We also give concrete bounds for Message Flooding, BFS, DFS, and Bellman–Ford (data size/width/ensemble sizes).
Limitations: bounded degree, finite-precision IDs, and an NTK/infinite-width analysis (ensembles can be large).
Wow, what an honour @CsabaSzepesvari, thanks!
"Math of Reasoning in LLMs, Session 11: Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks"
https://t.co/lkQ0PrXRLK
I watched all of it, and I really enjoyed it.
Something you didn’t know you needed: Neural DOOM 🧨!!
1. The backend is simulated by a neural net.
2. Rendering is external (pygame) with a retro Doom-like software renderer.
The neural net is a 2-layer MLP with 3787 neurons but very sparse, hardcoded by GPT-5.3 codex. Link to the repository in the post below.
P.S.: Inspired by the posts of D. Papailiopoulos. I had this idea after two of my papers (parts of them also inspired by Papailiopoulos), but Dimitris’s posts reminded me of them!
@DimitrisPapail Cool idea @DimitrisPapail! The pairwise tokenization idea in Codex seems closely related to classic automata-theory constructions (slides 14–15)
https://t.co/4ekXHA3Ijb
.@backdeluca is one of the four students who received the Cheriton Scholarship for Fall 2025. I would like to thank the committee for recognizing Artur's hard work and supporting him.
One of the best parts of NeurIPS was meeting people doing cool work. Really enjoyed meeting with @hpapazov_ai and @dngfra and hearing about what they've been working on
Finally a new paper that is actually exciting to me. It’s almost as if it was written from my own thoughts. I will dig in deeper and do a proper review of it.
Recommended to me by @backdeluca.
I am always grateful for support for my students. It makes them happier, boosts their confidence, and gives them a sense of satisfaction to see their work recognized. @backdeluca got the Layer 6 - TD Graduate Scholarship in Data and AI: https://t.co/5CqnjBjM4Q.
Omw to California for #NeurIPS2025 next week! I'll be presenting our work on how neural networks can learn from instructions and execute binary algorithms. Feel free to reach out!
.@ggiapitz is currently looking for CS Theory PhD positions!
He was the valedictorian (CGPA 9.93/10, 2023) at the School of Mathematics in Athens, and has published three theoretical papers and one workshop paper under my supervision as a master’s student (ICML 2025, NeurIPS 2025, HiLD at ICML 2025, and one recently posted on arXiv).
Feel free to contact him at ggiapitz (at) uwaterloo (dot) ca
Personal website: https://t.co/uiGAblaOQf
Papers:
1. On the Statistical Query Complexity of Learning Semiautomata: a Random Walk Approach (link: https://t.co/LB29Uyy337) just made public.
2. Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks (link: https://t.co/J5j4QVbS4c), accepted at NeurIPS 2025.
3. Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity, accepted at the 3rd Workshop on High-Dimensional Learning Dynamics (HiLD) at ICML 2025.
4. Positional Attention: Expressivity and Learnability of Algorithmic Computation (link: https://t.co/pMENBO8dF1) accepted at ICML 2025.
Other highlights
1. Onassis Foundation Scholarship
2. David R. Cheriton Graduate Scholarship
3. International Master’s Award of Excellence scholarship
4. CGPA of 98.75/100 at Waterloo
5. ETH Zurich’s Student Summer Research Fellowship, 2025.
6. 1st in Greece, 3rd in Europe, and 19th worldwide in IEEEXtreme 12.0
7. A Bloomberg CodeCon finalist
8. Top-ten placement at the Greek IOI selection camps.
First position paper I ever wrote. "Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence" https://t.co/aQaKGGSNt6 Background: I'd like LLMs to help me do math, but statistical learning seems inadequate to make this happen. What do you all think?