At ICML 2024, we introduced the first scaling laws for adversarial training, improving the *train-time compute* for robustness tradeoff (https://t.co/4Es87BEgDm).
At ICLR 2026, we show how to trade *test-time compute* for robustness efficiently.
https://t.co/4KK0bOU4Hm
Give an LLM a spec: more reasoning ➡️ better spec satisfaction. Even on adversarially attacked data.
But reasoning benefits fade if attacks are stronger (e.g. white-box or multimodal).
Our hypothesis suggests reasoning can stop such attacks.
Toy example in the video. 🧵
Recordings and the full recap from the Assurance and Verification of AI Development (AViD) Workshop are live. We co-hosted with @ai_risks on May 17, colocated with IEEE S&P. The question: how do you generate trustworthy evidence about an AI system without unrestricted access to weights or infrastructure? 1/6
@saprmarks Very interesting, thanks for sharing these! It seems like a lot of recent robustness/alignment works are leveraging pretraining interventions -- another one: our ICLR 2026 paper finds that specs can stop white box attacks if the right training set is used https://t.co/4KK0bOU4Hm
Give an LLM a spec: more reasoning ➡️ better spec satisfaction. Even on adversarially attacked data.
But reasoning benefits fade if attacks are stronger (e.g. white-box or multimodal).
Our hypothesis suggests reasoning can stop such attacks.
Toy example in the video. 🧵
@amolk@sumeetrm Depending on your definition of harness, I think this is close to (if not exactly) what we have. Our "restricted harness" setting allows RLMs to perform operations on the context variable, make sub-LLM calls, etc., but disallows directly coding a solution.
@amolk@sumeetrm I like this suggestion.
A potential issue: an LLM can code up a domain-specific symbolic algorithm using only general purpose tools in a REPL.
For example, I applied an RLM to a LongCoT chess problem, and it coded then ran a chessboard simulator.
https://t.co/lJzSnqyCC0
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows.
```
board = ChessBoard()
for i, move in enumerate(moves):
board.make_move(move)
...
solution = board_to_fen(board)
```
You can obtain setting (2) by altering DSPy's RLM prompt to discourage such reasoning offloading. Even in this harder setting, I suspect RLMs can be successful (and training to decompose tasks may be critical here).
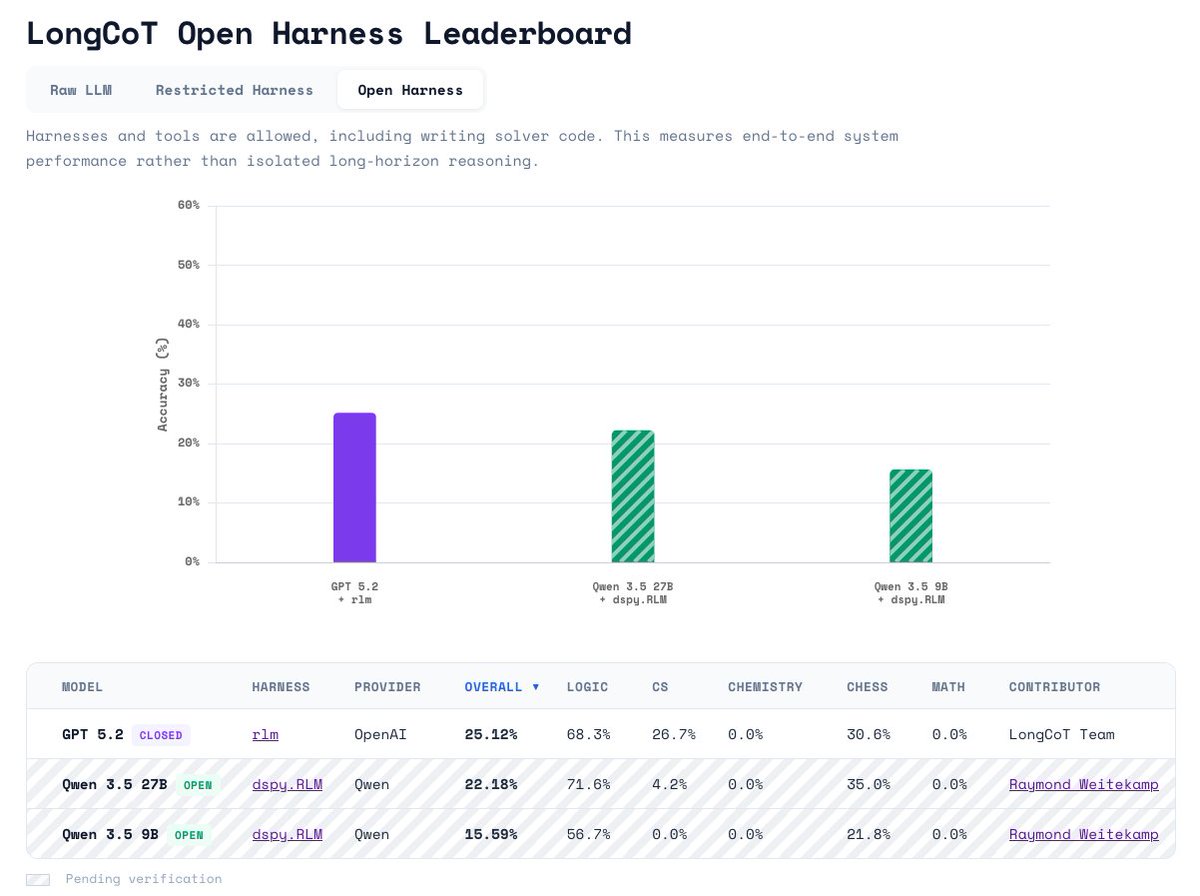
LongCoT is adding two new leaderboards! Due to the interest in agents (particularly RLMs), we’re adding a “Restricted Harness” and an “Open Harness” leaderboard.
GPT 5.2 RLM from our paper is SOTA on “Open Harness” at 25.12%. We expect tool-use SOTA to exceed this very soon!
On “Open Harness”, we allow all tool-use and code execution. On “Restricted Harness”, models may manage context, call subagents, etc, but may not write specific solver code (e.g. writing a BlocksWorld or Sudoku solver). We’re particularly excited about this leaderboard, as it allows agents to do their own context management, while sticking to LongCoT’s goal of testing models’ intrinsic reasoning capabilities.
Finally, we note that LongCoT has two splits: LongCoT-mini (for fast open source research) and LongCoT (for frontier models).
While some problems are naturally solvable by symbolic programs (e.g. some chess problems) and require many CoT reasoning steps, others are great tests for decomposition and maintaining important variables across steps (like mathematics and chemistry, which have composed, interdependent sub-problems). We suspect RLMs may be highly effective for all problem types.
However, beyond just writing code, RLMs can decompose hard problems into simpler ones, and have the LLM perform intermediate reasoning steps. And this behavior is aligned with what we set out to test with LongCoT.
Indeed, in the LongCoT paper, we show a second setting where we verbally ask an RLM (by modifying its system prompt) to avoid solving the problem primarily symbolically, saying it must instead only use code for problem decomposition. As Figure 7 shows, this restriction led to a drop from the 25.1% performance observed with a default RLM.
There are likely better strategies than our prompt approach for keeping RLMs comparable to no-tools baselines, and we welcome innovation from the community here.
So, if you want to compare RLMs to no-tools baselines, we suggest ensuring that RLMs are performing this sort of reasoning assistance, rather than just writing a Python code (to symbolically solve some problems) that makes it unnecessary for LLMs to reason through the steps of a problem.
Concrete tips:
- Look at performance across domains. If chess performance is 80% and chemistry performance is near 0%, the RLM might be writing Python code to simulate chess moves rather than reasoning through the game states as a no-tools baseline does. Such simulations may be harder to code for LongCoT chemistry and mathematics questions.
- Given an LLM, when you see its RLM version boost performance, check the code executed by the RLM. Was the RLM decomposing the problem into simpler ones then providing these to the sub-LLM (this is okay!), or did it write code or import a library that solves the problem directly (LLMs w/out tools can’t do this so it won’t be a fair comparison)?
Accordingly, tomorrow, we will begin tracking tool-enabled performance on a separate leaderboard at https://t.co/nRFWLVKhp1. Note that we expect this to be saturated much faster than the base leaderboard that doesn’t allow tools.
The attention on LongCoT is great! It's far from solved (GPT 5.2 w/out tools gets 9.8%).
Out-of-the-box, a GPT 5.2 RLM gets 25% (see Figure 7). Better prompting/training should push RLMs past this.
Comparing RLMs to no-tool baselines? See our 🧵of tips
https://t.co/nqBocmIr9Z
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens.
LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵
RLMs can aid this LLM-based simulation (very well in theory), but (due to REPL access) they can also just write Python code that solves certain problems symbolically (without any LLM ever seeing intermediate reasoning steps).
https://t.co/66gmLhqEV7
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows.
```
board = ChessBoard()
for i, move in enumerate(moves):
board.make_move(move)
...
solution = board_to_fen(board)
```
You can obtain setting (2) by altering DSPy's RLM prompt to discourage such reasoning offloading. Even in this harder setting, I suspect RLMs can be successful (and training to decompose tasks may be critical here).
First, some background:
The LongCoT paper outlines that, in our primary evaluations, tool use is not allowed. Our main goal is to test whether models can reason through complex problems directly in their chain of thought. If a problem requires simulating the evolution of a chessboard state (e.g.), the LLM must do that in its CoT.
@GabLesperance@dosco We want to avoid a particular kind of offloading. LongCoT evaluates models w/out Python use, but RLMs require Python. For a fair comparison, we prompt the RLM to not just code a solution.
Otherwise, RLMs "offload" reasoning to code. E.g., see below
https://t.co/66gmLhqEV7
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows.
```
board = ChessBoard()
for i, move in enumerate(moves):
board.make_move(move)
...
solution = board_to_fen(board)
```
You can obtain setting (2) by altering DSPy's RLM prompt to discourage such reasoning offloading. Even in this harder setting, I suspect RLMs can be successful (and training to decompose tasks may be critical here).
Exactly -- we evaluated untrained RLMs on LongCoT and think training to decompose tasks would boost performance.
Two eval settings to consider:
(1) Python may be used to avoid reasoning (dotted bars)
(2) LLM/RLM does all the reasoning (solid bars)
https://t.co/g0Qi43KiuZ
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows.
```
board = ChessBoard()
for i, move in enumerate(moves):
board.make_move(move)
...
solution = board_to_fen(board)
```
You can obtain setting (2) by altering DSPy's RLM prompt to discourage such reasoning offloading. Even in this harder setting, I suspect RLMs can be successful (and training to decompose tasks may be critical here).
We found this offloading seems to happen less on some domains, like chemistry and math, which appear harder to offload to code. This is consistent with the similarity between the solid and dashed bars in the plot above.
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows.
```
board = ChessBoard()
for i, move in enumerate(moves):
board.make_move(move)
...
solution = board_to_fen(board)
```
You can obtain setting (2) by altering DSPy's RLM prompt to discourage such reasoning offloading. Even in this harder setting, I suspect RLMs can be successful (and training to decompose tasks may be critical here).
We already do RLM evals on LongCoT (although our benchmark is intended for just models, not scaffolds). Your results in the main post are different from what you have in your comments and are with LongCoT-mini (https://t.co/V6X8Dyr9kX).
We're very excited about RLMs as a direction and are interested in seeing performance go up on our explicit horizon domains (Math/Chemistry/Computer Science).
what stands out to me from a research perspective is that LongCoT isolates compositional horizon failure rather than just benchmark hardness...the local steps are often tractable but performance collapses when those steps must be coordinated across long dependency graphs with planning, state maintenance and backtracking. i think that makes it much more scientifically valuable than another “hard reasoning” benchmark bcoz it cleanly exposes the gap between step-level competence and trajectory-level reasoning robustness.